Ollama Chat
透過 Ollama,您可以在本機執行各種大型語言模型 (LLM) 並從中產生文字。Spring AI 透過 OllamaChatModel API 支援 Ollama 聊天完成功能。
| Ollama 也提供與 OpenAI API 相容的端點。OpenAI API 相容性 章節說明如何使用 Spring AI OpenAI 連接到 Ollama 伺服器。 |
先決條件
您首先需要存取 Ollama 執行個體。有幾種選項,包括以下
-
透過 Kubernetes 服務綁定綁定到 Ollama 執行個體。
您可以從 Ollama 模型庫提取您想要在應用程式中使用的模型
ollama pull <model-name>您也可以提取數千個免費的 GGUF Hugging Face 模型
ollama pull hf.co/<username>/<model-repository>或者,您可以啟用自動下載任何所需模型的選項:自動提取模型。
自動設定
Spring AI 為 Ollama 聊天整合提供 Spring Boot 自動設定。若要啟用它,請將以下依賴項新增至專案的 Maven pom.xml 或 Gradle build.gradle 建置檔案
-
Maven
-
Gradle
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-ollama-spring-boot-starter</artifactId>
</dependency>dependencies {
implementation 'org.springframework.ai:spring-ai-ollama-spring-boot-starter'
}| 請參閱 依賴項管理 章節,將 Spring AI BOM 新增至您的建置檔案。 |
基本屬性
前綴 spring.ai.ollama 是設定與 Ollama 連線的屬性前綴。
屬性 |
描述 |
預設值 |
spring.ai.ollama.base-url |
Ollama API 伺服器正在執行的基本 URL。 |
以下是用於初始化 Ollama 整合和自動提取模型的屬性。
屬性 |
描述 |
預設值 |
spring.ai.ollama.init.pull-model-strategy |
是否在啟動時提取模型以及如何提取。 |
|
spring.ai.ollama.init.timeout |
等待模型提取的最長時間。 |
|
spring.ai.ollama.init.max-retries |
模型提取操作的最大重試次數。 |
|
spring.ai.ollama.init.chat.include |
在初始化任務中包含此類型的模型。 |
|
spring.ai.ollama.init.chat.additional-models |
除了透過預設屬性設定的模型外,要初始化的其他模型。 |
|
聊天屬性
前綴 spring.ai.ollama.chat.options 是設定 Ollama 聊天模型的屬性前綴。它包含 Ollama 請求 (進階) 參數,例如 model、keep-alive 和 format,以及 Ollama 模型 options 屬性。
以下是 Ollama 聊天模型的進階請求參數
屬性 |
描述 |
預設值 |
spring.ai.ollama.chat.enabled |
啟用 Ollama 聊天模型。 |
true |
spring.ai.ollama.chat.options.model |
支援的模型名稱,以供使用。 |
mistral |
spring.ai.ollama.chat.options.format |
傳回回應的格式。目前,唯一接受的值是 |
- |
spring.ai.ollama.chat.options.keep_alive |
控制模型在請求後於記憶體中保持載入的時間長度 |
5m |
剩餘的 options 屬性基於 Ollama 有效參數和值 和 Ollama 類型。預設值基於 Ollama 類型預設值。
屬性 |
描述 |
預設值 |
spring.ai.ollama.chat.options.numa |
是否使用 NUMA。 |
false |
spring.ai.ollama.chat.options.num-ctx |
設定用於產生下一個權杖的上下文視窗大小。 |
2048 |
spring.ai.ollama.chat.options.num-batch |
提示詞處理最大批次大小。 |
512 |
spring.ai.ollama.chat.options.num-gpu |
要傳送到 GPU 的層數。在 macOS 上,預設值為 1 以啟用 Metal 支援,0 則為停用。此處的 1 表示 NumGPU 應動態設定 |
-1 |
spring.ai.ollama.chat.options.main-gpu |
當使用多個 GPU 時,此選項控制哪個 GPU 用於小型張量,因為對於這些張量,跨所有 GPU 拆分計算的額外負擔不值得。有問題的 GPU 將使用稍多的 VRAM 來儲存暫時結果的暫存緩衝區。 |
0 |
spring.ai.ollama.chat.options.low-vram |
- |
false |
spring.ai.ollama.chat.options.f16-kv |
- |
true |
spring.ai.ollama.chat.options.logits-all |
傳回所有權杖的 logits,而不僅僅是最後一個。若要啟用完成以傳回 logprobs,則必須為 true。 |
- |
spring.ai.ollama.chat.options.vocab-only |
僅載入詞彙表,不載入權重。 |
- |
spring.ai.ollama.chat.options.use-mmap |
預設情況下,模型會對應到記憶體中,這允許系統僅在需要時載入模型必要的部件。但是,如果模型大於 RAM 總量,或者系統可用記憶體不足,則使用 mmap 可能會增加分頁輸出的風險,從而對效能產生負面影響。停用 mmap 會導致載入時間變慢,但如果您未使用 mlock,則可能會減少分頁輸出。請注意,如果模型大於 RAM 總量,則關閉 mmap 會阻止模型完全載入。 |
null |
spring.ai.ollama.chat.options.use-mlock |
將模型鎖定在記憶體中,防止在記憶體對應時將其換出。這可以提高效能,但會透過需要更多 RAM 來執行並可能減慢載入時間來換取記憶體對應的一些優勢。 |
false |
spring.ai.ollama.chat.options.num-thread |
設定計算期間要使用的執行緒數。預設情況下,Ollama 會偵測到此值以獲得最佳效能。建議將此值設定為系統擁有的實體 CPU 核心數 (而非邏輯核心數)。0 = 讓執行階段決定 |
0 |
spring.ai.ollama.chat.options.num-keep |
- |
4 |
spring.ai.ollama.chat.options.seed |
設定用於產生的隨機數種子。將其設定為特定數字將使模型針對相同的提示詞產生相同的文字。 |
-1 |
spring.ai.ollama.chat.options.num-predict |
產生文字時要預測的最大權杖數。(-1 = 無限產生,-2 = 填滿上下文) |
-1 |
spring.ai.ollama.chat.options.top-k |
降低產生無意義內容的可能性。較高的值 (例如,100) 會提供更多樣化的答案,而較低的值 (例如,10) 會更保守。 |
40 |
spring.ai.ollama.chat.options.top-p |
與 top-k 一起使用。較高的值 (例如,0.95) 會產生更多樣化的文字,而較低的值 (例如,0.5) 會產生更集中且保守的文字。 |
0.9 |
spring.ai.ollama.chat.options.tfs-z |
尾部自由取樣用於減少輸出中不太可能的權杖的影響。較高的值 (例如,2.0) 將更有效地減少影響,而值 1.0 會停用此設定。 |
1.0 |
spring.ai.ollama.chat.options.typical-p |
- |
1.0 |
spring.ai.ollama.chat.options.repeat-last-n |
設定模型回溯以防止重複的回溯距離。(預設值:64,0 = 停用,-1 = num_ctx) |
64 |
spring.ai.ollama.chat.options.temperature |
模型的溫度。提高溫度會使模型回答更具創造力。 |
0.8 |
spring.ai.ollama.chat.options.repeat-penalty |
設定懲罰重複的強度。較高的值 (例如,1.5) 將更強烈地懲罰重複,而較低的值 (例如,0.9) 將更寬鬆。 |
1.1 |
spring.ai.ollama.chat.options.presence-penalty |
- |
0.0 |
spring.ai.ollama.chat.options.frequency-penalty |
- |
0.0 |
spring.ai.ollama.chat.options.mirostat |
啟用 Mirostat 取樣以控制困惑度。(預設值:0,0 = 停用,1 = Mirostat,2 = Mirostat 2.0) |
0 |
spring.ai.ollama.chat.options.mirostat-tau |
控制輸出的一致性和多樣性之間的平衡。較低的值將產生更集中且一致的文字。 |
5.0 |
spring.ai.ollama.chat.options.mirostat-eta |
影響演算法對來自產生文字的回饋做出反應的速度。較低的學習率將導致調整速度變慢,而較高的學習率將使演算法更靈敏。 |
0.1 |
spring.ai.ollama.chat.options.penalize-newline |
- |
true |
spring.ai.ollama.chat.options.stop |
設定要使用的停止序列。當遇到此模式時,LLM 將停止產生文字並傳回。可以透過在模型檔案中指定多個單獨的停止參數來設定多個停止模式。 |
- |
spring.ai.ollama.chat.options.functions |
函式清單,依其名稱識別,以在單一提示詞請求中啟用函式呼叫。具有這些名稱的函式必須存在於 functionCallbacks 登錄檔中。 |
- |
spring.ai.ollama.chat.options.proxy-tool-calls |
如果為 true,Spring AI 將不會在內部處理函式呼叫,而是將它們代理到用戶端。然後,用戶端有責任處理函式呼叫、將它們分派到適當的函式並傳回結果。如果為 false(預設值),Spring AI 將在內部處理函式呼叫。僅適用於具有函式呼叫支援的聊天模型 |
false |
所有以 spring.ai.ollama.chat.options 為前綴的屬性都可以在執行階段透過將特定於請求的 執行階段選項 新增至 Prompt 呼叫來覆寫。 |
執行階段選項
OllamaOptions.java 類別提供模型設定,例如要使用的模型、溫度等。
在啟動時,可以使用 OllamaChatModel(api, options) 建構函式或 spring.ai.ollama.chat.options.* 屬性設定預設選項。
在執行階段,您可以透過將新的特定於請求的選項新增至 Prompt 呼叫來覆寫預設選項。例如,若要覆寫特定請求的預設模型和溫度
ChatResponse response = chatModel.call(
new Prompt(
"Generate the names of 5 famous pirates.",
OllamaOptions.builder()
.withModel(OllamaModel.LLAMA3_1)
.withTemperature(0.4)
.build()
));| 除了特定於模型的 OllamaOptions,您可以使用可攜式 ChatOptions 執行個體,使用 ChatOptionsBuilder#builder() 建立。 |
自動提取模型
當 Spring AI Ollama 模型在您的 Ollama 執行個體中不可用時,它可以自動提取模型。此功能對於開發和測試以及將應用程式部署到新環境特別有用。
| 您也可以按名稱提取數千個免費的 GGUF Hugging Face 模型。 |
提取模型有三種策略
-
always(在PullModelStrategy.ALWAYS中定義):始終提取模型,即使模型已可用。適用於確保您正在使用模型的最新版本。 -
when_missing(在PullModelStrategy.WHEN_MISSING中定義):僅在模型尚不可用時才提取模型。這可能會導致使用較舊版本的模型。 -
never(在PullModelStrategy.NEVER中定義):永遠不要自動提取模型。
| 由於下載模型時可能會發生延遲,因此不建議在生產環境中使用自動提取。相反,請考慮提前評估和預先下載必要的模型。 |
所有透過設定屬性和預設選項定義的模型都可以在啟動時自動提取。您可以使用設定屬性設定提取策略、逾時和最大重試次數
spring:
ai:
ollama:
init:
pull-model-strategy: always
timeout: 60s
max-retries: 1| 在所有指定的模型在 Ollama 中可用之前,應用程式將不會完成其初始化。根據模型大小和網際網路連線速度,這可能會顯著減慢應用程式的啟動時間。 |
您可以在啟動時初始化其他模型,這對於在執行階段動態使用的模型很有用
spring:
ai:
ollama:
init:
pull-model-strategy: always
chat:
additional-models:
- llama3.2
- qwen2.5如果您只想將提取策略應用於特定類型的模型,則可以從初始化任務中排除聊天模型
spring:
ai:
ollama:
init:
pull-model-strategy: always
chat:
include: false此設定將提取策略應用於除聊天模型外的所有模型。
函式呼叫
您可以向 OllamaChatModel 註冊自訂 Java 函式,並讓 Ollama 模型智慧地選擇輸出 JSON 物件,其中包含呼叫一個或多個已註冊函式的引數。這是一種將 LLM 功能與外部工具和 API 連接的強大技術。閱讀有關 Ollama 函式呼叫的更多資訊。
| 您需要 Ollama 0.2.8 或更新版本才能使用函式呼叫功能。 |
| 目前,Ollama API (0.3.8) 不支援串流模式中的函式呼叫。 |
多模態
多模態是指模型同時理解和處理來自各種來源資訊的能力,包括文字、圖像、音訊和其他資料格式。
Ollama 中提供的一些具有多模態支援的模型是 LLaVa 和 bakllava(請參閱完整清單)。如需更多詳細資訊,請參閱 LLaVA:大型語言和視覺助理。
Ollama 訊息 API 提供「images」參數,以將 base64 編碼圖像清單與訊息合併。
Spring AI 的 Message 介面透過引入 Media 類型來促進多模態 AI 模型。此類型包含有關訊息中媒體附件的資料和詳細資訊,使用 Spring 的 org.springframework.util.MimeType 和 org.springframework.core.io.Resource 作為原始媒體資料。
以下是摘錄自 OllamaChatModelMultimodalIT.java 的簡單程式碼範例,說明使用者文字與圖像的融合。
var imageResource = new ClassPathResource("/multimodal.test.png");
var userMessage = new UserMessage("Explain what do you see on this picture?",
new Media(MimeTypeUtils.IMAGE_PNG, this.imageResource));
ChatResponse response = chatModel.call(new Prompt(this.userMessage,
OllamaOptions.builder().withModel(OllamaModel.LLAVA)).build());該範例顯示模型將 multimodal.test.png 圖像作為輸入

以及文字訊息「Explain what do you see on this picture?」(解釋您在這張圖片上看到什麼?),並產生如下的回應
The image shows a small metal basket filled with ripe bananas and red apples. The basket is placed on a surface, which appears to be a table or countertop, as there's a hint of what seems like a kitchen cabinet or drawer in the background. There's also a gold-colored ring visible behind the basket, which could indicate that this photo was taken in an area with metallic decorations or fixtures. The overall setting suggests a home environment where fruits are being displayed, possibly for convenience or aesthetic purposes.
OpenAI API 相容性
Ollama 與 OpenAI API 相容,您可以使用 Spring AI OpenAI 用戶端與 Ollama 通訊並使用工具。為此,您需要將 OpenAI 基本 URL 設定為您的 Ollama 執行個體:spring.ai.openai.chat.base-url=http://localhost:11434 並選取提供的 Ollama 模型之一:spring.ai.openai.chat.options.model=mistral。
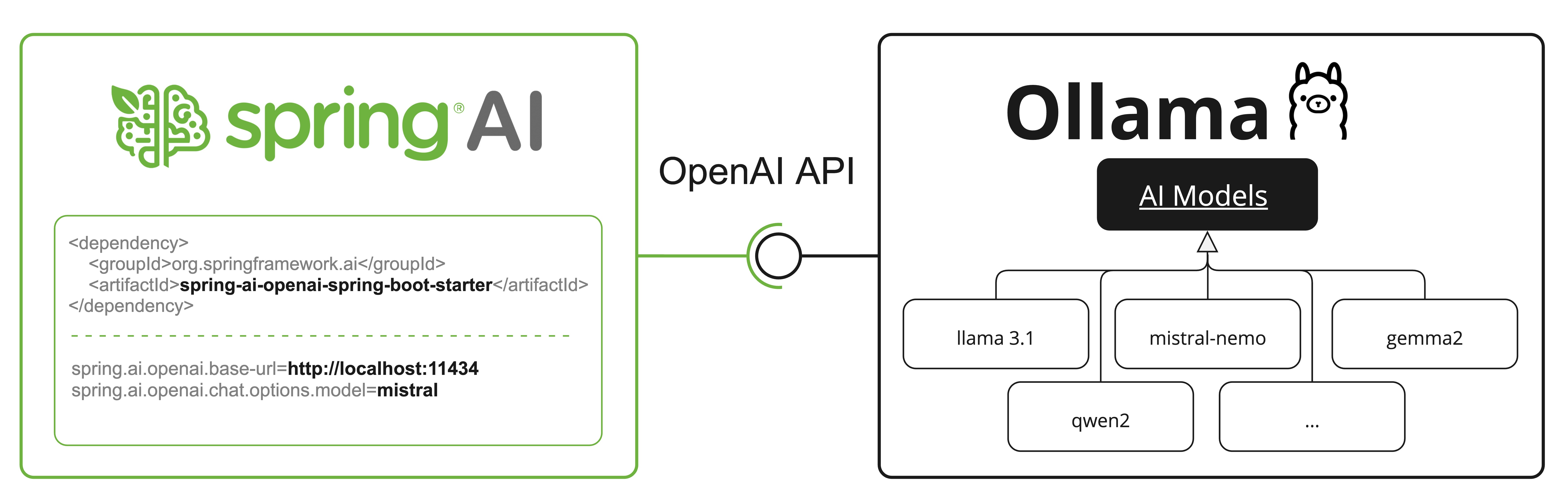
檢查 OllamaWithOpenAiChatModelIT.java 測試,以取得透過 Spring AI OpenAI 使用 Ollama 的範例。
範例控制器
建立新的 Spring Boot 專案,並將 spring-ai-ollama-spring-boot-starter 新增至您的 pom (或 gradle) 依賴項。
在 src/main/resources 目錄下新增 application.yaml 檔案,以啟用和設定 Ollama 聊天模型
spring:
ai:
ollama:
base-url: http://localhost:11434
chat:
options:
model: mistral
temperature: 0.7將 base-url 取代為您的 Ollama 伺服器 URL。 |
這將建立一個 OllamaChatModel 實作,您可以將其注入到您的類別中。以下是一個簡單的 @RestController 類別範例,該類別使用聊天模型進行文字產生。
@RestController
public class ChatController {
private final OllamaChatModel chatModel;
@Autowired
public ChatController(OllamaChatModel chatModel) {
this.chatModel = chatModel;
}
@GetMapping("/ai/generate")
public Map<String,String> generate(@RequestParam(value = "message", defaultValue = "Tell me a joke") String message) {
return Map.of("generation", this.chatModel.call(message));
}
@GetMapping("/ai/generateStream")
public Flux<ChatResponse> generateStream(@RequestParam(value = "message", defaultValue = "Tell me a joke") String message) {
Prompt prompt = new Prompt(new UserMessage(message));
return this.chatModel.stream(prompt);
}
}手動設定
如果您不想使用 Spring Boot 自動設定,您可以在應用程式中手動設定 OllamaChatModel。OllamaChatModel 實作 ChatModel 和 StreamingChatModel,並使用 低階 OllamaApi 用戶端 連接到 Ollama 服務。
若要使用它,請將 spring-ai-ollama 依賴項新增至專案的 Maven pom.xml 或 Gradle build.gradle 建置檔案
-
Maven
-
Gradle
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-ollama</artifactId>
</dependency>dependencies {
implementation 'org.springframework.ai:spring-ai-ollama'
}| 請參閱 依賴項管理 章節,將 Spring AI BOM 新增至您的建置檔案。 |
spring-ai-ollama 依賴項也提供對 OllamaEmbeddingModel 的存取權。如需有關 OllamaEmbeddingModel 的更多資訊,請參閱 Ollama 嵌入模型 章節。 |
接下來,建立 OllamaChatModel 執行個體,並使用它來傳送文字產生請求
var ollamaApi = new OllamaApi();
var chatModel = new OllamaChatModel(this.ollamaApi,
OllamaOptions.create()
.withModel(OllamaOptions.DEFAULT_MODEL)
.withTemperature(0.9));
ChatResponse response = this.chatModel.call(
new Prompt("Generate the names of 5 famous pirates."));
// Or with streaming responses
Flux<ChatResponse> response = this.chatModel.stream(
new Prompt("Generate the names of 5 famous pirates."));OllamaOptions 提供所有聊天請求的設定資訊。
低階 OllamaApi 用戶端
OllamaApi 為 Ollama 聊天完成 API Ollama 聊天完成 API 提供輕量級 Java 用戶端。
以下類別圖說明 OllamaApi 聊天介面和建置組塊
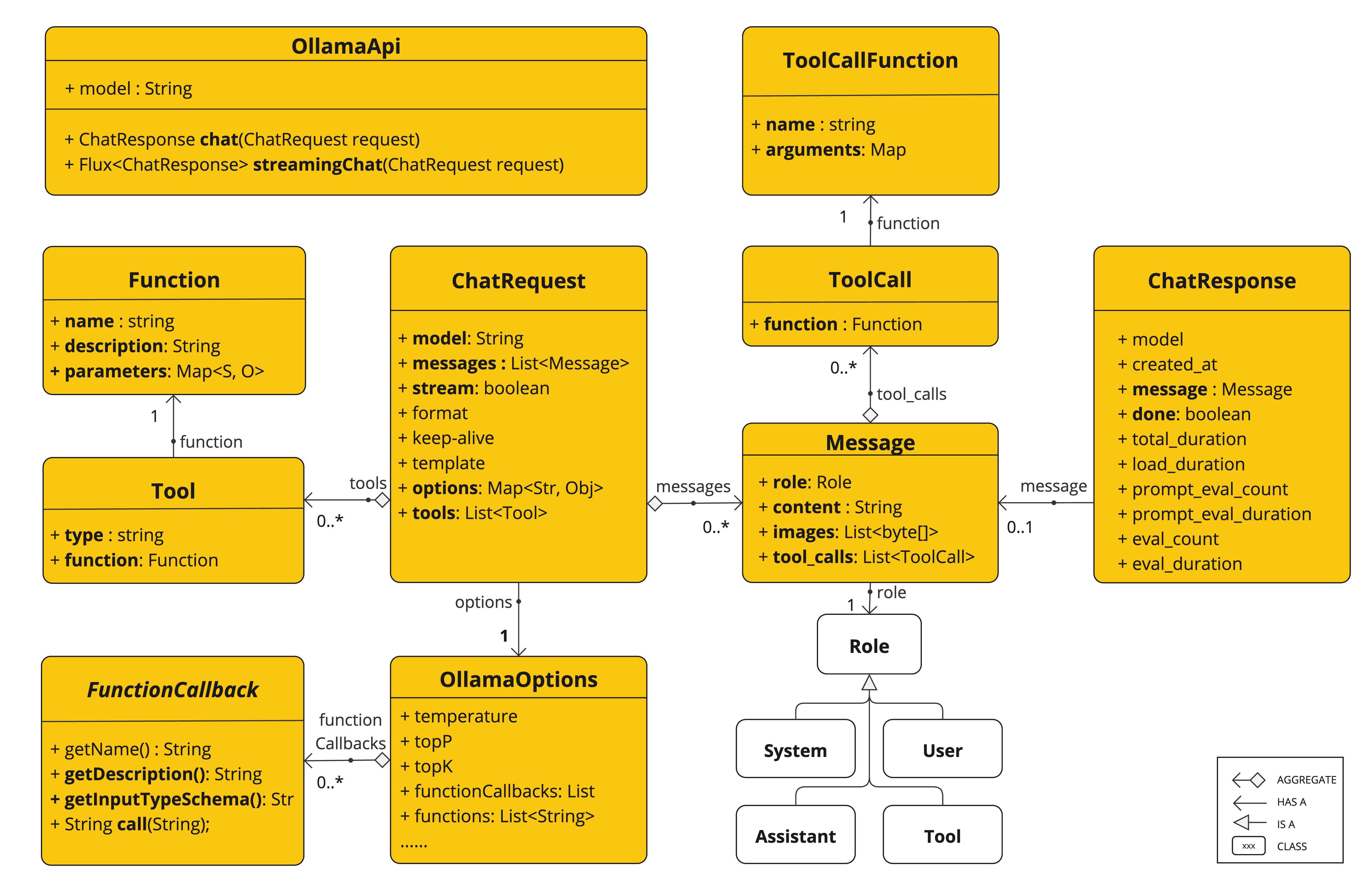
OllamaApi 是一個低階 API,不建議直接使用。請改用 OllamaChatModel。 |
以下是一個簡單的程式碼片段,顯示如何以程式設計方式使用 API
OllamaApi ollamaApi = new OllamaApi("YOUR_HOST:YOUR_PORT");
// Sync request
var request = ChatRequest.builder("orca-mini")
.withStream(false) // not streaming
.withMessages(List.of(
Message.builder(Role.SYSTEM)
.withContent("You are a geography teacher. You are talking to a student.")
.build(),
Message.builder(Role.USER)
.withContent("What is the capital of Bulgaria and what is the size? "
+ "What is the national anthem?")
.build()))
.withOptions(OllamaOptions.create().withTemperature(0.9))
.build();
ChatResponse response = this.ollamaApi.chat(this.request);
// Streaming request
var request2 = ChatRequest.builder("orca-mini")
.withStream(true) // streaming
.withMessages(List.of(Message.builder(Role.USER)
.withContent("What is the capital of Bulgaria and what is the size? " + "What is the national anthem?")
.build()))
.withOptions(OllamaOptions.create().withTemperature(0.9).toMap())
.build();
Flux<ChatResponse> streamingResponse = this.ollamaApi.streamingChat(this.request2);
