多模態 API
「所有自然相關的事物都應該結合起來教導」- 約翰·阿摩司·康米紐斯,《世界圖解》(Orbis Sensualium Pictus),1658 年
人類同時透過多種資料輸入模式來處理知識。我們的學習方式和經驗都是多模態的。我們不只有視覺、聽覺和文字。
與這些原則相反,機器學習通常專注於為處理單一模態而客製化的專用模型。例如,我們開發了音訊模型來處理文字轉語音或語音轉文字等任務,以及電腦視覺模型來處理物件偵測和分類等任務。
然而,新一波多模態大型語言模型開始出現。例如,OpenAI 的 GPT-4o、Google 的 Vertex AI Gemini 1.5、Anthropic 的 Claude3 以及開源產品 Llama3.2、LLaVA 和 Balklava 能夠接受多種輸入,包括文字、圖像、音訊和視訊,並透過整合這些輸入來產生文字回應。
| 多模態大型語言模型 (LLM) 功能使模型能夠處理和產生文字,並結合其他模態,例如圖像、音訊或視訊。 |
Spring AI 多模態
多模態指的是模型同時理解和處理來自各種來源資訊的能力,包括文字、圖像、音訊和其他資料格式。
Spring AI Message API 提供了支援多模態 LLM 的所有必要抽象概念。
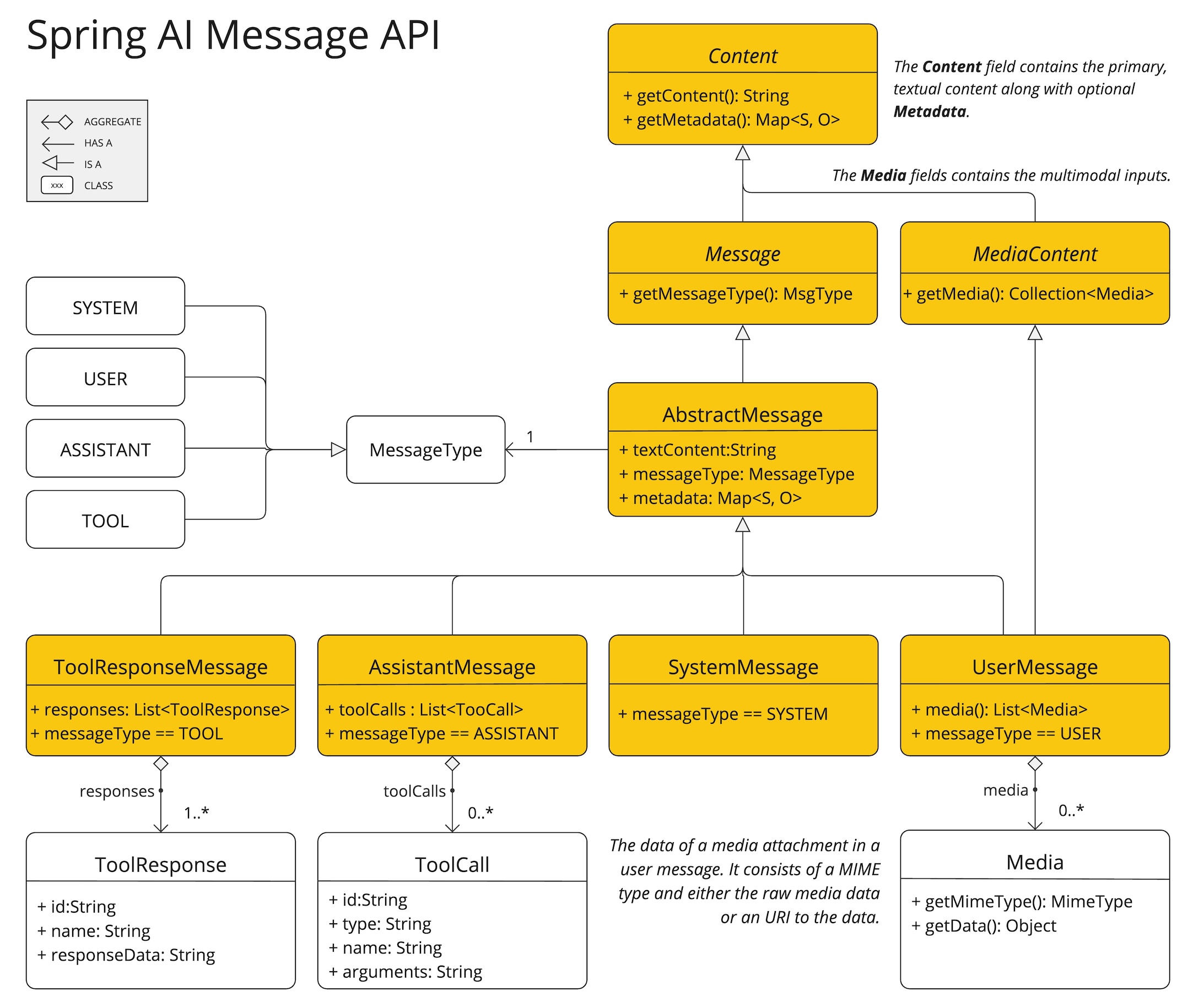
UserMessage 的 content 欄位主要用於文字輸入,而選用的 media 欄位允許新增一或多個不同模態的額外內容,例如圖像、音訊和視訊。MimeType 指定了模態類型。根據使用的 LLM,Media 資料欄位可以是原始媒體內容(作為 Resource 物件)或是內容的 URI。
媒體欄位目前僅適用於使用者輸入訊息(例如,UserMessage)。它對於系統訊息沒有意義。包含 LLM 回應的 AssistantMessage 僅提供文字內容。若要產生非文字媒體輸出,您應該使用專用的單一模態模型。 |
例如,我們可以採用以下圖片 (multimodal.test.png) 作為輸入,並要求 LLM 解釋它所看到的內容。

對於大多數多模態 LLM,Spring AI 程式碼看起來會像這樣
var imageResource = new ClassPathResource("/multimodal.test.png");
var userMessage = new UserMessage(
"Explain what do you see in this picture?", // content
new Media(MimeTypeUtils.IMAGE_PNG, this.imageResource)); // media
ChatResponse response = chatModel.call(new Prompt(this.userMessage));或使用流暢的 ChatClient API
String response = ChatClient.create(chatModel).prompt()
.user(u -> u.text("Explain what do you see on this picture?")
.media(MimeTypeUtils.IMAGE_PNG, new ClassPathResource("/multimodal.test.png")))
.call()
.content();並產生類似以下的回應
這是一張設計簡約的水果碗圖片。碗是由金屬製成,彎曲的線條邊緣形成開放式結構,讓水果可以從各個角度看見。碗內有兩根黃色香蕉,放在一個看起來像是紅蘋果的東西上面。香蕉有點過熟,從果皮上的棕色斑點可以看出。碗的頂部有一個金屬環,可能是作為提手的用途。碗放在一個平面上,背景顏色中性,可以清楚地看到裡面的水果。
Spring AI 為以下聊天模型提供多模態支援

