ETL 管線
萃取、轉換和載入 (ETL) 框架是檢索增強生成 (RAG) 用例中資料處理的骨幹。
ETL 管道協調從原始資料來源到結構化向量儲存庫的流程,確保資料處於 AI 模型檢索的最佳格式。
RAG 用例是透過從資料體中檢索相關資訊來增強生成模型的能力,從而提高生成輸出的品質和相關性。
API 總覽
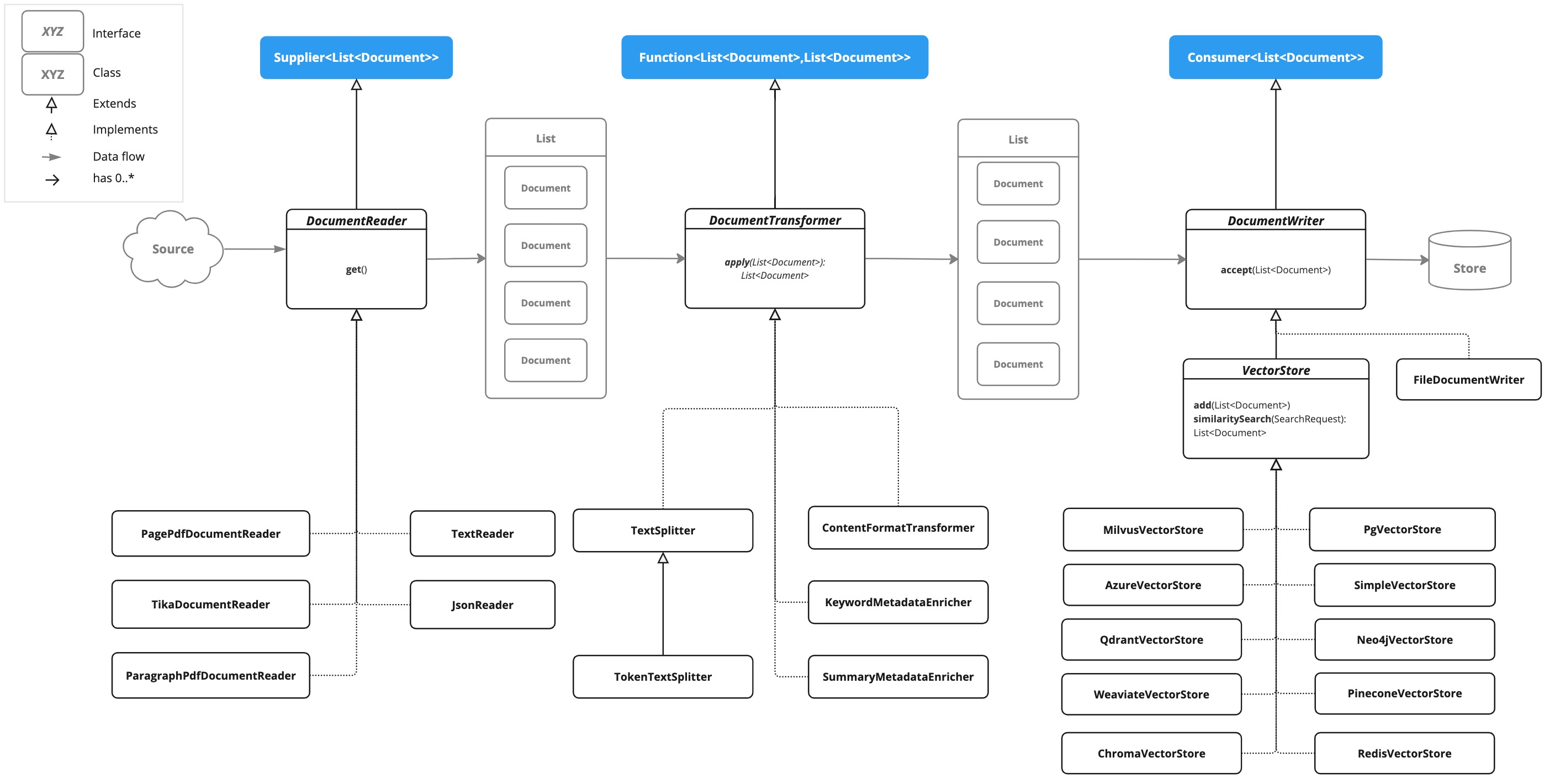
ETL 管道建立、轉換和儲存 Document 實例。
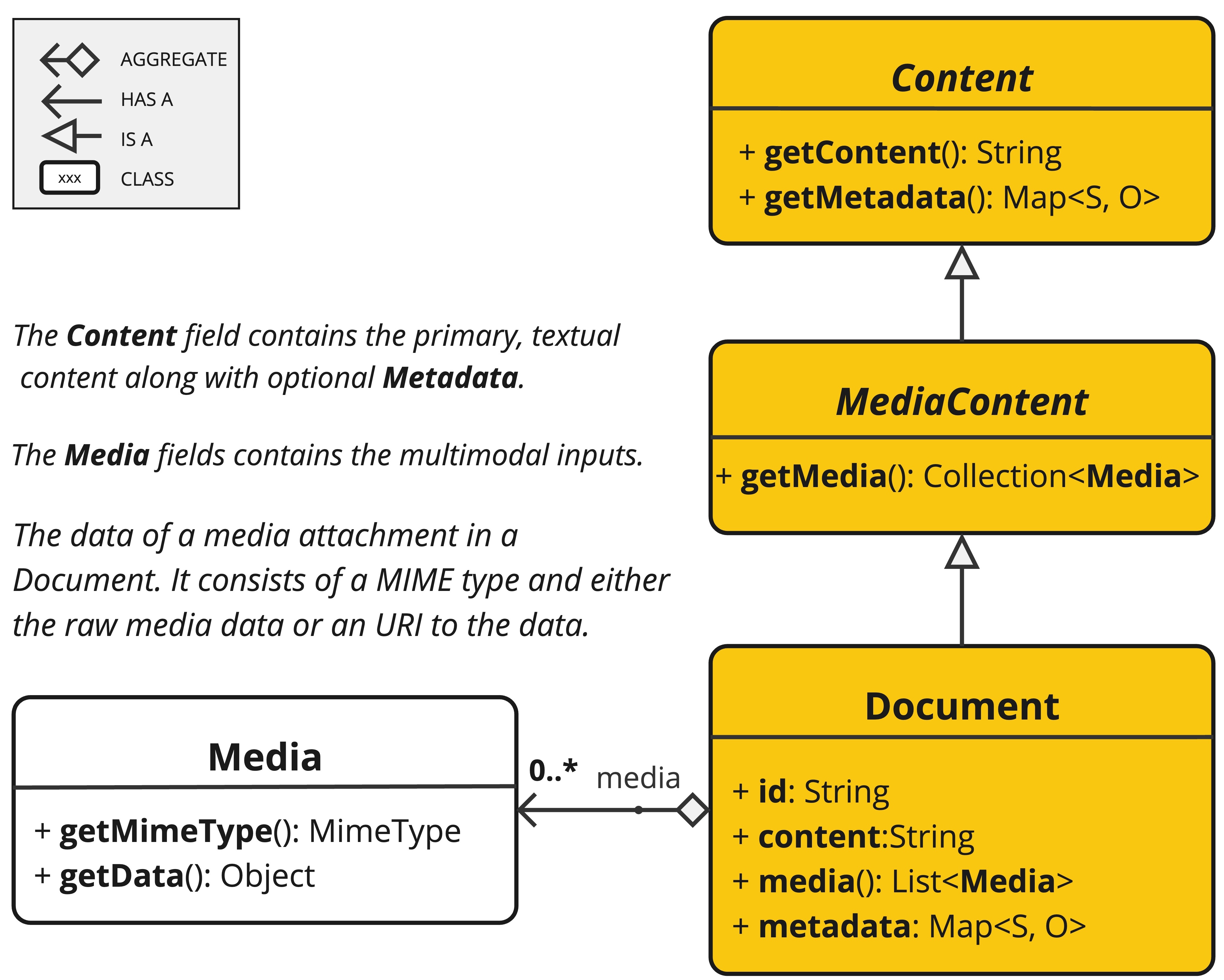
Document 類別包含文字、中繼資料以及可選的其他媒體類型,如圖像、音訊和影片。
ETL 管道有三個主要組件:
-
DocumentReader實作Supplier<List<Document>> -
DocumentTransformer實作Function<List<Document>, List<Document>> -
DocumentWriter實作Consumer<List<Document>>
Document 類別的內容是透過 DocumentReader 從 PDF、文字檔案和其他文件類型建立的。
要建構一個簡單的 ETL 管道,您可以將每種類型的實例串聯在一起。

假設我們有以下三種 ETL 類型的實例
-
PagePdfDocumentReader是DocumentReader的實作 -
TokenTextSplitter是DocumentTransformer的實作 -
VectorStore是DocumentWriter的實作
若要執行將資料載入向量資料庫以用於檢索增強生成模式的基本操作,請使用以下 Java 函數樣式語法程式碼。
vectorStore.accept(tokenTextSplitter.apply(pdfReader.get()));或者,您可以使用更自然地表達領域的方法名稱
vectorStore.write(tokenTextSplitter.split(pdfReader.read()));ETL 介面
ETL 管道由以下介面和實作組成。詳細的 ETL 類別圖顯示在 ETL 類別圖 章節中。
DocumentReader
提供來自不同來源的文件來源。
public interface DocumentReader extends Supplier<List<Document>> {
default List<Document> read() {
return get();
}
}DocumentTransformer
在處理工作流程中轉換一批文件。
public interface DocumentTransformer extends Function<List<Document>, List<Document>> {
default List<Document> transform(List<Document> transform) {
return apply(transform);
}
}
DocumentReaders
JSON
JsonReader 處理 JSON 文件,將其轉換為 Document 物件的列表。
範例
@Component
class MyJsonReader {
private final Resource resource;
MyJsonReader(@Value("classpath:bikes.json") Resource resource) {
this.resource = resource;
}
List<Document> loadJsonAsDocuments() {
JsonReader jsonReader = new JsonReader(this.resource, "description", "content");
return jsonReader.get();
}
}建構子選項
JsonReader 提供多個建構子選項
-
JsonReader(Resource resource) -
JsonReader(Resource resource, String… jsonKeysToUse) -
JsonReader(Resource resource, JsonMetadataGenerator jsonMetadataGenerator, String… jsonKeysToUse)
參數
-
resource:指向 JSON 檔案的 SpringResource物件。 -
jsonKeysToUse:JSON 中的鍵陣列,應用作結果Document物件中的文字內容。 -
jsonMetadataGenerator:一個可選的JsonMetadataGenerator,用於為每個Document建立中繼資料。
行為
JsonReader 處理 JSON 內容的方式如下
-
它可以處理 JSON 陣列和單個 JSON 物件。
-
對於每個 JSON 物件(無論是在陣列中還是單個物件中)
-
它根據指定的
jsonKeysToUse提取內容。 -
如果未指定任何鍵,它將使用整個 JSON 物件作為內容。
-
它使用提供的
JsonMetadataGenerator(如果未提供,則使用空的)產生中繼資料。 -
它使用提取的內容和中繼資料建立
Document物件。
-
使用 JSON 指標
JsonReader 現在支援使用 JSON 指標檢索 JSON 文件的特定部分。此功能可讓您輕鬆地從複雜的 JSON 結構中提取巢狀資料。
範例 JSON 結構
[
{
"id": 1,
"brand": "Trek",
"description": "A high-performance mountain bike for trail riding."
},
{
"id": 2,
"brand": "Cannondale",
"description": "An aerodynamic road bike for racing enthusiasts."
}
]在此範例中,如果 JsonReader 配置為使用 "description" 作為 jsonKeysToUse,它將建立 Document 物件,其中內容是陣列中每輛自行車的 "description" 欄位的值。
文字
TextReader 處理純文字文件,將其轉換為 Document 物件的列表。
範例
@Component
class MyTextReader {
private final Resource resource;
MyTextReader(@Value("classpath:text-source.txt") Resource resource) {
this.resource = resource;
}
List<Document> loadText() {
TextReader textReader = new TextReader(this.resource);
textReader.getCustomMetadata().put("filename", "text-source.txt");
return textReader.read();
}
}配置
-
setCharset(Charset charset):設定用於讀取文字檔案的字元集。預設為 UTF-8。 -
getCustomMetadata():傳回可變地圖,您可以在其中為文件新增自訂中繼資料。
行為
TextReader 處理文字內容的方式如下
-
它將文字檔案的整個內容讀取到單個
Document物件中。 -
檔案的內容成為
Document的內容。 -
中繼資料會自動新增到
Document-
charset:用於讀取檔案的字元集(預設值:"UTF-8")。 -
source:來源文字檔案的檔案名稱。
-
-
透過
getCustomMetadata()新增的任何自訂中繼資料都包含在Document中。
注意事項
-
TextReader將整個檔案內容讀取到記憶體中,因此可能不適合非常大的檔案。 -
如果您需要將文字分割成較小的區塊,您可以在讀取文件後使用文字分割器,例如
TokenTextSplitter
List<Document> documents = textReader.get();
List<Document> splitDocuments = new TokenTextSplitter().apply(this.documents);-
讀取器使用 Spring 的
Resource抽象,允許它從各種來源(類別路徑、檔案系統、URL 等)讀取。 -
可以使用
getCustomMetadata()方法將自訂中繼資料新增到讀取器建立的所有文件中。
Markdown
MarkdownDocumentReader 處理 Markdown 文件,將其轉換為 Document 物件的列表。
範例
@Component
class MyMarkdownReader {
private final Resource resource;
MyMarkdownReader(@Value("classpath:code.md") Resource resource) {
this.resource = resource;
}
List<Document> loadMarkdown() {
MarkdownDocumentReaderConfig config = MarkdownDocumentReaderConfig.builder()
.withHorizontalRuleCreateDocument(true)
.withIncludeCodeBlock(false)
.withIncludeBlockquote(false)
.withAdditionalMetadata("filename", "code.md")
.build();
MarkdownDocumentReader reader = new MarkdownDocumentReader(this.resource, config);
return reader.get();
}
}MarkdownDocumentReaderConfig 可讓您自訂 MarkdownDocumentReader 的行為
-
horizontalRuleCreateDocument:設定為true時,Markdown 中的水平線將建立新的Document物件。 -
includeCodeBlock:設定為true時,程式碼區塊將包含在與周圍文字相同的Document中。設定為false時,程式碼區塊會建立單獨的Document物件。 -
includeBlockquote:設定為true時,引文區塊將包含在與周圍文字相同的Document中。設定為false時,引文區塊會建立單獨的Document物件。 -
additionalMetadata:可讓您將自訂中繼資料新增到所有建立的Document物件。
範例文件:code.md
This is a Java sample application:
```java
package com.example.demo;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication
public class DemoApplication {
public static void main(String[] args) {
SpringApplication.run(DemoApplication.class, args);
}
}
```
Markdown also provides the possibility to `use inline code formatting throughout` the entire sentence.
---
Another possibility is to set block code without specific highlighting:
```
./mvnw spring-javaformat:apply
```行為:MarkdownDocumentReader 處理 Markdown 內容並根據配置建立 Document 物件
-
標題成為 Document 物件中的中繼資料。
-
段落成為 Document 物件的內容。
-
程式碼區塊可以分隔到它們自己的 Document 物件中,或與周圍文字一起包含。
-
引文區塊可以分隔到它們自己的 Document 物件中,或與周圍文字一起包含。
-
水平線可用於將內容分割成單獨的 Document 物件。
讀取器保留 Document 物件內容中的格式,例如行內程式碼、列表和文字樣式。
PDF 頁面
PagePdfDocumentReader 使用 Apache PdfBox 庫解析 PDF 文件
使用 Maven 或 Gradle 將依賴項新增到您的專案。
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-pdf-document-reader</artifactId>
</dependency>或新增到您的 Gradle build.gradle 建置檔案。
dependencies {
implementation 'org.springframework.ai:spring-ai-pdf-document-reader'
}範例
@Component
public class MyPagePdfDocumentReader {
List<Document> getDocsFromPdf() {
PagePdfDocumentReader pdfReader = new PagePdfDocumentReader("classpath:/sample1.pdf",
PdfDocumentReaderConfig.builder()
.withPageTopMargin(0)
.withPageExtractedTextFormatter(ExtractedTextFormatter.builder()
.withNumberOfTopTextLinesToDelete(0)
.build())
.withPagesPerDocument(1)
.build());
return pdfReader.read();
}
}PDF 段落
ParagraphPdfDocumentReader 使用 PDF 目錄(例如 TOC)資訊將輸入 PDF 分割成文字段落,並為每個段落輸出一個 Document。注意:並非所有 PDF 文件都包含 PDF 目錄。
依賴項
使用 Maven 或 Gradle 將依賴項新增到您的專案。
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-pdf-document-reader</artifactId>
</dependency>或新增到您的 Gradle build.gradle 建置檔案。
dependencies {
implementation 'org.springframework.ai:spring-ai-pdf-document-reader'
}範例
@Component
public class MyPagePdfDocumentReader {
List<Document> getDocsFromPdfWithCatalog() {
ParagraphPdfDocumentReader pdfReader = new ParagraphPdfDocumentReader("classpath:/sample1.pdf",
PdfDocumentReaderConfig.builder()
.withPageTopMargin(0)
.withPageExtractedTextFormatter(ExtractedTextFormatter.builder()
.withNumberOfTopTextLinesToDelete(0)
.build())
.withPagesPerDocument(1)
.build());
return pdfReader.read();
}
}Tika (DOCX, PPTX, HTML…)
TikaDocumentReader 使用 Apache Tika 從各種文件格式(例如 PDF、DOC/DOCX、PPT/PPTX 和 HTML)中提取文字。如需支援格式的完整列表,請參閱 Tika 文件。
依賴項
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-tika-document-reader</artifactId>
</dependency>或新增到您的 Gradle build.gradle 建置檔案。
dependencies {
implementation 'org.springframework.ai:spring-ai-tika-document-reader'
}範例
@Component
class MyTikaDocumentReader {
private final Resource resource;
MyTikaDocumentReader(@Value("classpath:/word-sample.docx")
Resource resource) {
this.resource = resource;
}
List<Document> loadText() {
TikaDocumentReader tikaDocumentReader = new TikaDocumentReader(this.resource);
return tikaDocumentReader.read();
}
}轉換器
TokenTextSplitter
TokenTextSplitter 是 TextSplitter 的實作,它使用 CL100K_BASE 編碼根據權杖計數將文字分割成區塊。
用法
@Component
class MyTokenTextSplitter {
public List<Document> splitDocuments(List<Document> documents) {
TokenTextSplitter splitter = new TokenTextSplitter();
return splitter.apply(documents);
}
public List<Document> splitCustomized(List<Document> documents) {
TokenTextSplitter splitter = new TokenTextSplitter(1000, 400, 10, 5000, true);
return splitter.apply(documents);
}
}建構子選項
TokenTextSplitter 提供兩個建構子選項
-
TokenTextSplitter():使用預設設定建立分割器。 -
TokenTextSplitter(int defaultChunkSize, int minChunkSizeChars, int minChunkLengthToEmbed, int maxNumChunks, boolean keepSeparator)
參數
-
defaultChunkSize:每個文字區塊的目標大小(以權杖為單位)(預設值:800)。 -
minChunkSizeChars:每個文字區塊的最小大小(以字元為單位)(預設值:350)。 -
minChunkLengthToEmbed:要包含的區塊的最小長度(預設值:5)。 -
maxNumChunks:從文字產生的最大區塊數(預設值:10000)。 -
keepSeparator:是否在區塊中保留分隔符(例如換行符)(預設值:true)。
行為
TokenTextSplitter 處理文字內容的方式如下
-
它使用 CL100K_BASE 編碼將輸入文字編碼為權杖。
-
它根據
defaultChunkSize將編碼的文字分割成區塊。 -
對於每個區塊
-
它將區塊解碼回文字。
-
它嘗試在
minChunkSizeChars之後找到合適的斷點(句號、問號、驚嘆號或換行符)。 -
如果找到斷點,它會在該點截斷區塊。
-
它會修剪區塊,並根據
keepSeparator設定選擇性地移除換行符。 -
如果結果區塊長度超過
minChunkLengthToEmbed,則會將其新增到輸出。
-
-
此過程會持續到處理完所有權杖或達到
maxNumChunks為止。 -
如果任何剩餘文字長度超過
minChunkLengthToEmbed,則會將其作為最終區塊新增。
範例
Document doc1 = new Document("This is a long piece of text that needs to be split into smaller chunks for processing.",
Map.of("source", "example.txt"));
Document doc2 = new Document("Another document with content that will be split based on token count.",
Map.of("source", "example2.txt"));
TokenTextSplitter splitter = new TokenTextSplitter();
List<Document> splitDocuments = this.splitter.apply(List.of(this.doc1, this.doc2));
for (Document doc : splitDocuments) {
System.out.println("Chunk: " + doc.getContent());
System.out.println("Metadata: " + doc.getMetadata());
}KeywordMetadataEnricher
KeywordMetadataEnricher 是一個 DocumentTransformer,它使用生成式 AI 模型從文件內容中提取關鍵字並將其新增為中繼資料。
用法
@Component
class MyKeywordEnricher {
private final ChatModel chatModel;
MyKeywordEnricher(ChatModel chatModel) {
this.chatModel = chatModel;
}
List<Document> enrichDocuments(List<Document> documents) {
KeywordMetadataEnricher enricher = new KeywordMetadataEnricher(this.chatModel, 5);
return enricher.apply(documents);
}
}建構子
KeywordMetadataEnricher 建構子接受兩個參數
-
ChatModel chatModel:用於產生關鍵字的 AI 模型。 -
int keywordCount:每個文件要提取的關鍵字數量。
行為
KeywordMetadataEnricher 處理文件的方式如下
-
對於每個輸入文件,它都會使用文件的內容建立提示。
-
它將此提示傳送給提供的
ChatModel以產生關鍵字。 -
產生的關鍵字會新增到文件的中繼資料中,鍵為 "excerpt_keywords"。
-
傳回豐富的文件。
自訂
可以透過修改類別中的 KEYWORDS_TEMPLATE 常數來自訂關鍵字提取提示。預設範本為
\{context_str}. Give %s unique keywords for this document. Format as comma separated. Keywords:其中 {context_str} 會被文件內容取代,而 %s 會被指定的關鍵字計數取代。
範例
ChatModel chatModel = // initialize your chat model
KeywordMetadataEnricher enricher = new KeywordMetadataEnricher(chatModel, 5);
Document doc = new Document("This is a document about artificial intelligence and its applications in modern technology.");
List<Document> enrichedDocs = enricher.apply(List.of(this.doc));
Document enrichedDoc = this.enrichedDocs.get(0);
String keywords = (String) this.enrichedDoc.getMetadata().get("excerpt_keywords");
System.out.println("Extracted keywords: " + keywords);SummaryMetadataEnricher
SummaryMetadataEnricher 是一個 DocumentTransformer,它使用生成式 AI 模型為文件建立摘要並將其新增為中繼資料。它可以為目前文件以及相鄰文件(上一個和下一個)產生摘要。
用法
@Configuration
class EnricherConfig {
@Bean
public SummaryMetadataEnricher summaryMetadata(OpenAiChatModel aiClient) {
return new SummaryMetadataEnricher(aiClient,
List.of(SummaryType.PREVIOUS, SummaryType.CURRENT, SummaryType.NEXT));
}
}
@Component
class MySummaryEnricher {
private final SummaryMetadataEnricher enricher;
MySummaryEnricher(SummaryMetadataEnricher enricher) {
this.enricher = enricher;
}
List<Document> enrichDocuments(List<Document> documents) {
return this.enricher.apply(documents);
}
}建構子
SummaryMetadataEnricher 提供兩個建構子
-
SummaryMetadataEnricher(ChatModel chatModel, List<SummaryType> summaryTypes) -
SummaryMetadataEnricher(ChatModel chatModel, List<SummaryType> summaryTypes, String summaryTemplate, MetadataMode metadataMode)
參數
-
chatModel:用於產生摘要的 AI 模型。 -
summaryTypes:SummaryType列舉值的列表,指示要產生哪些摘要(PREVIOUS、CURRENT、NEXT)。 -
summaryTemplate:用於摘要產生的自訂範本(可選)。 -
metadataMode:指定在產生摘要時如何處理文件元資料(可選)。
行為
SummaryMetadataEnricher 處理文件的方式如下
-
對於每個輸入文件,它都會使用文件的內容和指定的摘要範本建立提示。
-
它將此提示傳送給提供的
ChatModel以產生摘要。 -
根據指定的
summaryTypes,它會將以下中繼資料新增到每個文件-
section_summary:目前文件的摘要。 -
prev_section_summary:上一個文件的摘要(如果可用且已請求)。 -
next_section_summary:下一個文件的摘要(如果可用且已請求)。
-
-
傳回豐富的文件。
自訂
可以透過提供自訂 summaryTemplate 來自訂摘要產生提示。預設範本為
"""
Here is the content of the section:
{context_str}
Summarize the key topics and entities of the section.
Summary:
"""範例
ChatModel chatModel = // initialize your chat model
SummaryMetadataEnricher enricher = new SummaryMetadataEnricher(chatModel,
List.of(SummaryType.PREVIOUS, SummaryType.CURRENT, SummaryType.NEXT));
Document doc1 = new Document("Content of document 1");
Document doc2 = new Document("Content of document 2");
List<Document> enrichedDocs = enricher.apply(List.of(this.doc1, this.doc2));
// Check the metadata of the enriched documents
for (Document doc : enrichedDocs) {
System.out.println("Current summary: " + doc.getMetadata().get("section_summary"));
System.out.println("Previous summary: " + doc.getMetadata().get("prev_section_summary"));
System.out.println("Next summary: " + doc.getMetadata().get("next_section_summary"));
}提供的範例示範了預期的行為
-
對於兩個文件的列表,兩個文件都會收到
section_summary。 -
第一個文件收到
next_section_summary,但沒有prev_section_summary。 -
第二個文件收到
prev_section_summary,但沒有next_section_summary。 -
第一個文件的
section_summary與第二個文件的prev_section_summary相符。 -
第一個文件的
next_section_summary與第二個文件的section_summary相符。
寫入器
檔案
FileDocumentWriter 是一個 DocumentWriter 實作,它將 Document 物件列表的內容寫入到檔案中。
用法
@Component
class MyDocumentWriter {
public void writeDocuments(List<Document> documents) {
FileDocumentWriter writer = new FileDocumentWriter("output.txt", true, MetadataMode.ALL, false);
writer.accept(documents);
}
}建構子
FileDocumentWriter 提供三個建構子
-
FileDocumentWriter(String fileName) -
FileDocumentWriter(String fileName, boolean withDocumentMarkers) -
FileDocumentWriter(String fileName, boolean withDocumentMarkers, MetadataMode metadataMode, boolean append)
參數
-
fileName:要將文件寫入的檔案名稱。 -
withDocumentMarkers:是否在輸出中包含文件標記(預設值:false)。 -
metadataMode:指定要寫入檔案的文件內容(預設值:MetadataMode.NONE)。 -
append:如果為 true,資料將寫入檔案的末尾而不是開頭(預設值:false)。
行為
FileDocumentWriter 處理文件的方式如下
-
它為指定的檔案名稱開啟一個 FileWriter。
-
對於輸入列表中的每個文件
-
如果
withDocumentMarkers為 true,它會寫入文件標記,包括文件索引和頁碼。 -
它根據指定的
metadataMode寫入文件的格式化內容。
-
-
在寫入所有文件後,檔案會關閉。
文件標記
當 withDocumentMarkers 設定為 true 時,寫入器會在每個文件中包含以下格式的標記
### Doc: [index], pages:[start_page_number,end_page_number]VectorStore
提供與各種向量儲存庫的整合。如需完整列表,請參閱 向量資料庫文件。

