批次處理的領域語言
對於任何經驗豐富的批次處理架構師來說,Spring Batch 中使用的批次處理整體概念應該是熟悉且舒適的。有「Jobs」和「Steps」,以及開發人員提供的處理單元,稱為 ItemReader 和 ItemWriter。然而,由於 Spring 的模式、操作、範本、回呼和慣用語,以下方面有改進的機會:
-
在更清楚地遵守關注點分離方面有顯著改進。
-
清楚劃分的架構層次和以介面形式提供的服務。
-
簡單且預設的實作,可實現快速採用和開箱即用的易用性。
-
顯著增強的擴展性。
下圖是數十年來使用的批次處理參考架構的簡化版本。它概述了構成批次處理領域語言的組件。此架構框架是一個藍圖,已在過去幾代平台(大型主機上的 COBOL、Unix 上的 C,以及現在任何地方的 Java)上的數十年實作中得到驗證。JCL 和 COBOL 開發人員可能會像 C、C# 和 Java 開發人員一樣熟悉這些概念。Spring Batch 提供了層、組件和技術服務的實體實作,這些層、組件和技術服務常見於用於解決簡單到複雜批次處理應用程式創建的穩健、可維護系統中,並具有解決非常複雜處理需求的基礎設施和擴展。
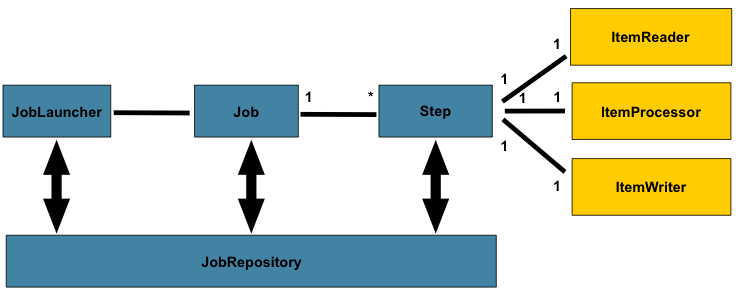
前面的圖表突顯了構成 Spring Batch 領域語言的關鍵概念。一個 Job 有一到多個步驟,每個步驟恰好有一個 ItemReader、一個 ItemProcessor 和一個 ItemWriter。一個 Job 需要被啟動(使用 JobLauncher),並且需要儲存關於目前執行程序的元數據(在 JobRepository 中)。
Job
本節描述與批次處理 Job 概念相關的原型。Job 是一個封裝整個批次處理程序的實體。與其他 Spring 專案常見的情況一樣,Job 可以使用 XML 設定檔或基於 Java 的設定來組裝在一起。此設定可以稱為「job 設定」。然而,Job 只是整體階層的頂端,如下圖所示
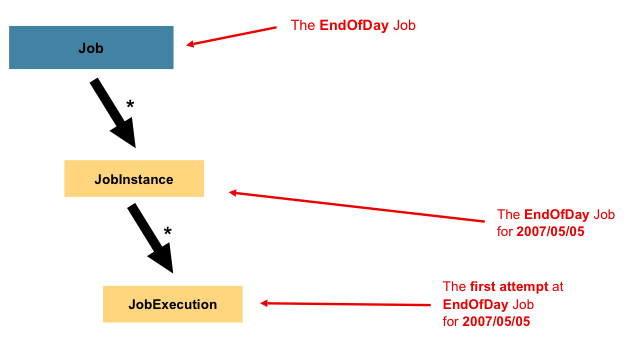
在 Spring Batch 中,Job 僅僅是 Step 實例的容器。它將多個邏輯上屬於同一個流程的步驟組合在一起,並允許設定所有步驟通用的屬性,例如可重新啟動性。job 設定包含
-
Job 的名稱。
-
Step實例的定義和順序。 -
Job 是否可重新啟動。
-
Java
-
XML
對於那些使用 Java 設定的人來說,Spring Batch 以 SimpleJob 類別的形式提供了 Job 介面的預設實作,該類別在 Job 之上建立了一些標準功能。當使用基於 Java 的設定時,可以使用建構器集合來實例化 Job,如下例所示
@Bean
public Job footballJob(JobRepository jobRepository) {
return new JobBuilder("footballJob", jobRepository)
.start(playerLoad())
.next(gameLoad())
.next(playerSummarization())
.build();
}對於那些使用 XML 設定的人來說,Spring Batch 以 SimpleJob 類別的形式提供了 Job 介面的預設實作,該類別在 Job 之上建立了一些標準功能。然而,批次處理命名空間抽象化了直接實例化它的需求。相反,您可以使用 <job> 元素,如下例所示
<job id="footballJob">
<step id="playerload" next="gameLoad"/>
<step id="gameLoad" next="playerSummarization"/>
<step id="playerSummarization"/>
</job>JobInstance
JobInstance 指的是邏輯 job 執行的概念。考慮一個應該在每天結束時執行一次的批次處理 job,例如上圖中的 EndOfDay Job。有一個 EndOfDay job,但是 Job 的每次單獨執行都必須單獨追蹤。對於此 job,每天有一個邏輯 JobInstance。例如,有 1 月 1 日執行、1 月 2 日執行等等。如果 1 月 1 日執行第一次失敗,並在第二天再次執行,它仍然是 1 月 1 日執行。(通常,這也與它正在處理的數據相對應,意味著 1 月 1 日執行處理 1 月 1 日的數據)。因此,每個 JobInstance 可以有多個執行(JobExecution 將在本章稍後更詳細地討論),並且在給定時間只能運行一個 JobInstance(它對應於特定的 Job 和識別 JobParameters)。
JobInstance 的定義與要載入的數據絕對無關。完全由 ItemReader 實作來決定如何載入數據。例如,在 EndOfDay 場景中,數據上可能有一列指示數據所屬的「生效日期」或「排程日期」。因此,1 月 1 日執行將僅載入來自 1 日的數據,而 1 月 2 日執行將僅使用來自 2 日的數據。由於此決定很可能是業務決策,因此留給 ItemReader 來決定。但是,使用相同的 JobInstance 會決定是否使用先前執行的「狀態」(即 ExecutionContext,將在本章稍後討論)。使用新的 JobInstance 意味著「從頭開始」,而使用現有的實例通常意味著「從上次停止的地方開始」。
JobParameters
在討論了 JobInstance 以及它與 Job 的區別之後,自然而然的問題是:「如何區分一個 JobInstance 與另一個 JobInstance?」答案是:JobParameters。JobParameters 物件保存一組用於啟動批次處理 job 的參數。它們可以用於識別,甚至可以用作執行期間的參考數據,如下圖所示
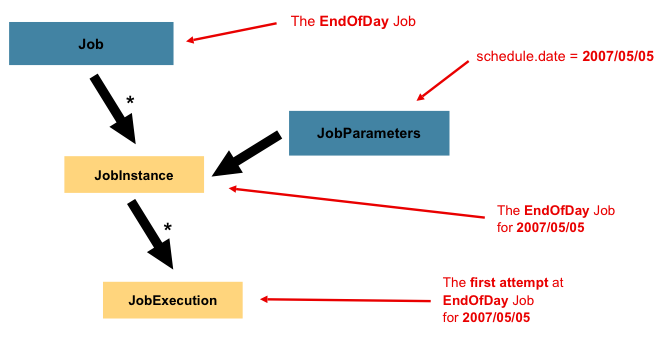
在前面的範例中,其中有兩個實例,一個用於 1 月 1 日,另一個用於 1 月 2 日,實際上只有一個 Job,但它有兩個 JobParameter 物件:一個是以 01-01-2017 的 job 參數啟動的,另一個是以 01-02-2017 的參數啟動的。因此,合約可以定義為:JobInstance = Job + 識別 JobParameters。這允許開發人員有效地控制如何定義 JobInstance,因為他們控制傳入的參數。
並非所有 job 參數都需要有助於 JobInstance 的識別。預設情況下,它們會這樣做。但是,框架也允許提交帶有不影響 JobInstance 身份的參數的 Job。 |
JobExecution
JobExecution 指的是單次嘗試運行 Job 的技術概念。執行可能會以失敗或成功結束,但除非執行成功完成,否則與給定執行相對應的 JobInstance 不會被視為已完成。以上述 EndOfDay Job 為例,考慮一個用於 01-01-2017 的 JobInstance,它在第一次運行時失敗。如果使用與第一次運行相同的識別 job 參數(01-01-2017)再次運行,則會建立一個新的 JobExecution。但是,仍然只有一個 JobInstance。
Job 定義了一個 job 是什麼以及如何執行它,而 JobInstance 是一個純粹的組織物件,用於將執行分組在一起,主要是為了啟用正確的重新啟動語意。然而,JobExecution 是實際運行期間發生的事情的主要儲存機制,並且包含更多必須控制和持久化的屬性,如下表所示
屬性 |
定義 |
|
一個 |
|
一個 |
|
一個 |
|
|
|
一個 |
|
一個 |
|
「屬性包」,包含需要在執行之間持久化的任何使用者數據。 |
|
在 |
這些屬性很重要,因為它們是持久化的,並且可以用於完全確定執行的狀態。例如,如果 01-01 的 EndOfDay job 在晚上 9:00 執行,並在 9:30 失敗,則在批次處理元數據表中建立以下條目
JOB_INST_ID |
JOB_NAME |
1 |
EndOfDayJob |
JOB_EXECUTION_ID |
TYPE_CD |
KEY_NAME |
DATE_VAL |
IDENTIFYING |
1 |
DATE |
schedule.Date |
2017-01-01 |
TRUE |
JOB_EXEC_ID |
JOB_INST_ID |
START_TIME |
END_TIME |
STATUS |
1 |
1 |
2017-01-01 21:00 |
2017-01-01 21:30 |
FAILED |
| 為了清晰和格式化,欄位名稱可能已被縮寫或移除。 |
現在 job 已經失敗,假設花了整個晚上才確定問題,因此「批次處理視窗」現在已關閉。進一步假設視窗從晚上 9:00 開始,job 再次啟動以進行 01-01,從上次停止的地方開始,並在 9:30 成功完成。由於現在是第二天,因此也必須運行 01-02 job,它在 9:31 之後立即啟動,並在其正常的一小時時間內在 10:30 完成。除非兩個 job 可能嘗試存取相同的數據,導致資料庫層級的鎖定問題,否則不要求一個 JobInstance 在另一個之後啟動。完全由排程器來決定何時應運行 Job。由於它們是單獨的 JobInstance,因此 Spring Batch 不會嘗試阻止它們同時運行。(嘗試在另一個 JobInstance 已經運行時運行相同的 JobInstance 會導致拋出 JobExecutionAlreadyRunningException)。現在 JobInstance 和 JobParameters 表中都應該有一個額外的條目,並且在 JobExecution 表中應該有兩個額外的條目,如下表所示
JOB_INST_ID |
JOB_NAME |
1 |
EndOfDayJob |
2 |
EndOfDayJob |
JOB_EXECUTION_ID |
TYPE_CD |
KEY_NAME |
DATE_VAL |
IDENTIFYING |
1 |
DATE |
schedule.Date |
2017-01-01 00:00:00 |
TRUE |
2 |
DATE |
schedule.Date |
2017-01-01 00:00:00 |
TRUE |
3 |
DATE |
schedule.Date |
2017-01-02 00:00:00 |
TRUE |
JOB_EXEC_ID |
JOB_INST_ID |
START_TIME |
END_TIME |
STATUS |
1 |
1 |
2017-01-01 21:00 |
2017-01-01 21:30 |
FAILED |
2 |
1 |
2017-01-02 21:00 |
2017-01-02 21:30 |
COMPLETED |
3 |
2 |
2017-01-02 21:31 |
2017-01-02 22:29 |
COMPLETED |
| 為了清晰和格式化,欄位名稱可能已被縮寫或移除。 |
Step
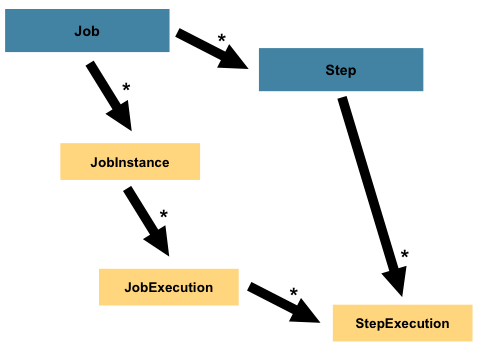
Step 是一個領域物件,它封裝了批次處理 job 的獨立、循序階段。因此,每個 Job 完全由一個或多個步驟組成。Step 包含定義和控制實際批次處理所需的所有資訊。這是一個必然模糊的描述,因為任何給定 Step 的內容都由編寫 Job 的開發人員自行決定。Step 可以像開發人員希望的那樣簡單或複雜。一個簡單的 Step 可能會將資料從檔案載入到資料庫中,幾乎不需要程式碼(取決於使用的實作)。更複雜的 Step 可能具有複雜的業務規則,這些規則在處理過程中應用。與 Job 一樣,Step 具有與唯一 JobExecution 相關聯的個別 StepExecution,如下圖所示
StepExecution
StepExecution 代表單次嘗試執行 Step。每次運行 Step 時都會建立新的 StepExecution,類似於 JobExecution。但是,如果由於之前的步驟失敗而導致步驟執行失敗,則不會為其持久化執行。僅當 StepExecution 的 Step 實際啟動時才會建立 StepExecution。
Step 執行由 StepExecution 類別的物件表示。每個執行都包含對其對應步驟和 JobExecution 的參考,以及與交易相關的數據,例如提交和回滾計數以及開始和結束時間。此外,每個步驟執行都包含一個 ExecutionContext,其中包含開發人員需要在批次處理運行之間持久化的任何數據,例如統計資訊或重新啟動所需的狀態資訊。下表列出了 StepExecution 的屬性
屬性 |
定義 |
|
一個 |
|
一個 |
|
一個 |
|
指示執行結果的 |
|
「屬性包」,包含需要在執行之間持久化的任何使用者數據。 |
|
已成功讀取的項目數。 |
|
已成功寫入的項目數。 |
|
已為此執行提交的交易數。 |
|
由 |
|
|
|
|
|
已被 |
|
|
ExecutionContext
ExecutionContext 表示鍵/值對的集合,這些鍵/值對由框架持久化和控制,以便為開發人員提供一個位置來儲存範圍限定為 StepExecution 物件或 JobExecution 物件的持久狀態。(對於熟悉 Quartz 的人來說,它與 JobDataMap 非常相似。)最佳用法範例是促進重新啟動。以平面檔案輸入為例,在處理個別行時,框架會在提交點定期持久化 ExecutionContext。這樣做可以讓 ItemReader 儲存其狀態,以防在運行期間發生致命錯誤,甚至停電。所有需要做的就是將目前讀取的行數放入上下文中,如下例所示,框架會完成剩下的工作
executionContext.putLong(getKey(LINES_READ_COUNT), reader.getPosition());以上述 Job 原型部分中的 EndOfDay 範例為例,假設有一個步驟 loadData,它將檔案載入到資料庫中。在第一次失敗運行後,元數據表將如下例所示
JOB_INST_ID |
JOB_NAME |
1 |
EndOfDayJob |
JOB_INST_ID |
TYPE_CD |
KEY_NAME |
DATE_VAL |
1 |
DATE |
schedule.Date |
2017-01-01 |
JOB_EXEC_ID |
JOB_INST_ID |
START_TIME |
END_TIME |
STATUS |
1 |
1 |
2017-01-01 21:00 |
2017-01-01 21:30 |
FAILED |
STEP_EXEC_ID |
JOB_EXEC_ID |
STEP_NAME |
START_TIME |
END_TIME |
STATUS |
1 |
1 |
loadData |
2017-01-01 21:00 |
2017-01-01 21:30 |
FAILED |
STEP_EXEC_ID |
SHORT_CONTEXT |
1 |
{piece.count=40321} |
在上述情況下,Step 運行了 30 分鐘,並處理了 40,321 個「片段」,在本場景中,這將代表檔案中的行。此值在框架每次提交之前更新,並且可以包含與 ExecutionContext 中的條目相對應的多行。在提交之前收到通知需要各種 StepListener 實作之一(或 ItemStream),這些實作將在本指南稍後更詳細地討論。與之前的範例一樣,假設 Job 在第二天重新啟動。重新啟動時,上次運行的 ExecutionContext 中的值會從資料庫中重新建立。當 ItemReader 開啟時,它可以檢查它在上下文中是否有任何儲存的狀態,並從那裡初始化自身,如下例所示
if (executionContext.containsKey(getKey(LINES_READ_COUNT))) {
log.debug("Initializing for restart. Restart data is: " + executionContext);
long lineCount = executionContext.getLong(getKey(LINES_READ_COUNT));
LineReader reader = getReader();
Object record = "";
while (reader.getPosition() < lineCount && record != null) {
record = readLine();
}
}在這種情況下,在前面的程式碼運行後,目前行是 40,322,讓 Step 從上次停止的地方再次開始。您也可以使用 ExecutionContext 來獲取需要持久化的關於運行本身的統計資訊。例如,如果平面檔案包含跨越多行的處理訂單,則可能需要儲存已處理的訂單數量(這與讀取的行數大不相同),以便可以在 Step 結束時發送一封電子郵件,其中包含正文中處理的訂單總數。框架處理為開發人員儲存此資訊,以正確地將其範圍限定為個別 JobInstance。很難知道是否應該使用現有的 ExecutionContext。例如,使用上面 EndOfDay 範例,當 01-01 運行第二次再次開始時,框架會識別出它是相同的 JobInstance,並在個別 Step 基礎上,從資料庫中提取 ExecutionContext,並將其(作為 StepExecution 的一部分)交給 Step 本身。相反,對於 01-02 運行,框架會識別出它是一個不同的實例,因此必須將一個空的上下文交給 Step。框架為開發人員做出了許多這種類型的判斷,以確保在正確的時間將狀態給予他們。同樣重要的是要注意,在任何給定時間,每個 StepExecution 都恰好存在一個 ExecutionContext。ExecutionContext 的客戶端應該小心,因為這會建立一個共用的鍵空間。因此,在放入值時應小心,以確保沒有數據被覆蓋。但是,Step 絕對不會在上下文中儲存任何數據,因此沒有辦法對框架產生不利影響。
請注意,每個 JobExecution 至少有一個 ExecutionContext,每個 StepExecution 也有一個。例如,考慮以下程式碼片段
ExecutionContext ecStep = stepExecution.getExecutionContext();
ExecutionContext ecJob = jobExecution.getExecutionContext();
//ecStep does not equal ecJob如註解中所述,ecStep 不等於 ecJob。它們是兩個不同的 ExecutionContexts。範圍限定為 Step 的那個在 Step 中的每個提交點儲存,而範圍限定為 Job 的那個在每個 Step 執行之間儲存。
在 ExecutionContext 中,所有非暫時性條目都必須是 Serializable。執行環境的正確序列化支撐了步驟和 job 的重新啟動能力。如果您使用本質上不可序列化的鍵或值,則需要採用量身定制的序列化方法。無法序列化執行環境可能會危及狀態持久化過程,使失敗的 job 無法正確恢復。 |
JobRepository
JobRepository 是所有先前提及的原型的持久化機制。它為 JobLauncher、Job 和 Step 實作提供 CRUD 操作。當 Job 首次啟動時,會從儲存庫取得 JobExecution。此外,在執行過程中,StepExecution 和 JobExecution 實作透過將它們傳遞到儲存庫來持久化。
-
Java
-
XML
當使用 Java 設定時,@EnableBatchProcessing 註解提供 JobRepository 作為自動設定的組件之一。
Spring Batch XML 命名空間提供使用 <job-repository> 標籤設定 JobRepository 實例的支援,如下例所示
<job-repository id="jobRepository"/>JobLauncher
JobLauncher 表示用於使用給定的一組 JobParameters 啟動 Job 的簡單介面,如下例所示
public interface JobLauncher {
public JobExecution run(Job job, JobParameters jobParameters)
throws JobExecutionAlreadyRunningException, JobRestartException,
JobInstanceAlreadyCompleteException, JobParametersInvalidException;
}預期實作從 JobRepository 取得有效的 JobExecution 並執行 Job。
ItemReader
ItemReader 是一個抽象,表示一次一個項目地檢索 Step 的輸入。當 ItemReader 耗盡它可以提供的項目時,它會透過返回 null 來指示這一點。您可以在 Readers And Writers 中找到有關 ItemReader 介面及其各種實作的更多詳細資訊。
ItemWriter
ItemWriter 是一個抽象概念,代表 Step 的輸出,一次處理一個批次或區塊的項目。 一般來說,ItemWriter 不知道接下來應該接收哪個輸入,只知道在其當前調用中傳入的項目。 您可以在讀取器與寫入器中找到關於 ItemWriter 介面及其各種實作的更多詳細資訊。
ItemProcessor
ItemProcessor 是一個抽象概念,代表項目的業務處理。 雖然 ItemReader 讀取一個項目,而 ItemWriter 寫入一個項目,但 ItemProcessor 提供了轉換或應用其他業務處理的存取點。 如果在處理項目時,確定該項目無效,則傳回 null 表示不應將該項目寫出。 您可以在讀取器與寫入器中找到關於 ItemProcessor 介面的更多詳細資訊。
Batch 命名空間
先前列出的許多領域概念需要在 Spring ApplicationContext 中進行配置。 雖然您可以標準 Bean 定義中使用上述介面的實作,但為了方便配置,已提供命名空間,如下例所示
<beans:beans xmlns="http://www.springframework.org/schema/batch"
xmlns:beans="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="
http://www.springframework.org/schema/beans
https://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/batch
https://www.springframework.org/schema/batch/spring-batch.xsd">
<job id="ioSampleJob">
<step id="step1">
<tasklet>
<chunk reader="itemReader" writer="itemWriter" commit-interval="2"/>
</tasklet>
</step>
</job>
</beans:beans>
