4.0.5
前言
Spring 資料整合歷程簡史
Spring 的資料整合歷程始於 Spring Integration。憑藉其程式設計模型,它為建置應用程式提供了連貫的開發人員體驗,這些應用程式可以採用 企業整合模式 來與外部系統 (例如資料庫、訊息代理程式等) 連接。
快轉到雲端時代,微服務已在企業環境中變得突出。Spring Boot 改變了開發人員建置應用程式的方式。透過 Spring 的程式設計模型和由 Spring Boot 處理的執行階段責任,開發獨立、生產級的基於 Spring 的微服務變得無縫。
為了將其擴展到資料整合工作負載,Spring Integration 和 Spring Boot 被整合到一個新專案中。Spring Cloud Stream 由此誕生。
透過 Spring Cloud Stream,開發人員可以
-
隔離地建置、測試和部署以資料為中心的應用程式。
-
應用現代微服務架構模式,包括透過訊息傳遞進行組合。
-
透過以事件為中心的思維來解耦應用程式責任。事件可以代表時間上發生的某件事,下游消費者應用程式可以對其做出反應,而無需知道事件的來源或生產者的身分。
-
將業務邏輯移植到訊息代理程式 (例如 RabbitMQ、Apache Kafka、Amazon Kinesis)。
-
依賴框架對常見用例的自動內容類型支援。可以擴展到不同的資料轉換類型。
-
以及更多...
快速開始
即使在深入了解任何細節之前,您也可以在不到 5 分鐘的時間內嘗試 Spring Cloud Stream,只需按照這份三步驟指南即可。
我們將向您展示如何建立一個 Spring Cloud Stream 應用程式,該應用程式接收來自您選擇的訊息傳遞中介軟體 (稍後會詳細介紹) 的訊息,並將接收到的訊息記錄到控制台中。我們稱之為 LoggingConsumer。雖然不是很實用,但它很好地介紹了一些主要概念和抽象,使您更容易理解本使用者指南的其餘部分。
三個步驟如下
使用 Spring Initializr 建立範例應用程式
首先,請造訪 Spring Initializr。從那裡,您可以產生我們的 LoggingConsumer 應用程式。若要執行此操作
-
在Dependencies區段中,開始輸入
stream。當「Cloud Stream」選項出現時,請選取它。 -
開始輸入 'kafka' 或 'rabbit'。
-
選取「Kafka」或「RabbitMQ」。
基本上,您選擇應用程式綁定的訊息傳遞中介軟體。我們建議使用您已安裝或覺得更易於安裝和執行的中介軟體。此外,正如您從 Initializr 畫面中看到的那樣,您可以選擇其他一些選項。例如,您可以選擇 Gradle 作為您的建置工具,而不是 Maven (預設)。
-
在 Artifact 欄位中,輸入 'logging-consumer'。
Artifact 欄位的值將成為應用程式名稱。如果您為中介軟體選擇了 RabbitMQ,則您的 Spring Initializr 現在應如下所示
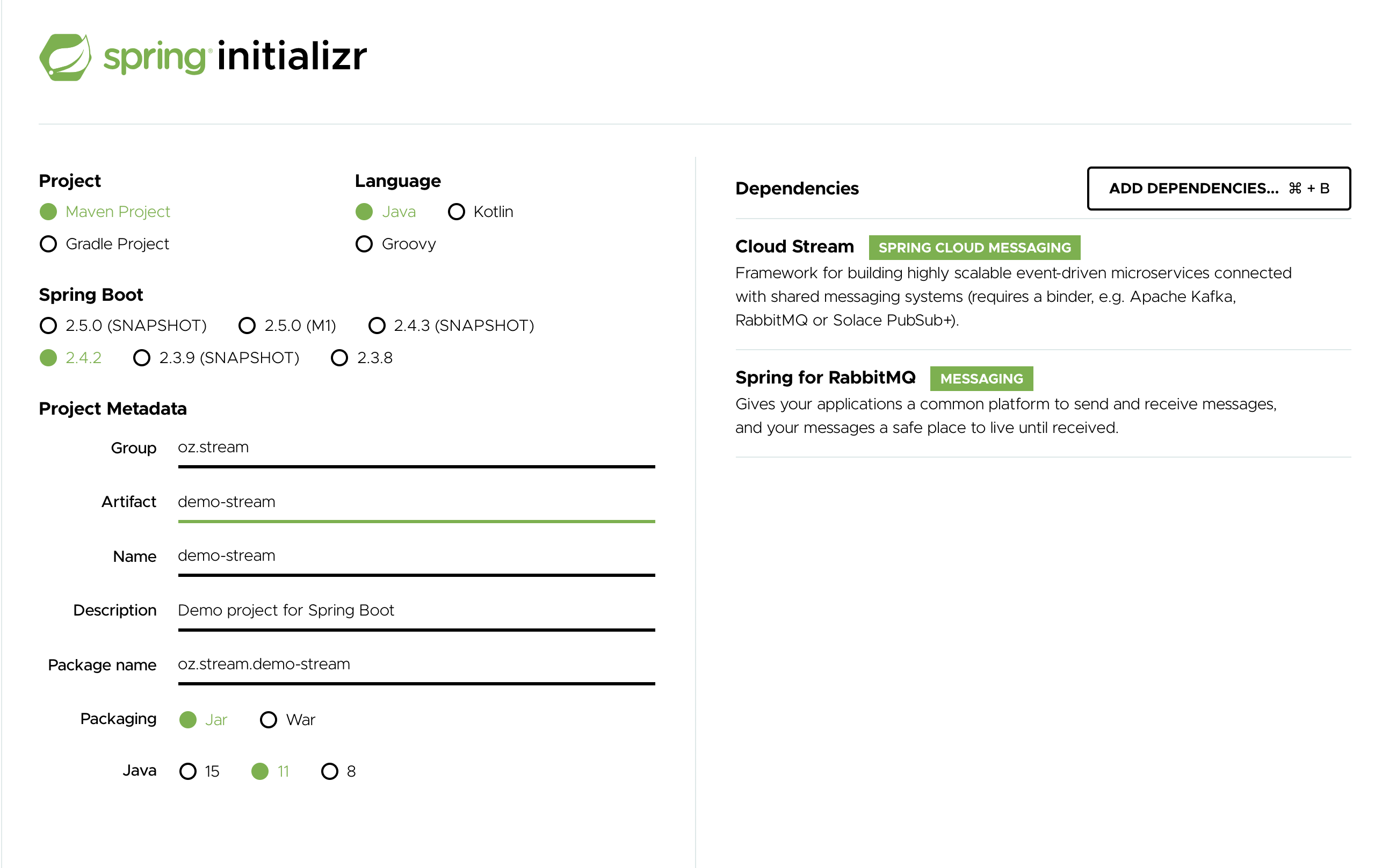
-
按一下 Generate Project 按鈕。
這樣做會將產生專案的壓縮版本下載到您的硬碟。
-
將檔案解壓縮到您要用作專案目錄的資料夾中。
| 我們鼓勵您探索 Spring Initializr 中提供的許多可能性。它可讓您建立許多不同種類的 Spring 應用程式。 |
將專案匯入您的 IDE
現在您可以將專案匯入您的 IDE。請記住,根據 IDE 的不同,您可能需要遵循特定的匯入程序。例如,根據專案的產生方式 (Maven 或 Gradle),您可能需要遵循特定的匯入程序 (例如,在 Eclipse 或 STS 中,您需要使用 File → Import → Maven → Existing Maven Project)。
匯入後,專案不得有任何類型的錯誤。此外,src/main/java 應包含 com.example.loggingconsumer.LoggingConsumerApplication。
從技術上講,此時您可以執行應用程式的主類別。它已經是一個有效的 Spring Boot 應用程式。但是,它不做任何事情,因此我們想新增一些程式碼。
新增訊息處理器、建置和執行
修改 com.example.loggingconsumer.LoggingConsumerApplication 類別,使其如下所示
@SpringBootApplication
public class LoggingConsumerApplication {
public static void main(String[] args) {
SpringApplication.run(LoggingConsumerApplication.class, args);
}
@Bean
public Consumer<Person> log() {
return person -> {
System.out.println("Received: " + person);
};
}
public static class Person {
private String name;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String toString() {
return this.name;
}
}
}
正如您從前面的列表中看到的那樣
-
我們正在使用函數式程式設計模型 (請參閱 Spring Cloud Function 支援) 來定義單個訊息處理器作為
Consumer。 -
我們依賴框架慣例將此處理器綁定到 Binder 公開的輸入目的地綁定。
這樣做還可以讓您看到框架的核心功能之一:它嘗試自動將傳入的訊息酬載轉換為 Person 類型。
您現在有一個功能齊全的 Spring Cloud Stream 應用程式,它正在監聽訊息。從這裡開始,為了簡單起見,我們假設您在步驟一中選擇了 RabbitMQ。假設您已安裝並執行 RabbitMQ,您可以透過在您的 IDE 中執行其 main 方法來啟動應用程式。
您應該看到以下輸出
--- [ main] c.s.b.r.p.RabbitExchangeQueueProvisioner : declaring queue for inbound: input.anonymous.CbMIwdkJSBO1ZoPDOtHtCg, bound to: input
--- [ main] o.s.a.r.c.CachingConnectionFactory : Attempting to connect to: [localhost:5672]
--- [ main] o.s.a.r.c.CachingConnectionFactory : Created new connection: rabbitConnectionFactory#2a3a299:0/SimpleConnection@66c83fc8. . .
. . .
--- [ main] o.s.i.a.i.AmqpInboundChannelAdapter : started inbound.input.anonymous.CbMIwdkJSBO1ZoPDOtHtCg
. . .
--- [ main] c.e.l.LoggingConsumerApplication : Started LoggingConsumerApplication in 2.531 seconds (JVM running for 2.897)前往 RabbitMQ 管理控制台或任何其他 RabbitMQ 用戶端,並向 input.anonymous.CbMIwdkJSBO1ZoPDOtHtCg 發送訊息。anonymous.CbMIwdkJSBO1ZoPDOtHtCg 部分代表群組名稱,並且是產生的,因此在您的環境中必定會有所不同。為了獲得更可預測的結果,您可以透過設定 spring.cloud.stream.bindings.input.group=hello (或您喜歡的任何名稱) 來使用明確的群組名稱。
訊息的內容應為 Person 類別的 JSON 表示,如下所示
{"name":"Sam Spade"}
然後,在您的控制台中,您應該看到
Received: Sam Spade
您也可以建置您的應用程式並將其封裝到 boot jar 中 (透過使用 ./mvnw clean install),並使用 java -jar 命令執行建置的 JAR。
現在您有一個可運作的 (儘管非常基本) Spring Cloud Stream 應用程式。
串流資料情境中的 Spring 運算式語言 (SpEL)
在本參考手冊中,您將遇到許多功能和範例,您可以在其中使用 Spring 運算式語言 (SpEL)。了解使用它時的某些限制非常重要。
SpEL 允許您存取目前的訊息以及您正在執行的應用程式內容。但是,務必了解 SpEL 可以看到哪種類型的資料,尤其是在傳入訊息的上下文中。從代理程式來看,訊息以 byte[] 的形式到達。然後,Binder 將其轉換為 Message<byte[]>,正如您所看到的,訊息的酬載保持其原始形式。訊息的標頭是 <String, Object>,其中值通常是另一個基本類型或基本類型的集合/陣列,因此是 Object。這是因為 Binder 不知道所需的輸入類型,因為它無法存取使用者程式碼 (函數)。因此,Binder 有效地交付了一個信封,其中包含酬載和一些可讀的中繼資料 (以訊息標頭的形式),就像郵差交付的信件一樣。這表示雖然可以存取訊息的酬載,但您只能以原始資料 (即 byte[]) 的形式存取它。雖然開發人員很常要求 SpEL 能夠以具體類型 (例如,Foo、Bar 等) 存取酬載物件的欄位,但您可以了解實現起來有多困難甚至不可能。以下是一個範例,用於示範問題;假設您有一個路由運算式,用於根據酬載類型路由到不同的函數。此需求將隱含酬載從 byte[] 轉換為特定類型,然後應用 SpEL。但是,為了執行此轉換,我們需要知道要傳遞給轉換器的實際類型,而該類型來自我們不知道哪個函數簽章。解決此需求的更好方法是將類型資訊作為訊息標頭傳遞 (例如,application/json;type=foo.bar.Baz)。您將獲得清晰可讀的字串值,該值可以在一年內存取和評估,並且易於閱讀 SpEL 運算式。
此外,將酬載用於路由決策被認為是非常糟糕的做法,因為酬載被視為特權資料 - 僅供最終接收者讀取的資料。再次,使用郵件遞送類比,您不會希望郵差打開您的信封並閱讀信件內容以做出一些遞送決策。相同的概念在此適用,尤其是在產生訊息時相對容易包含此類資訊的情況下。它強制執行與透過網路傳輸的資料設計相關的特定程度的紀律,以及哪些資料片段可以被視為公開,哪些是特權。
Spring Cloud Stream 簡介
Spring Cloud Stream 是一個用於建置訊息驅動微服務應用程式的框架。Spring Cloud Stream 建構於 Spring Boot 之上,以建立獨立、生產級的 Spring 應用程式,並使用 Spring Integration 來提供與訊息代理程式的連線能力。它為來自多家供應商的中介軟體提供固定的組態,引入了持久發布-訂閱語意、消費者群組和分割區的概念。
透過將 spring-cloud-stream 相依性新增到應用程式的類別路徑中,您可以立即連線到提供的 spring-cloud-stream Binder (稍後會詳細介紹) 公開的訊息代理程式,並且您可以實作您的功能需求,該需求由 java.util.function.Function 執行 (基於傳入的訊息)。
以下列表顯示了一個快速範例
@SpringBootApplication
public class SampleApplication {
public static void main(String[] args) {
SpringApplication.run(SampleApplication.class, args);
}
@Bean
public Function<String, String> uppercase() {
return value -> value.toUpperCase();
}
}
以下列表顯示了對應的測試
@SpringBootTest(classes = SampleApplication.class)
@Import({TestChannelBinderConfiguration.class})
class BootTestStreamApplicationTests {
@Autowired
private InputDestination input;
@Autowired
private OutputDestination output;
@Test
void contextLoads() {
input.send(new GenericMessage<byte[]>("hello".getBytes()));
assertThat(output.receive().getPayload()).isEqualTo("HELLO".getBytes());
}
}
主要概念
Spring Cloud Stream 提供了許多抽象和基本元素,簡化了訊息驅動微服務應用程式的編寫。本節概述以下內容
應用程式模型
Spring Cloud Stream 應用程式由中介軟體中性的核心組成。應用程式透過在外部代理程式公開的目的地與程式碼中的輸入/輸出引數之間建立綁定來與外部世界通訊。建立綁定所需的特定於代理程式的詳細資訊由特定於中介軟體的 Binder 實作處理。
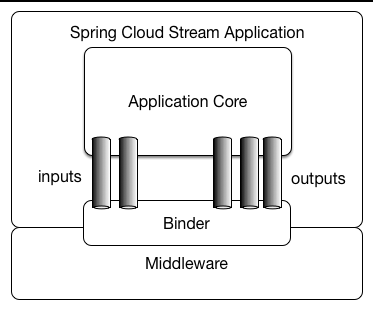
Fat JAR
Spring Cloud Stream 應用程式可以在獨立模式下從您的 IDE 執行以進行測試。若要在生產環境中執行 Spring Cloud Stream 應用程式,您可以使用 Maven 或 Gradle 提供的標準 Spring Boot 工具來建立可執行 (或「fat」) JAR。請參閱 Spring Boot 參考指南 以了解更多詳細資訊。
Binder 抽象化
Spring Cloud Stream 為 Kafka 和 Rabbit MQ 提供 Binder 實作。該框架還包括一個測試 Binder,用於整合測試您的應用程式作為 spring-cloud-stream 應用程式。請參閱 測試 章節以了解更多詳細資訊。
Binder 抽象化也是框架的擴展點之一,這表示您可以在 Spring Cloud Stream 之上實作您自己的 Binder。在 How to create a Spring Cloud Stream Binder from scratch 文章中,一位社群成員詳細記錄了實作自訂 Binder 所需的一組步驟,並提供了一個範例。這些步驟也在 實作自訂 Binder 章節中重點介紹。
Spring Cloud Stream 使用 Spring Boot 進行組態,而 Binder 抽象化使 Spring Cloud Stream 應用程式可以靈活地連接到中介軟體。例如,部署人員可以在執行階段動態選擇外部目的地 (例如 Kafka 主題或 RabbitMQ 交換器) 與訊息處理器的輸入和輸出 (例如函數的輸入參數及其傳回引數) 之間的對應。此類組態可以透過外部組態屬性以及 Spring Boot 支援的任何形式提供 (包括應用程式引數、環境變數和 application.yml 或 application.properties 檔案)。在 Spring Cloud Stream 簡介 章節中的接收器範例中,將 spring.cloud.stream.bindings.input.destination 應用程式屬性設定為 raw-sensor-data 會使其從 raw-sensor-data Kafka 主題或從綁定到 raw-sensor-data RabbitMQ 交換器的佇列中讀取。
Spring Cloud Stream 自動偵測並使用在類別路徑上找到的 Binder。您可以將不同類型的中介軟體與相同的程式碼一起使用。若要執行此操作,請在建置時包含不同的 Binder。對於更複雜的用例,您也可以將多個 Binder 與您的應用程式一起封裝,並使其在執行階段選擇 Binder (甚至是否對不同的綁定使用不同的 Binder)。
持久發布-訂閱支援
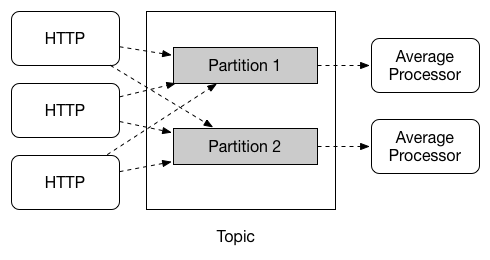
應用程式之間的通訊遵循發布-訂閱模型,其中資料透過共用主題廣播。這可以在下圖中看到,該圖顯示了一組互動式 Spring Cloud Stream 應用程式的典型部署。
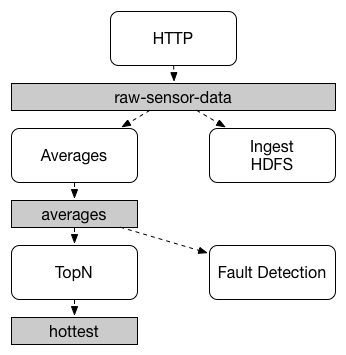
感測器報告給 HTTP 端點的資料會傳送到名為 raw-sensor-data 的通用目的地。從目的地,它由一個微服務應用程式獨立處理,該應用程式計算時間視窗平均值,另一個微服務應用程式將原始資料擷取到 HDFS (Hadoop 分散式檔案系統) 中。為了處理資料,兩個應用程式都在執行階段將主題宣告為其輸入。
發布-訂閱通訊模型降低了生產者和消費者的複雜性,並允許將新應用程式新增到拓撲中,而不會中斷現有流程。例如,在計算平均值的應用程式的下游,您可以新增一個應用程式來計算最高溫度值以進行顯示和監控。然後,您可以新增另一個應用程式,該應用程式解釋相同的平均值流程以進行故障偵測。透過共用主題而不是點對點佇列進行所有通訊,可以減少微服務之間的耦合。
雖然發布-訂閱訊息傳遞的概念並不新鮮,但 Spring Cloud Stream 更進一步,使其成為其應用程式模型的固定選擇。透過使用原生中介軟體支援,Spring Cloud Stream 還簡化了跨不同平台使用發布-訂閱模型。
消費者群組
雖然發布-訂閱模型可以輕鬆透過共用主題連接應用程式,但透過建立給定應用程式的多個實例來擴展規模的能力同樣重要。在這樣做時,應用程式的不同實例被置於競爭消費者關係中,其中僅預期其中一個實例處理給定的訊息。
Spring Cloud Stream 透過消費者群組的概念對此行為進行建模。(Spring Cloud Stream 消費者群組與 Kafka 消費者群組相似並受其啟發。) 每個消費者綁定都可以使用 spring.cloud.stream.bindings.<bindingName>.group 屬性來指定群組名稱。對於下圖中顯示的消費者,此屬性將設定為 spring.cloud.stream.bindings.<bindingName>.group=hdfsWrite 或 spring.cloud.stream.bindings.<bindingName>.group=average。
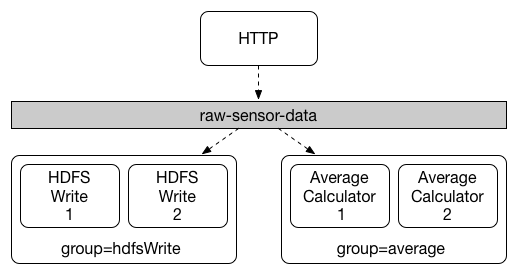
訂閱給定目的地的所有群組都會收到已發布資料的副本,但每個群組中只有一個成員會從該目的地接收給定的訊息。預設情況下,當未指定群組時,Spring Cloud Stream 會將應用程式指派給匿名且獨立的單成員消費者群組,該群組與所有其他消費者群組處於發布-訂閱關係中。
消費者類型
支援兩種消費者類型
-
訊息驅動 (有時稱為非同步)
-
輪詢 (有時稱為同步)
在 2.0 版之前,僅支援非同步消費者。訊息會在可用且有執行緒可用於處理時立即傳遞。
當您希望控制訊息的處理速率時,您可能需要使用同步消費者。
持久性
與 Spring Cloud Stream 的固定應用程式模型一致,消費者群組訂閱是持久的。也就是說,Binder 實作可確保群組訂閱是持久的,並且一旦至少為群組建立了一個訂閱,即使在群組中的所有應用程式都停止時傳送訊息,該群組也會收到訊息。
|
匿名訂閱本質上是非持久的。對於某些 Binder 實作 (例如 RabbitMQ),可以具有非持久群組訂閱。 |
一般而言,在將應用程式綁定到給定目的地時,最好始終指定消費者群組。在擴展 Spring Cloud Stream 應用程式時,您必須為其每個輸入綁定指定一個消費者群組。這樣做可以防止應用程式的實例接收重複的訊息 (除非需要這種行為,這是不常見的)。
分割區支援
Spring Cloud Stream 提供支援,用於在給定應用程式的多個實例之間分割資料。在分割區情境中,實體通訊媒體 (例如代理程式主題) 被視為結構化為多個分割區。一個或多個生產者應用程式實例將資料傳送到多個消費者應用程式實例,並確保具有共同特徵識別的資料由相同的消費者實例處理。
Spring Cloud Stream 提供了一個通用抽象,用於以統一的方式實作分割區處理用例。因此,無論代理程式本身是否自然分割區 (例如 Kafka) 或不是 (例如 RabbitMQ),都可以使用分割區。
分割區是狀態處理中的一個關鍵概念,在狀態處理中,確保所有相關資料一起處理至關重要 (無論是出於效能還是連貫性原因)。例如,在時間視窗平均值計算範例中,重要的是來自任何給定感測器的所有量測都由相同的應用程式實例處理。
| 若要設定分割區處理情境,您必須組態資料生產端和資料消費端。 |
程式設計模型
若要了解程式設計模型,您應該熟悉以下核心概念
-
目的地 Binder:負責提供與外部訊息傳遞系統整合的元件。
-
綁定:外部訊息傳遞系統與應用程式提供的訊息生產者和消費者之間的橋樑 (由目的地 Binder 建立)。
-
訊息:生產者和消費者用於與目的地 Binder 通訊的規範資料結構 (因此也透過外部訊息傳遞系統與其他應用程式通訊)。
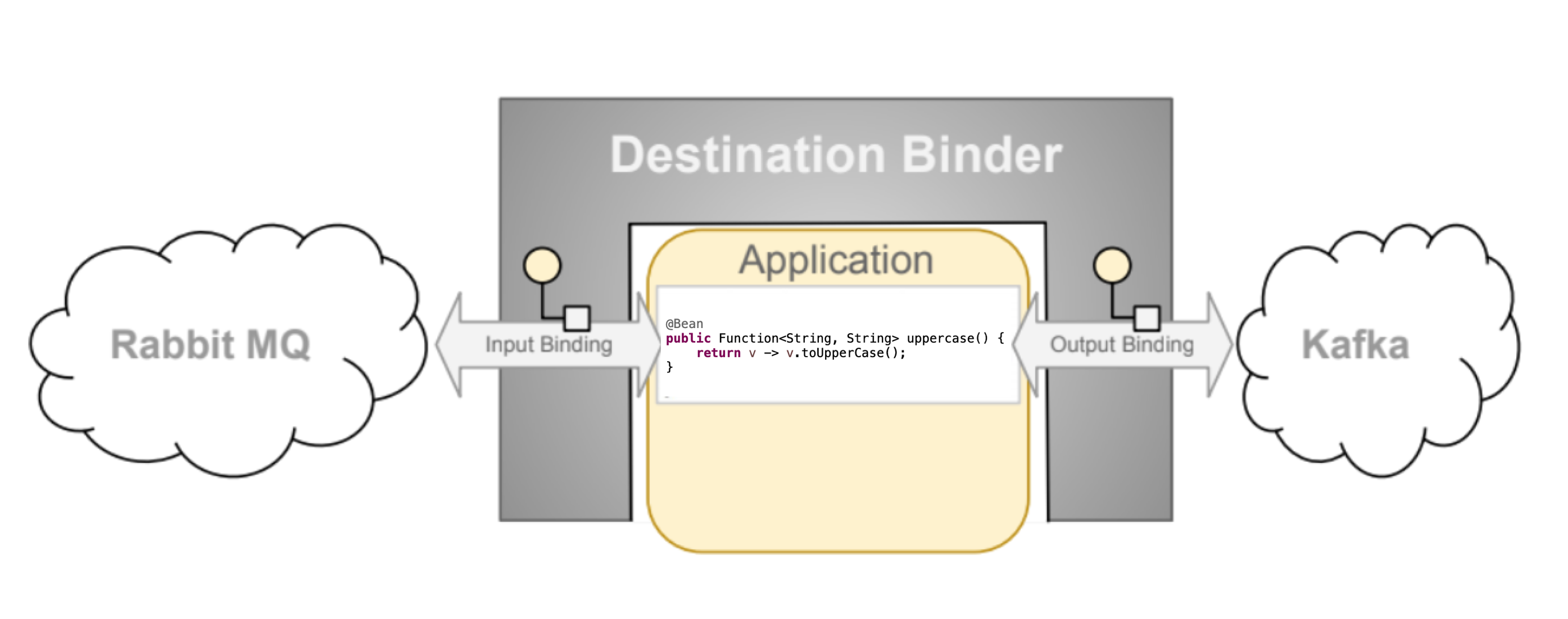
目的地 Binder
目的地 Binder 是 Spring Cloud Stream 的擴展元件,負責提供必要的組態和實作,以促進與外部訊息傳遞系統的整合。此整合負責連線、委派以及將訊息路由到生產者和消費者以及從生產者和消費者路由訊息、資料類型轉換、使用者程式碼的調用等等。
Binder 處理了許多否則會落在您肩上的樣板責任。但是,為了完成此操作,Binder 仍然需要一些協助,形式為來自使用者的最簡化但必要的指令集,這些指令通常以某種類型的綁定組態的形式出現。
雖然討論所有可用的 Binder 和綁定組態選項不在本節的範圍內 (手冊的其餘部分廣泛涵蓋了它們),但作為一個概念,綁定確實需要特別注意。下一節將詳細討論它。
綁定
如前所述,綁定在外部訊息傳遞系統 (例如,佇列、主題等) 與應用程式提供的生產者和消費者之間提供橋樑。
以下範例顯示了一個完全組態且功能正常的 Spring Cloud Stream 應用程式,該應用程式接收訊息的酬載作為 String 類型 (請參閱 內容類型協商 章節),將其記錄到控制台中,並在將其轉換為大寫後向下游傳送。
@SpringBootApplication
public class SampleApplication {
public static void main(String[] args) {
SpringApplication.run(SampleApplication.class, args);
}
@Bean
public Function<String, String> uppercase() {
return value -> {
System.out.println("Received: " + value);
return value.toUpperCase();
};
}
}
上面的範例看起來與任何普通的 spring-boot 應用程式沒有什麼不同。它定義了一個 Function 類型的單個 bean,僅此而已。那麼,它是如何成為 spring-cloud-stream 應用程式的呢?它之所以成為 spring-cloud-stream 應用程式,僅僅是因為類別路徑上存在 spring-cloud-stream 和 binder 相依性以及自動組態類別,從而有效地將您的 boot 應用程式的內容設定為 spring-cloud-stream 應用程式。在此內容中,Supplier、Function 或 Consumer 類型的 bean 被視為事實上的訊息處理器,觸發綁定到提供的 Binder 公開的目的地,並遵循某些命名慣例和規則,以避免額外的組態。
綁定和綁定名稱
綁定是一種抽象,表示 Binder 公開的來源和目標與使用者程式碼之間的橋樑。此抽象具有名稱,雖然我們盡力限制執行 spring-cloud-stream 應用程式所需的組態,但在需要額外的每個綁定組態的情況下,了解此類名稱是必要的。
在本手冊中,您將看到組態屬性的範例,例如 spring.cloud.stream.bindings.input.destination=myQueue。此屬性名稱中的 input 段是我們所說的綁定名稱,它可以透過多種機制衍生而來。以下子章節將描述 spring-cloud-stream 用於控制綁定名稱的命名慣例和組態元素。
如果您的綁定名稱具有特殊字元,例如 . 字元,則需要用括號 ([]) 將綁定金鑰括起來,然後用引號將其包裝起來。例如 spring.cloud.stream.bindings."[my.output.binding.key]".destination。 |
函數式綁定名稱
與先前版本的 spring-cloud-stream 中使用的基於註解的支援 (傳統) 所需的明確命名不同,函數式程式設計模型在綁定名稱方面預設為簡單的慣例,從而大大簡化了應用程式組態。讓我們看一下第一個範例
@SpringBootApplication
public class SampleApplication {
@Bean
public Function<String, String> uppercase() {
return value -> value.toUpperCase();
}
}
在前面的範例中,我們有一個應用程式,其中包含充當訊息處理器的單個函數。作為 Function,它具有輸入和輸出。用於命名輸入和輸出綁定的命名慣例如下
-
輸入 -
<functionName> + -in- + <index> -
輸出 -
<functionName> + -out- + <index>
in 和 out 對應於綁定的類型 (例如輸入或輸出)。index 是輸入或輸出綁定的索引。對於典型的單一輸入/輸出函數,它始終為 0,因此僅與具有多個輸入和輸出引數的函數相關。
因此,舉例來說,如果您想要將此函數的輸入對應到名為 "my-topic" 的遠端目的地 (例如,主題、佇列等),您可以使用以下屬性來完成
--spring.cloud.stream.bindings.uppercase-in-0.destination=my-topic
請注意 uppercase-in-0 如何用作屬性名稱中的區段。uppercase-out-0 的情況也是如此。
描述性綁定名稱
有時候,為了提高可讀性,您可能會想要為您的綁定提供更具描述性的名稱 (例如 'account'、'orders' 等)。另一種看待它的方式是,您可以將隱含綁定名稱對應到顯式綁定名稱。您可以使用 spring.cloud.stream.function.bindings.<binding-name> 屬性來做到這一點。此屬性也為現有應用程式提供了遷移路徑,這些應用程式依賴於需要顯式名稱的基於自訂介面的綁定。
例如,
--spring.cloud.stream.function.bindings.uppercase-in-0=input
在前面的範例中,您已對應並有效地將 uppercase-in-0 綁定名稱重新命名為 input。現在,所有組態屬性都可以參考 input 綁定名稱 (例如,--spring.cloud.stream.bindings.input.destination=my-topic)。
雖然描述性綁定名稱可以增強組態的可讀性,但它們也透過將隱含綁定名稱對應到顯式綁定名稱來建立另一個層級的誤導。由於所有後續的組態屬性都將使用顯式綁定名稱,因此您必須始終參考此 'bindings' 屬性,以關聯它實際對應到哪個函數。我們認為對於大多數情況 (除了函數組合之外),這可能有點矯枉過正,因此,我們的建議是完全避免使用它,特別是因為不使用它可以在綁定器目的地和綁定名稱之間提供清晰的路徑,例如 spring.cloud.stream.bindings.uppercase-in-0.destination=sample-topic,您可以在其中清楚地將 uppercase 函數的輸入與 sample-topic 目的地相關聯。 |
有關屬性和其他組態選項的更多資訊,請參閱組態選項章節。
顯式綁定建立
在前一節中,我們解釋了綁定是如何隱含地建立的,這是由您的應用程式提供的 Function、Supplier 或 Consumer Bean 的名稱驅動的。但是,有時您可能需要顯式建立綁定,其中綁定不與任何函數相關聯。這通常是為了支援透過 StreamBridge 與其他框架的整合而完成的。
Spring Cloud Stream 允許您透過 spring.cloud.stream.input-bindings 和 spring.cloud.stream.output-bindings 屬性顯式定義輸入和輸出綁定。請注意屬性名稱中的複數形式,允許您透過簡單地使用 ; 作為分隔符號來定義多個綁定。請查看以下測試案例作為範例
@Test
public void testExplicitBindings() {
try (ConfigurableApplicationContext context = new SpringApplicationBuilder(
TestChannelBinderConfiguration.getCompleteConfiguration(EmptyConfiguration.class))
.web(WebApplicationType.NONE)
.run("--spring.jmx.enabled=false",
"--spring.cloud.stream.input-bindings=fooin;barin",
"--spring.cloud.stream.output-bindings=fooout;barout")) {
. . .
}
}
@EnableAutoConfiguration
@Configuration
public static class EmptyConfiguration {
}
如您所見,我們宣告了兩個輸入綁定和兩個輸出綁定,而我們的組態沒有定義任何函數,但我們仍然能夠成功建立這些綁定並存取其對應的通道。
生產和消費訊息
您可以透過簡單地編寫函數並將它們公開為 @Bean 來編寫 Spring Cloud Stream 應用程式。您也可以使用基於 Spring Integration 註解的組態或基於 Spring Cloud Stream 註解的組態,儘管從 spring-cloud-stream 3.x 開始,我們建議使用函數式實作。
Spring Cloud Function 支援
概述
自 Spring Cloud Stream v2.1 以來,定義串流處理器和來源的另一種替代方案是使用對 Spring Cloud Function 的內建支援,其中它們可以表示為 java.util.function.[Supplier/Function/Consumer] 類型的 Bean。
若要指定要綁定到綁定公開的外部目的地的函數式 Bean,您必須提供 spring.cloud.function.definition 屬性。
如果您只有單一 java.util.function.[Supplier/Function/Consumer] 類型的 Bean,您可以跳過 spring.cloud.function.definition 屬性,因為此類函數式 Bean 將會自動探索。但是,建議使用此屬性以避免任何混淆。有時這種自動探索可能會造成阻礙,因為單一 java.util.function.[Supplier/Function/Consumer] 類型的 Bean 可能出於處理訊息以外的目的而存在,但由於它是單一 Bean,因此會自動探索和自動綁定。對於這些罕見的情況,您可以透過提供 spring.cloud.stream.function.autodetect 屬性並將值設定為 false 來停用自動探索。 |
以下範例展示了將訊息處理器公開為 java.util.function.Function 的應用程式,有效地透過充當資料的消費者和生產者來支援直通語意。
@SpringBootApplication
public class MyFunctionBootApp {
public static void main(String[] args) {
SpringApplication.run(MyFunctionBootApp.class);
}
@Bean
public Function<String, String> toUpperCase() {
return s -> s.toUpperCase();
}
}
在前面的範例中,我們定義了一個名為 toUpperCase 的 java.util.function.Function 類型的 Bean,作為訊息處理器,其 'input' 和 'output' 必須綁定到提供的目的地綁定器公開的外部目的地。預設情況下,'input' 和 'output' 綁定名稱將為 toUpperCase-in-0 和 toUpperCase-out-0。有關用於建立綁定名稱的命名慣例的詳細資訊,請參閱函數式綁定名稱章節。
以下是簡單函數式應用程式的範例,以支援其他語意
以下範例展示了公開為 java.util.function.Supplier 的來源語意
@SpringBootApplication
public static class SourceFromSupplier {
@Bean
public Supplier<Date> date() {
return () -> new Date(12345L);
}
}
以下範例展示了公開為 java.util.function.Consumer 的接收器語意
@SpringBootApplication
public static class SinkFromConsumer {
@Bean
public Consumer<String> sink() {
return System.out::println;
}
}
供應器 (來源)
當涉及如何觸發 Function 和 Consumer 的調用時,它們非常簡單明瞭。它們是根據傳送到它們綁定的目的地的資料 (事件) 來觸發的。換句話說,它們是經典的事件驅動元件。
但是,當涉及觸發時,Supplier 屬於其自己的類別。由於它在定義上是資料的來源 (起源),因此它不訂閱任何入站目的地,因此必須由其他機制觸發。此外,還有關於 Supplier 實作的問題,它可以是命令式或反應式,這與此類供應器的觸發直接相關。
考慮以下範例
@SpringBootApplication
public static class SupplierConfiguration {
@Bean
public Supplier<String> stringSupplier() {
return () -> "Hello from Supplier";
}
}
每當調用前述 Supplier Bean 的 get() 方法時,它都會產生一個字串。但是,誰調用此方法以及調用頻率如何?框架提供了一個預設輪詢機制 (回答了 "誰?" 的問題),該機制將觸發供應器的調用,並且預設情況下,它將每秒執行一次 (回答了 "多久?" 的問題)。換句話說,上述組態每秒產生一條訊息,並且每條訊息都傳送到綁定器公開的 output 目的地。若要了解如何自訂輪詢機制,請參閱輪詢組態屬性章節。
考慮另一個範例
@SpringBootApplication
public static class SupplierConfiguration {
@Bean
public Supplier<Flux<String>> stringSupplier() {
return () -> Flux.fromStream(Stream.generate(new Supplier<String>() {
@Override
public String get() {
try {
Thread.sleep(1000);
return "Hello from Supplier";
} catch (Exception e) {
// ignore
}
}
})).subscribeOn(Schedulers.elastic()).share();
}
}
前述 Supplier Bean 採用了反應式程式設計風格。通常,與命令式供應器不同,它應該只觸發一次,因為調用其 get() 方法會產生 (供應) 連續的訊息串流,而不是單個訊息。
框架識別程式設計風格的差異,並保證此類供應器僅觸發一次。
但是,想像一下您想要輪詢某些資料來源並傳回代表結果集的有限資料串流的使用案例。反應式程式設計風格是此類供應器的完美機制。但是,鑑於產生串流的有限性質,此類供應器仍然需要定期調用。
考慮以下範例,它透過產生有限的資料串流來模擬此類使用案例
@SpringBootApplication
public static class SupplierConfiguration {
@PollableBean
public Supplier<Flux<String>> stringSupplier() {
return () -> Flux.just("hello", "bye");
}
}
Bean 本身使用 PollableBean 註解 (@Bean 的子集) 進行註解,從而向框架發出訊號,表示雖然此類供應器的實作是反應式的,但仍然需要輪詢。
在 PollableBean 中定義了一個 splittable 屬性,它向此註解的後處理器發出訊號,表示註解元件產生的結果必須分割,並且預設情況下設定為 true。這表示框架將分割傳回值,並將每個項目作為單獨的訊息發送出去。如果這不是所需的行為,您可以將其設定為 false,在這種情況下,此類供應器只會傳回產生的 Flux 而不進行分割。 |
供應器 & 線程
正如您現在所了解的,與由事件觸發的 Function 和 Consumer (它們具有輸入資料) 不同,Supplier 沒有任何輸入,因此由不同的機制觸發 - 輪詢器,它可能具有不可預測的線程機制。雖然線程機制的詳細資訊在大多數情況下與函數的下游執行無關,但在某些情況下可能會出現問題,尤其是在與可能對線程親和性有某些期望的整合框架一起使用時。例如,Spring Cloud Sleuth 依賴於儲存在線程本機中的追蹤資料。對於這些情況,我們有另一種機制,即 StreamBridge,使用者可以更好地控制線程機制。您可以在將任意資料發送到輸出 (例如,外部事件驅動來源) 章節中取得更多詳細資訊。 |
消費者 (反應式)
反應式 Consumer 有點特殊,因為它具有 void 傳回類型,框架無法參考訂閱。您很可能不需要編寫 Consumer<Flux<?>>,而是將其編寫為 Function<Flux<?>, Mono<Void>>,並在您的串流上調用 then 運算子作為最後一個運算子。
例如
public Function<Flux<?>, Mono<Void>> consumer() {
return flux -> flux.map(..).filter(..).then();
}
但是,如果您確實需要編寫顯式的 Consumer<Flux<?>>,請記住訂閱傳入的 Flux。
此外,請記住,當混合反應式和命令式函數時,相同的規則適用於函數組合。Spring Cloud Function 確實支援將反應式函數與命令式函數組合,但是您必須注意某些限制。例如,假設您已將反應式函數與命令式消費者組合。此類組合的結果是反應式 Consumer。但是,由於無法訂閱此類消費者 (如本節稍早討論),因此此限制只能透過使您的消費者成為反應式並手動訂閱 (如稍早討論),或將您的函數更改為命令式來解決。
輪詢組態屬性
以下屬性由 Spring Cloud Stream 公開,並以 spring.integration.poller. 為前綴。
- fixedDelay
-
預設輪詢器的固定延遲 (以毫秒為單位)。
預設值:1000L。
- maxMessagesPerPoll
-
預設輪詢器的每個輪詢事件的最大訊息數。
預設值:1L。
- cron
-
Cron 觸發器的 Cron 運算式值。
預設值:none。
- initialDelay
-
定期觸發器的初始延遲。
預設值:0。
- timeUnit
-
套用於延遲值的 TimeUnit。
預設值:MILLISECONDS。
例如,--spring.integration.poller.fixed-delay=2000 將輪詢器間隔設定為每兩秒輪詢一次。
每個綁定的輪詢組態
上一節展示了如何組態將套用於所有綁定的單一預設輪詢器。雖然它非常適合 spring-cloud-stream 專為微服務設計的模型,其中每個微服務代表單一元件 (例如,Supplier),因此預設輪詢器組態已足夠,但在某些邊緣情況下,您可能有多個元件需要不同的輪詢組態
對於這種情況,請使用每個綁定的方式來組態輪詢器。例如,假設您有一個輸出綁定 supply-out-0。在這種情況下,您可以使用 spring.cloud.stream.bindings.supply-out-0.producer.poller.. 前綴為此綁定組態輪詢器 (例如,spring.cloud.stream.bindings.supply-out-0.producer.poller.fixed-delay=2000)。
將任意資料發送到輸出 (例如,外部事件驅動來源)
在某些情況下,資料的實際來源可能來自外部 (外部) 系統,而不是綁定器。例如,資料的來源可能是經典的 REST 端點。我們如何使用 spring-cloud-stream 使用的函數式機制來橋接此類來源?
Spring Cloud Stream 提供了兩種機制,因此讓我們更詳細地了解它們
在這裡,對於兩個範例,我們都將使用名為 delegateToSupplier 的標準 MVC 端點方法,該方法綁定到根 Web 內容,並透過 StreamBridge 機制將傳入的請求委派到串流。
@SpringBootApplication
@Controller
public class WebSourceApplication {
public static void main(String[] args) {
SpringApplication.run(WebSourceApplication.class, "--spring.cloud.stream.output-bindings=toStream");
}
@Autowired
private StreamBridge streamBridge;
@RequestMapping
@ResponseStatus(HttpStatus.ACCEPTED)
public void delegateToSupplier(@RequestBody String body) {
System.out.println("Sending " + body);
streamBridge.send("toStream", body);
}
}
在這裡,我們自動裝配了一個 StreamBridge Bean,它允許我們將資料發送到輸出綁定,從而有效地將非串流應用程式與 spring-cloud-stream 橋接起來。請注意,前面的範例沒有定義任何來源函數 (例如,Supplier Bean),這使得框架無法提前建立來源綁定的觸發器,這對於組態包含函數 Bean 的情況來說是典型的。這沒關係,因為 StreamBridge 將在第一次調用其 send(..) 操作時啟動輸出綁定的建立 (以及必要的目的地自動佈建),並將其快取以供後續重複使用 (有關更多詳細資訊,請參閱StreamBridge 和動態目的地)。
但是,如果您想要在初始化 (啟動) 時預先建立輸出綁定,您可以受益於 spring.cloud.stream.output-bindings 屬性,您可以在其中宣告來源的名稱。提供的名稱將用作建立來源綁定的觸發器。您可以使用 ; 來表示多個來源 (多個輸出綁定) (例如,--spring.cloud.stream.output-bindings=foo;bar)
此外,請注意 streamBridge.send(..) 方法採用 Object 作為資料。這表示您可以將 POJO 或 Message 發送到它,並且它將經歷與從任何 Function 或 Supplier 發送輸出相同的例行程序,從而提供與函數相同的層級的一致性。這表示輸出類型轉換、分割等都會像從函數產生的輸出一樣被遵守。
StreamBridge 和動態目的地
對於輸出目的地在事前未知的情況,StreamBridge 也可以使用,這種類似於從消費者路由章節中描述的使用案例。
讓我們看一個範例
@SpringBootApplication
@Controller
public class WebSourceApplication {
public static void main(String[] args) {
SpringApplication.run(WebSourceApplication.class, args);
}
@Autowired
private StreamBridge streamBridge;
@RequestMapping
@ResponseStatus(HttpStatus.ACCEPTED)
public void delegateToSupplier(@RequestBody String body) {
System.out.println("Sending " + body);
streamBridge.send("myDestination", body);
}
}
如您所見,前面的範例與先前的範例非常相似,除了透過 spring.cloud.stream.output-bindings 屬性提供的顯式綁定指令 (未提供)。在這裡,我們將資料發送到 myDestination 名稱,該名稱不存在作為綁定。因此,此類名稱將被視為動態目的地,如從消費者路由章節中所述。
在前面的範例中,我們使用 ApplicationRunner 作為外部來源來饋送串流。
一個更實際的範例,其中外部來源是 REST 端點。
@SpringBootApplication
@Controller
public class WebSourceApplication {
public static void main(String[] args) {
SpringApplication.run(WebSourceApplication.class);
}
@Autowired
private StreamBridge streamBridge;
@RequestMapping
@ResponseStatus(HttpStatus.ACCEPTED)
public void delegateToSupplier(@RequestBody String body) {
streamBridge.send("myBinding", body);
}
}
如您所見,在 delegateToSupplier 方法內部,我們使用 StreamBridge 將資料發送到 myBinding 綁定。在這裡,您還可以受益於 StreamBridge 的動態功能,如果 myBinding 不存在,它將自動建立並快取,否則將使用現有的綁定。
快取動態目的地 (綁定) 可能會導致記憶體洩漏,如果存在許多動態目的地。為了對其進行一定程度的控制,我們為輸出綁定提供了一個自我清除快取機制,預設快取大小為 10。這表示如果您的動態目的地大小超過該數字,則現有的綁定可能會被逐出,因此需要重新建立,這可能會導致輕微的效能下降。您可以透過 spring.cloud.stream.dynamic-destination-cache-size 屬性將其設定為所需的值來增加快取大小。 |
curl -H "Content-Type: text/plain" -X POST -d "hello from the other side" http://localhost:8080/
透過展示兩個範例,我們想要強調該方法適用於任何類型的外部來源。
如果您使用的是 Solace PubSub+ 綁定器,Spring Cloud Stream 保留了 scst_targetDestination 標頭 (可透過 BinderHeaders.TARGET_DESTINATION 擷取),它允許將訊息從其綁定的組態目的地重新導向到此標頭指定的目標目的地。這允許綁定器管理發佈到動態目的地所需的資源,從而減輕框架的負擔,並避免了先前注意事項中提到的快取問題。更多資訊請參閱這裡。 |
StreamBridge 的輸出內容類型
如果需要,您也可以使用以下方法簽名提供特定的內容類型 public boolean send(String bindingName, Object data, MimeType outputContentType)。或者,如果您將資料作為 Message 發送,則將遵守其內容類型。
將特定綁定器類型與 StreamBridge 搭配使用
Spring Cloud Stream 支援多個綁定器情境。例如,您可能會從 Kafka 接收資料並將其發送到 RabbitMQ。
有關多個綁定器情境的更多資訊,請參閱綁定器章節,特別是類路徑上的多個綁定器
如果您計劃使用 StreamBridge 並且您的應用程式中組態了多個綁定器,您還必須告訴 StreamBridge 要使用哪個綁定器。為此,send 方法還有另外兩種變體
public boolean send(String bindingName, @Nullable String binderType, Object data)
public boolean send(String bindingName, @Nullable String binderType, Object data, MimeType outputContentType)
如您所見,您可以提供一個額外的引數 - binderType,告訴 BindingService 在建立動態綁定時要使用哪個綁定器。
對於使用 spring.cloud.stream.output-bindings 屬性的情況,或綁定已在不同綁定器下建立的情況,binderType 引數將不起作用。 |
將通道攔截器與 StreamBridge 搭配使用
由於 StreamBridge 使用 MessageChannel 來建立輸出綁定,因此您可以在透過 StreamBridge 發送資料時啟動通道攔截器。由應用程式決定要在 StreamBridge 上套用哪些通道攔截器。除非通道攔截器使用 @GlobalChannelInterceptor(patterns = "*") 進行註解,否則 Spring Cloud Stream 不會將偵測到的所有通道攔截器注入到 StreamBridge 中。
讓我們假設您的應用程式中有以下兩個不同的 StreamBridge 綁定。
streamBridge.send("foo-out-0", message);
和
streamBridge.send("bar-out-0", message);
現在,如果您想要在兩個 StreamBridge 綁定上都套用通道攔截器,那麼您可以宣告以下 GlobalChannelInterceptor Bean。
@Bean
@GlobalChannelInterceptor(patterns = "*")
public ChannelInterceptor customInterceptor() {
return new ChannelInterceptor() {
@Override
public Message<?> preSend(Message<?> message, MessageChannel channel) {
...
}
};
}但是,如果您不喜歡上面的全域方法,並且想要為每個綁定都擁有專用的攔截器,那麼您可以執行以下操作。
@Bean
@GlobalChannelInterceptor(patterns = "foo-*")
public ChannelInterceptor fooInterceptor() {
return new ChannelInterceptor() {
@Override
public Message<?> preSend(Message<?> message, MessageChannel channel) {
...
}
};
}和
@Bean
@GlobalChannelInterceptor(patterns = "bar-*")
public ChannelInterceptor barInterceptor() {
return new ChannelInterceptor() {
@Override
public Message<?> preSend(Message<?> message, MessageChannel channel) {
...
}
};
}您可以靈活地使模式更嚴格或根據您的業務需求進行自訂。
透過這種方法,應用程式可以決定要將哪些攔截器注入到 StreamBridge 中,而不是套用所有可用的攔截器。
StreamBridge 透過 StreamOperations 介面提供了一個契約,其中包含 StreamBridge 的所有 send 方法。因此,應用程式可以選擇使用 StreamOperations 進行自動裝配。當需要透過為 StreamOperations 介面提供模擬或其他類似機制來單元測試使用 StreamBridge 的程式碼時,這非常方便。 |
反應式函數支援
由於 Spring Cloud Function 是建立在 Project Reactor 之上的,因此在實作 Supplier、Function 或 Consumer 時,您無需做太多事情即可受益於反應式程式設計模型。
例如
@SpringBootApplication
public static class SinkFromConsumer {
@Bean
public Function<Flux<String>, Flux<String>> reactiveUpperCase() {
return flux -> flux.map(val -> val.toUpperCase());
}
}
|
在選擇反應式或命令式程式設計模型時,必須了解一些重要事項。 完全反應式還是僅 API? 使用反應式 API 並不一定表示您可以受益於此類 API 的所有反應式功能。換句話說,諸如背壓和其他進階功能之類的功能僅在它們與相容系統 (例如 Reactive Kafka 綁定器) 一起工作時才有效。如果您使用的是常規 Kafka 或 Rabbit 或任何其他非反應式綁定器,您只能受益於反應式 API 本身提供的便利性,而不能受益於其進階功能,因為串流的實際來源或目標不是反應式的。 錯誤處理和重試 在本手冊中,您將看到有關基於框架的錯誤處理、重試和其他功能以及與它們關聯的組態屬性的多個參考。重要的是要了解它們僅影響命令式函數,並且當涉及反應式函數時,您不應抱持相同的期望。原因如下... 反應式函數和命令式函數之間存在根本差異。命令式函數是一個訊息處理器,框架在接收到每個訊息時都會調用它。因此,對於 N 個訊息,將有 N 次此類函數的調用,因此我們可以包裝此類函數並新增額外功能,例如錯誤處理、重試等。反應式函數是一個初始化函數。它只調用一次,以取得使用者提供的 Flux/Mono 的參考,以便與框架提供的 Flux/Mono 連接。在那之後,我們 (框架) 完全無法看到或控制串流。因此,對於反應式函數,您必須依賴反應式 API 在錯誤處理和重試方面的豐富性 (即, |
函數組合
使用函數式程式設計模型,您還可以受益於函數組合,在函數組合中,您可以從一組簡單的函數動態組合複雜的處理器。作為範例,讓我們將以下函數 Bean 新增到上面定義的應用程式中
@Bean
public Function<String, String> wrapInQuotes() {
return s -> "\"" + s + "\"";
}
並修改 spring.cloud.function.definition 屬性以反映您想要從 'toUpperCase' 和 'wrapInQuotes' 組合新函數的意圖。為此,Spring Cloud Function 依賴於 | (管道) 符號。因此,為了完成我們的範例,我們的屬性現在看起來像這樣
--spring.cloud.function.definition=toUpperCase|wrapInQuotes
| Spring Cloud Function 提供的函數組合支援的最大好處之一是,您可以組合反應式和命令式函數。 |
組合的結果是一個單一函數,您可能會猜到,它可能有一個非常長且相當神秘的名稱 (例如,foo|bar|baz|xyz...),這在涉及其他組態屬性時會帶來很大的不便。這就是函數式綁定名稱章節中描述的描述性綁定名稱功能可以提供幫助的地方。
例如,如果我們想要為我們的 toUpperCase|wrapInQuotes 提供更具描述性的名稱,我們可以使用以下屬性 spring.cloud.stream.function.bindings.toUpperCase|wrapInQuotes-in-0=quotedUpperCaseInput 來做到這一點,允許其他組態屬性參考該綁定名稱 (例如,spring.cloud.stream.bindings.quotedUpperCaseInput.destination=myDestination)。
函數組合和跨領域關注點
函數組合有效地讓您能夠透過將複雜性分解為一組簡單且可單獨管理/測試的元件來解決複雜性,這些元件在執行時期仍然可以表示為一個元件。但這不是唯一的好處。
您也可以使用組合來解決某些跨領域的非功能性關注點,例如內容豐富化。例如,假設您收到一條傳入訊息,該訊息可能缺少某些標頭,或者某些標頭的狀態不完全符合您的業務函數的預期。您現在可以實作一個單獨的函數來解決這些關注點,然後將其與主要業務函數組合。
讓我們看一個範例
@SpringBootApplication
public class DemoStreamApplication {
public static void main(String[] args) {
SpringApplication.run(DemoStreamApplication.class,
"--spring.cloud.function.definition=enrich|echo",
"--spring.cloud.stream.function.bindings.enrich|echo-in-0=input",
"--spring.cloud.stream.bindings.input.destination=myDestination",
"--spring.cloud.stream.bindings.input.group=myGroup");
}
@Bean
public Function<Message<String>, Message<String>> enrich() {
return message -> {
Assert.isTrue(!message.getHeaders().containsKey("foo"), "Should NOT contain 'foo' header");
return MessageBuilder.fromMessage(message).setHeader("foo", "bar").build();
};
}
@Bean
public Function<Message<String>, Message<String>> echo() {
return message -> {
Assert.isTrue(message.getHeaders().containsKey("foo"), "Should contain 'foo' header");
System.out.println("Incoming message " + message);
return message;
};
}
}
雖然很簡單,但此範例示範了一個函數如何使用額外的標頭 (非功能性關注點) 來豐富傳入的 Message,以便另一個函數 - echo - 可以從中受益。echo 函數保持乾淨,並且僅專注於業務邏輯。您也可以看到 spring.cloud.stream.function.bindings 屬性的用法,以簡化組合的綁定名稱。
具有多個輸入和輸出引數的函數
從 3.0 版開始,spring-cloud-stream 提供了對具有多個輸入和/或多個輸出 (傳回值) 的函數的支援。這實際上意味著什麼,它針對什麼類型的使用案例?
-
大數據:想像一下您正在處理的資料來源非常雜亂,並且包含各種資料元素類型 (例如,訂單、交易等),並且您實際上需要將其整理出來。
-
資料聚合:另一個使用案例可能需要您合併來自 2 個以上傳入串流的資料元素.
以上僅描述了您可能需要使用單一函數來接受和/或產生多個資料串流的幾個使用案例。這就是我們在這裡針對的使用案例類型。
此外,請注意這裡對串流概念的強調略有不同。假設是,如果此類函數可以存取實際的資料串流 (而不是個別元素),它們才有價值。因此,為此,我們依賴於 Project Reactor (即,Flux 和 Mono) 提供的抽象,它們已作為 spring-cloud-functions 引入的相依性的一部分在類路徑上可用。
另一個重要方面是多個輸入和輸出的表示形式。雖然 java 提供了各種不同的抽象來表示多個某物,但這些抽象是 a) 無界限的、b) 缺少元數和 c) 缺少類型資訊,這些在這種情況下都很重要。例如,讓我們看一下 Collection 或陣列,它僅允許我們描述單一類型的多個,或將所有內容向上轉換為 Object,從而影響 spring-cloud-stream 的透明類型轉換功能等等。
因此,為了滿足所有這些需求,初始支援依賴於使用 Project Reactor 提供的另一個抽象 - Tuples 的簽名。但是,我們正在努力允許更靈活的簽名。
| 請參閱綁定和綁定名稱章節,以了解用於建立此類應用程式使用的綁定名稱的命名慣例。 |
讓我們看幾個範例
@SpringBootApplication
public class SampleApplication {
@Bean
public Function<Tuple2<Flux<String>, Flux<Integer>>, Flux<String>> gather() {
return tuple -> {
Flux<String> stringStream = tuple.getT1();
Flux<String> intStream = tuple.getT2().map(i -> String.valueOf(i));
return Flux.merge(stringStream, intStream);
};
}
}
以上範例示範了一個函數,它接受兩個輸入 (第一個是 String 類型,第二個是 Integer 類型),並產生一個 String 類型的單一輸出。
因此,對於上述範例,兩個輸入綁定將為 gather-in-0 和 gather-in-1,為了保持一致性,輸出綁定也遵循相同的慣例,並命名為 gather-out-0。
了解這一點將允許您設定綁定特定的屬性。例如,以下程式碼將覆寫 gather-in-0 綁定的內容類型
--spring.cloud.stream.bindings.gather-in-0.content-type=text/plain
@SpringBootApplication
public class SampleApplication {
@Bean
public static Function<Flux<Integer>, Tuple2<Flux<String>, Flux<String>>> scatter() {
return flux -> {
Flux<Integer> connectedFlux = flux.publish().autoConnect(2);
UnicastProcessor even = UnicastProcessor.create();
UnicastProcessor odd = UnicastProcessor.create();
Flux<Integer> evenFlux = connectedFlux.filter(number -> number % 2 == 0).doOnNext(number -> even.onNext("EVEN: " + number));
Flux<Integer> oddFlux = connectedFlux.filter(number -> number % 2 != 0).doOnNext(number -> odd.onNext("ODD: " + number));
return Tuples.of(Flux.from(even).doOnSubscribe(x -> evenFlux.subscribe()), Flux.from(odd).doOnSubscribe(x -> oddFlux.subscribe()));
};
}
}
以上範例在某種程度上與先前的範例相反,並示範了一個函數,它接受 Integer 類型的單一輸入,並產生兩個輸出 (都是 String 類型)。
因此,對於上述範例,輸入綁定為 scatter-in-0,輸出綁定為 scatter-out-0 和 scatter-out-1。
您可以使用以下程式碼對其進行測試
@Test
public void testSingleInputMultiOutput() {
try (ConfigurableApplicationContext context = new SpringApplicationBuilder(
TestChannelBinderConfiguration.getCompleteConfiguration(
SampleApplication.class))
.run("--spring.cloud.function.definition=scatter")) {
InputDestination inputDestination = context.getBean(InputDestination.class);
OutputDestination outputDestination = context.getBean(OutputDestination.class);
for (int i = 0; i < 10; i++) {
inputDestination.send(MessageBuilder.withPayload(String.valueOf(i).getBytes()).build());
}
int counter = 0;
for (int i = 0; i < 5; i++) {
Message<byte[]> even = outputDestination.receive(0, 0);
assertThat(even.getPayload()).isEqualTo(("EVEN: " + String.valueOf(counter++)).getBytes());
Message<byte[]> odd = outputDestination.receive(0, 1);
assertThat(odd.getPayload()).isEqualTo(("ODD: " + String.valueOf(counter++)).getBytes());
}
}
}
單一應用程式中的多個函數
也可能需要在單一應用程式中分組多個訊息處理器。您可以透過定義多個函數來做到這一點。
@SpringBootApplication
public class SampleApplication {
@Bean
public Function<String, String> uppercase() {
return value -> value.toUpperCase();
}
@Bean
public Function<String, String> reverse() {
return value -> new StringBuilder(value).reverse().toString();
}
}
在上面的範例中,我們有一個組態,它定義了兩個函數 uppercase 和 reverse。因此,首先,如前所述,我們需要注意到存在衝突 (多個函數),因此我們需要透過提供 spring.cloud.function.definition 屬性來解決它,該屬性指向我們想要綁定的實際函數。只是在這裡我們將使用 ; 分隔符號來指向兩個函數 (請參閱下面的測試案例)。
| 與具有多個輸入/輸出的函數一樣,請參閱綁定和綁定名稱章節,以了解用於建立此類應用程式使用的綁定名稱的命名慣例。 |
您可以使用以下程式碼對其進行測試
@Test
public void testMultipleFunctions() {
try (ConfigurableApplicationContext context = new SpringApplicationBuilder(
TestChannelBinderConfiguration.getCompleteConfiguration(
ReactiveFunctionConfiguration.class))
.run("--spring.cloud.function.definition=uppercase;reverse")) {
InputDestination inputDestination = context.getBean(InputDestination.class);
OutputDestination outputDestination = context.getBean(OutputDestination.class);
Message<byte[]> inputMessage = MessageBuilder.withPayload("Hello".getBytes()).build();
inputDestination.send(inputMessage, "uppercase-in-0");
inputDestination.send(inputMessage, "reverse-in-0");
Message<byte[]> outputMessage = outputDestination.receive(0, "uppercase-out-0");
assertThat(outputMessage.getPayload()).isEqualTo("HELLO".getBytes());
outputMessage = outputDestination.receive(0, "reverse-out-1");
assertThat(outputMessage.getPayload()).isEqualTo("olleH".getBytes());
}
}
批次消費者
當使用支援批次接聽器的 MessageChannelBinder,並且該功能已為消費者綁定啟用時,您可以將 spring.cloud.stream.bindings.<binding-name>.consumer.batch-mode 設定為 true,以啟用將整個批次訊息以 List 形式傳遞給函數。
@Bean
public Function<List<Person>, Person> findFirstPerson() {
return persons -> persons.get(0);
}
批次生產者
您也可以在生產者端使用批次處理的概念,方法是傳回訊息集合,這樣可以有效地提供反向效果,其中集合中的每則訊息都會由綁定器個別傳送。
考慮以下函式
@Bean
public Function<String, List<Message<String>>> batch() {
return p -> {
List<Message<String>> list = new ArrayList<>();
list.add(MessageBuilder.withPayload(p + ":1").build());
list.add(MessageBuilder.withPayload(p + ":2").build());
list.add(MessageBuilder.withPayload(p + ":3").build());
list.add(MessageBuilder.withPayload(p + ":4").build());
return list;
};
}
傳回清單中的每則訊息都會個別傳送,導致四則訊息傳送到輸出目的地。
將 Spring Integration flow 作為函式
當您實作函式時,您可能會有符合 企業整合模式 (EIP) 類別的複雜需求。這些最好使用諸如 Spring Integration (SI) 之類的框架來處理,Spring Integration 是 EIP 的參考實作。
值得慶幸的是,SI 已經透過 將 Integration flow 作為閘道 提供對將整合流程公開為函式的支援。請考慮以下範例
@SpringBootApplication
public class FunctionSampleSpringIntegrationApplication {
public static void main(String[] args) {
SpringApplication.run(FunctionSampleSpringIntegrationApplication.class, args);
}
@Bean
public IntegrationFlow uppercaseFlow() {
return IntegrationFlows.from(MessageFunction.class, "uppercase")
.<String, String>transform(String::toUpperCase)
.logAndReply(LoggingHandler.Level.WARN);
}
public interface MessageFunction extends Function<Message<String>, Message<String>> {
}
}
對於那些熟悉 SI 的人來說,您可以看到我們定義了一個 IntegrationFlow 類型的 bean,我們在其中宣告一個我們想要公開為名為 uppercase 的 Function<String, String> (使用 SI DSL) 的整合流程。MessageFunction 介面讓我們明確宣告輸入和輸出的類型,以便進行適當的類型轉換。有關類型轉換的更多資訊,請參閱 內容類型協商 章節。
若要接收原始輸入,您可以使用 from(Function.class, …)。
產生的函式會綁定到目標綁定器公開的輸入和輸出目的地。
| 請參閱綁定和綁定名稱章節,以了解用於建立此類應用程式使用的綁定名稱的命名慣例。 |
有關 Spring Integration 和 Spring Cloud Stream 在功能性程式設計模型方面的互通性的更多詳細資訊,您可能會發現 這篇文章 非常有趣,因為它更深入地探討了您可以透過合併 Spring Integration 和 Spring Cloud Stream/Functions 的最佳功能來應用的各種模式。
使用輪詢消費者
概觀
當使用輪詢消費者時,您會根據需求輪詢 PollableMessageSource。若要定義輪詢消費者的綁定,您需要提供 spring.cloud.stream.pollable-source 屬性。
考慮以下輪詢消費者綁定的範例
--spring.cloud.stream.pollable-source=myDestination前面範例中的可輪詢來源名稱 myDestination 將會產生 myDestination-in-0 綁定名稱,以與功能性程式設計模型保持一致。
假設前面範例中的輪詢消費者,您可以如下使用它
@Bean
public ApplicationRunner poller(PollableMessageSource destIn, MessageChannel destOut) {
return args -> {
while (someCondition()) {
try {
if (!destIn.poll(m -> {
String newPayload = ((String) m.getPayload()).toUpperCase();
destOut.send(new GenericMessage<>(newPayload));
})) {
Thread.sleep(1000);
}
}
catch (Exception e) {
// handle failure
}
}
};
}
一個較不手動且更像 Spring 的替代方案是設定排程工作 bean。例如:
@Scheduled(fixedDelay = 5_000)
public void poll() {
System.out.println("Polling...");
this.source.poll(m -> {
System.out.println(m.getPayload());
}, new ParameterizedTypeReference<Foo>() { });
}
PollableMessageSource.poll() 方法接受 MessageHandler 引數 (通常是 lambda 運算式,如此處所示)。如果訊息已接收並成功處理,則傳回 true。
與訊息驅動消費者一樣,如果 MessageHandler 擲回例外,則訊息會發佈到錯誤通道,如 錯誤處理 中所述。
通常,當 MessageHandler 結束時,poll() 方法會確認訊息。如果方法異常結束,則訊息會被拒絕 (不會重新排隊),但請參閱 處理錯誤。您可以透過承擔確認責任來覆寫該行為,如下列範例所示
@Bean
public ApplicationRunner poller(PollableMessageSource dest1In, MessageChannel dest2Out) {
return args -> {
while (someCondition()) {
if (!dest1In.poll(m -> {
StaticMessageHeaderAccessor.getAcknowledgmentCallback(m).noAutoAck();
// e.g. hand off to another thread which can perform the ack
// or acknowledge(Status.REQUEUE)
})) {
Thread.sleep(1000);
}
}
};
}
您必須在某個時間點 ack (或 nack) 訊息,以避免資源洩漏。 |
某些訊息系統 (例如 Apache Kafka) 會在日誌中維護簡單的偏移量。如果傳遞失敗並使用 StaticMessageHeaderAccessor.getAcknowledgmentCallback(m).acknowledge(Status.REQUEUE); 重新排隊,則稍後任何成功 ack 的訊息都會重新傳遞。 |
還有一個多載的 poll 方法,其定義如下
poll(MessageHandler handler, ParameterizedTypeReference<?> type)
type 是一個轉換提示,允許轉換傳入的訊息酬載,如下列範例所示
boolean result = pollableSource.poll(received -> {
Map<String, Foo> payload = (Map<String, Foo>) received.getPayload();
...
}, new ParameterizedTypeReference<Map<String, Foo>>() {});
處理錯誤
預設情況下,會為可輪詢來源設定錯誤通道;如果回呼擲回例外,則 ErrorMessage 會傳送到錯誤通道 (<destination>.<group>.errors);此錯誤通道也會橋接到全域 Spring Integration errorChannel。
您可以使用 @ServiceActivator 訂閱任一錯誤通道來處理錯誤;如果沒有訂閱,錯誤只會被記錄,並且訊息會被確認為成功。如果錯誤通道服務啟動器擲回例外,則訊息將被拒絕 (預設情況下) 並且不會重新傳遞。如果服務啟動器擲回 RequeueCurrentMessageException,則訊息將在代理程式中重新排隊,並在後續輪詢中再次擷取。
如果接聽器直接擲回 RequeueCurrentMessageException,則訊息將如上所述重新排隊,並且不會傳送到錯誤通道。
事件路由
事件路由在 Spring Cloud Stream 的上下文中,是指 a) 將事件路由到特定事件訂閱者 或 b) 將事件訂閱者產生的事件路由到特定目的地 的能力。在這裡,我們將其稱為路由「TO」和路由「FROM」。
路由 TO 消費者
路由可以透過依賴 Spring Cloud Function 3.0 中提供的 RoutingFunction 來實現。您只需要透過 --spring.cloud.stream.function.routing.enabled=true 應用程式屬性啟用它,或提供 spring.cloud.function.routing-expression 屬性。一旦啟用,RoutingFunction 將會綁定到輸入目的地,接收所有訊息,並根據提供的指示將它們路由到其他函式。
為了綁定的目的,路由目的地的名稱是 functionRouter-in-0 (請參閱 RoutingFunction.FUNCTION_NAME 和綁定命名慣例 功能性綁定名稱)。 |
指示可以透過個別訊息以及應用程式屬性提供。
以下是一些範例
使用訊息標頭
@SpringBootApplication
public class SampleApplication {
public static void main(String[] args) {
SpringApplication.run(SampleApplication.class,
"--spring.cloud.stream.function.routing.enabled=true");
}
@Bean
public Consumer<String> even() {
return value -> {
System.out.println("EVEN: " + value);
};
}
@Bean
public Consumer<String> odd() {
return value -> {
System.out.println("ODD: " + value);
};
}
}
透過將訊息傳送到綁定器 (即 rabbit、kafka) 公開的 functionRouter-in-0 目的地,此訊息將會路由到適當的 ('even' 或 'odd') 消費者。
預設情況下,RoutingFunction 將會尋找 spring.cloud.function.definition 或 spring.cloud.function.routing-expression (對於具有 SpEL 的更動態情境) 標頭,如果找到,則其值將被視為路由指示。
例如,將 spring.cloud.function.routing-expression 標頭設定為值 T(java.lang.System).currentTimeMillis() % 2 == 0 ? 'even' : 'odd' 將會導致半隨機地將請求路由到 odd 或 even 函式。此外,對於 SpEL,評估內容的根物件是 Message,因此您也可以對個別標頭 (或訊息) 進行評估 ….routing-expression=headers['type']
使用應用程式屬性
spring.cloud.function.routing-expression 和/或 spring.cloud.function.definition 可以作為應用程式屬性傳遞 (例如,spring.cloud.function.routing-expression=headers['type']。
@SpringBootApplication
public class RoutingStreamApplication {
public static void main(String[] args) {
SpringApplication.run(RoutingStreamApplication.class,
"--spring.cloud.function.routing-expression="
+ "T(java.lang.System).nanoTime() % 2 == 0 ? 'even' : 'odd'");
}
@Bean
public Consumer<Integer> even() {
return value -> System.out.println("EVEN: " + value);
}
@Bean
public Consumer<Integer> odd() {
return value -> System.out.println("ODD: " + value);
}
}
| 透過應用程式屬性傳遞指示對於反應式函式尤其重要,因為反應式函式只會被調用一次以傳遞 Publisher,因此對個別項目的存取受到限制。 |
路由函式和輸出綁定
RoutingFunction 是一個 Function,因此與任何其他函式沒有區別。好吧 . . . 幾乎。
當 RoutingFunction 路由到另一個 Function 時,其輸出會傳送到 RoutingFunction 的輸出綁定,即預期的 functionRouter-in-0。但是,如果 RoutingFunction 路由到 Consumer 呢?換句話說,RoutingFunction 的調用結果可能不會產生任何要傳送到輸出綁定的內容,因此甚至有必要擁有一個輸出綁定。因此,當我們建立綁定時,我們確實對 RoutingFunction 進行了稍微不同的處理。即使它對您作為使用者來說是透明的 (實際上您沒有任何事情要做),但了解一些機制將有助於您了解其內部運作方式。
因此,規則是;我們永遠不會為 RoutingFunction 建立輸出綁定,只建立輸入綁定。因此,當您路由到 Consumer 時,RoutingFunction 實際上會因為沒有任何輸出綁定而成為 Consumer。但是,如果 RoutingFunction 恰好路由到另一個產生輸出的 Function,則 RoutingFunction 的輸出綁定將會動態建立,此時 RoutingFunction 在綁定方面將會像一個常規 Function 一樣運作 (同時具有輸入和輸出綁定)。
路由 FROM 消費者
除了靜態目的地之外,Spring Cloud Stream 還允許應用程式將訊息傳送到動態綁定的目的地。例如,當需要在執行階段判斷目標目的地時,這非常有用。應用程式可以透過兩種方式執行此操作。
spring.cloud.stream.sendto.destination
您也可以透過指定 spring.cloud.stream.sendto.destination 標頭設定為要解析的目的地名稱,委派給框架以動態解析輸出目的地。
考慮以下範例
@SpringBootApplication
@Controller
public class SourceWithDynamicDestination {
@Bean
public Function<String, Message<String>> destinationAsPayload() {
return value -> {
return MessageBuilder.withPayload(value)
.setHeader("spring.cloud.stream.sendto.destination", value).build();};
}
}
雖然很簡單,但您可以在此範例中清楚地看到,我們的輸出是一個訊息,其中 spring.cloud.stream.sendto.destination 標頭設定為輸入引數的值。框架將會查詢此標頭,並嘗試建立或探索具有該名稱的目的地,並將輸出傳送到該目的地。
如果目的地名稱是預先知道的,您可以像任何其他目的地一樣設定生產者屬性。或者,如果您註冊 NewDestinationBindingCallback<> bean,則會在建立綁定之前調用它。回呼採用綁定器使用的擴充生產者屬性的泛型類型。它有一個方法
void configure(String destinationName, MessageChannel channel, ProducerProperties producerProperties,
T extendedProducerProperties);
以下範例顯示如何使用 RabbitMQ 綁定器
@Bean
public NewDestinationBindingCallback<RabbitProducerProperties> dynamicConfigurer() {
return (name, channel, props, extended) -> {
props.setRequiredGroups("bindThisQueue");
extended.setQueueNameGroupOnly(true);
extended.setAutoBindDlq(true);
extended.setDeadLetterQueueName("myDLQ");
};
}
如果您需要支援具有多個綁定器類型的動態目的地,請使用 Object 作為泛型類型,並根據需要轉換 extended 引數。 |
此外,請參閱 [使用 StreamBridge] 章節,以了解如何將另一個選項 (StreamBridge) 用於類似情況。
後處理 (傳送訊息之後)
一旦調用函式,其結果會由框架傳送到目標目的地,從而有效地完成函式調用週期。
但是,從業務角度來看,在完成此週期之後執行某些額外任務之前,此週期可能尚未完全完成。雖然這可以使用 Consumer 和 StreamBridge 的簡單組合來完成,如這篇 Stack Overflow 文章 中所述,但自 4.0.3 版以來,框架提供了一種更慣用的方法,透過 Spring Cloud Function 專案提供的 PostProcessingFunction 來解決此問題。PostProcessingFunction 是一個特殊的半標記函式,其中包含一個額外的方法 postProcess(Message>),旨在為實作此類後處理任務提供一個位置。
package org.springframework.cloud.function.context
. . .
public interface PostProcessingFunction<I, O> extends Function<I, O> {
default void postProcess(Message<O> result) {
}
}
因此,現在您有兩個選項。
選項 1:您可以將您的函式實作為 PostProcessingFunction,並且還可以透過實作其 postProcess(Message>) 方法來包含額外的後處理行為。
private static class Uppercase implements PostProcessingFunction<String, String> {
@Override
public String apply(String input) {
return input.toUpperCase();
}
@Override
public void postProcess(Message<String> result) {
System.out.println("Function Uppercase has been successfully invoked and its result successfully sent to target destination");
}
}
. . .
@Bean
public Function<String, String> uppercase() {
return new Uppercase();
}
選項 2:如果您已經有一個現有的函式,並且不想變更其實作,或者想要將您的函式保留為 POJO,您可以只實作 postProcess(Message>) 方法,並將這個新的後處理函式與您的其他函式組合。
private static class Logger implements PostProcessingFunction<?, String> {
@Override
public void postProcess(Message<String> result) {
System.out.println("Function has been successfully invoked and its result successfully sent to target destination");
}
}
. . .
@Bean
public Function<String, String> uppercase() {
return v -> v.toUpperCase();
}
@Bean
public Function<String, String> logger() {
return new Logger();
}
. . .
// and then have your function definition as such `uppercase|logger`
注意:在函式組合的情況下,只有最後一個 PostProcessingFunction 實例 (如果存在) 會生效。例如,假設您有以下函式定義 - foo|bar|baz,並且 foo 和 baz 都是 PostProcessingFunction 的實例。只會調用 baz.postProcess(Message>)。如果 baz 不是 PostProcessingFunction 的實例,則不會執行任何後處理功能。
有人可能會爭辯說,您可以透過簡單地將後處理器組合為另一個 Function 來輕鬆地透過函式組合來做到這一點。這確實是一種可能性,但是,在這種情況下,後處理功能將在調用前一個函式之後且在訊息傳送到目標目的地之前調用,這是在函式調用週期完成之前。
錯誤處理
在本節中,我們將解釋框架提供的錯誤處理機制背後的總體思路。我們將以 Rabbit 綁定器為例,因為個別綁定器為特定於底層代理程式功能的某些支援機制定義了不同的屬性集 (例如 Kafka 綁定器)。
錯誤會發生,而 Spring Cloud Stream 提供了幾種彈性機制來處理它們。請注意,這些技術取決於綁定器實作和底層訊息傳遞中介軟體的功能以及程式設計模型 (稍後會詳細介紹)。
每當訊息處理常式 (函式) 擲回例外時,它會傳播回綁定器,此時綁定器將使用 Spring Retry 程式庫提供的 RetryTemplate 多次嘗試重新試用相同的訊息 (預設為 3 次)。如果重試不成功,則由錯誤處理機制決定,該機制可以捨棄訊息、重新排隊訊息以進行重新處理或將失敗的訊息傳送到 DLQ。
Rabbit 和 Kafka 都支援這些概念 (尤其是 DLQ)。但是,其他綁定器可能不支援,因此請參閱您個別綁定器的文件,以了解有關支援的錯誤處理選項的詳細資訊。
但是請記住,反應式函式不符合訊息處理常式的資格,因為它不處理個別訊息,而是提供一種將框架提供的串流 (即 Flux) 與使用者提供的串流連接起來的方式。為什麼這很重要? 這是因為您稍後在本節中讀到的任何關於重試範本、捨棄失敗訊息、重試、DLQ 以及協助所有這些的組態屬性,僅適用於訊息處理常式 (即命令式函式)。
反應式 API 提供了非常豐富的自身運算子和機制程式庫,可協助您處理特定於各種反應式用例的錯誤處理,這些用例比簡單的訊息處理常式案例複雜得多。因此,請使用它們,例如您可以在 reactor.core.publisher.Flux 中找到的 public final Flux<T> retryWhen(Retry retrySpec);。
@Bean
public Function<Flux<String>, Flux<String>> uppercase() {
return flux -> flux
.retryWhen(Retry.backoff(3, Duration.ofMillis(1000)))
.map(v -> v.toUpperCase());
}
捨棄失敗的訊息
預設情況下,系統提供錯誤處理常式。第一個錯誤處理常式只會記錄錯誤訊息。第二個錯誤處理常式是特定於綁定器的錯誤處理常式,負責在特定訊息傳遞系統的上下文中處理錯誤訊息 (例如,傳送到 DLQ)。但是由於沒有提供額外的錯誤處理組態 (在目前的情境中),因此此處理常式不會執行任何操作。因此,基本上在記錄後,訊息將被捨棄。
雖然在某些情況下可以接受,但在大多數情況下,這是不可接受的,我們需要一些復原機制來避免訊息遺失。
處理錯誤訊息
在上一節中,我們提到預設情況下,導致錯誤的訊息會被有效地記錄並捨棄。框架還公開了一種機制,供您提供自訂錯誤處理常式 (即,傳送通知或寫入資料庫等)。您可以透過新增專門設計用於接受 ErrorMessage 的 Consumer 來做到這一點,除了所有關於錯誤的資訊 (例如,堆疊追蹤等) 之外,還包含原始訊息 (觸發錯誤的訊息)。注意:自訂錯誤處理常式與框架提供的錯誤處理常式 (即,記錄和綁定器錯誤處理常式 - 請參閱上一節) 互斥,以確保它們不會相互干擾。
@Bean
public Consumer<ErrorMessage> myErrorHandler() {
return v -> {
// send SMS notification code
};
}
若要將此類消費者識別為錯誤處理常式,您只需要提供指向函式名稱的 error-handler-definition 屬性 - spring.cloud.stream.bindings.<binding-name>.error-handler-definition=myErrorHandler。
例如,對於綁定名稱 uppercase-in-0,屬性將如下所示
spring.cloud.stream.bindings.uppercase-in-0.error-handler-definition=myErrorHandler如果您使用特殊對應指示將綁定對應到更易於閱讀的名稱 - spring.cloud.stream.function.bindings.uppercase-in-0=upper,則此屬性將如下所示
spring.cloud.stream.bindings.upper.error-handler-definition=myErrorHandler.如果您不小心將此類處理常式宣告為 Function,它仍然可以運作,但唯一的例外是其輸出不會執行任何操作。但是,鑑於此類處理常式仍然依賴 Spring Cloud Function 提供的功能,您也可以從函式組合中受益,以防您的處理常式具有您想要透過函式組合解決的某些複雜性 (儘管不太可能)。 |
預設錯誤處理常式
如果您想要為所有函式 bean 設定單一錯誤處理常式,您可以使用標準 spring-cloud-stream 機制來定義預設屬性 spring.cloud.stream.default.error-handler-definition=myErrorHandler
DLQ - 死信佇列
也許最常見的機制是 DLQ,它允許將失敗的訊息傳送到特殊目的地:死信佇列。
配置後,失敗的訊息會傳送到此目的地,以便後續重新處理或稽核和協調。
考慮以下範例
@SpringBootApplication
public class SimpleStreamApplication {
public static void main(String[] args) throws Exception {
SpringApplication.run(SimpleStreamApplication.class,
"--spring.cloud.function.definition=uppercase",
"--spring.cloud.stream.bindings.uppercase-in-0.destination=uppercase",
"--spring.cloud.stream.bindings.uppercase-in-0.group=myGroup",
"--spring.cloud.stream.rabbit.bindings.uppercase-in-0.consumer.auto-bind-dlq=true"
);
}
@Bean
public Function<Person, Person> uppercase() {
return personIn -> {
throw new RuntimeException("intentional");
});
};
}
}
提醒一下,在此範例中,屬性的 uppercase-in-0 部分對應於輸入目的地綁定的名稱。consumer 部分表示它是消費者屬性。
當使用 DLQ 時,至少必須提供 group 屬性,以正確命名 DLQ 目的地。但是,group 通常與 destination 屬性一起使用,就像我們的範例一樣。 |
除了某些標準屬性之外,我們還設定了 auto-bind-dlq 以指示綁定器為 uppercase-in-0 綁定建立和配置 DLQ 目的地,該綁定對應於 uppercase 目的地 (請參閱對應的屬性),這會產生一個名為 uppercase.myGroup.dlq 的額外 Rabbit 佇列 (有關 Kafka 特定的 DLQ 屬性,請參閱 Kafka 文件)。
配置完成後,所有失敗的訊息都會路由到此目的地,保留原始訊息以供進一步操作。
您可以看到錯誤訊息包含更多與原始錯誤相關的資訊,如下所示
. . . .
x-exception-stacktrace: org.springframework.messaging.MessageHandlingException: nested exception is
org.springframework.messaging.MessagingException: has an error, failedMessage=GenericMessage [payload=byte[15],
headers={amqp_receivedDeliveryMode=NON_PERSISTENT, amqp_receivedRoutingKey=input.hello, amqp_deliveryTag=1,
deliveryAttempt=3, amqp_consumerQueue=input.hello, amqp_redelivered=false, id=a15231e6-3f80-677b-5ad7-d4b1e61e486e,
amqp_consumerTag=amq.ctag-skBFapilvtZhDsn0k3ZmQg, contentType=application/json, timestamp=1522327846136}]
at org.spring...integ...han...MethodInvokingMessageProcessor.processMessage(MethodInvokingMessageProcessor.java:107)
at. . . . .
Payload: blah您也可以透過將 max-attempts 設定為 '1' 來促進立即調度到 DLQ (無需重試)。例如:
--spring.cloud.stream.bindings.uppercase-in-0.consumer.max-attempts=1重試範本
在本節中,我們將介紹與重試功能配置相關的組態屬性。
RetryTemplate 是 Spring Retry 程式庫的一部分。雖然涵蓋 RetryTemplate 的所有功能超出了本文的範圍,但我們將提及以下與 RetryTemplate 特別相關的消費者屬性
- maxAttempts
-
處理訊息的嘗試次數。
預設值:3。
- backOffInitialInterval
-
重試時的回退初始間隔。
預設值:1000 毫秒。
- backOffMaxInterval
-
最大回退間隔。
預設值:10000 毫秒。
- backOffMultiplier
-
回退乘數。
預設值:2.0。
- defaultRetryable
-
未在
retryableExceptions中列出的接聽器擲回的例外是否可重試。預設值:
true。 - retryableExceptions
-
鍵中 Throwable 類別名稱和值中布林值的對應。指定將要或不會重試的那些例外 (和子類別)。另請參閱
defaultRetriable。範例:spring.cloud.stream.bindings.input.consumer.retryable-exceptions.java.lang.IllegalStateException=false。預設值:空。
雖然前面的設定足以滿足大多數自訂需求,但它們可能無法滿足某些複雜需求,此時您可能想要提供您自己的 RetryTemplate 實例。若要執行此操作,請將其配置為應用程式組態中的 bean。應用程式提供的實例將覆寫框架提供的實例。此外,為了避免衝突,您必須限定您想要綁定器使用的 RetryTemplate 實例為 @StreamRetryTemplate。例如:
@StreamRetryTemplate
public RetryTemplate myRetryTemplate() {
return new RetryTemplate();
}
如您從上面的範例中看到的,您不需要使用 @Bean 註釋它,因為 @StreamRetryTemplate 是一個合格的 @Bean。
如果您需要更精確地使用 RetryTemplate,您可以在您的 ConsumerProperties 中依名稱指定 bean,以將特定的重試 bean 與每個綁定關聯。
spring.cloud.stream.bindings.<foo>.consumer.retry-template-name=<your-retry-template-bean-name>綁定器
Spring Cloud Stream 提供了一個綁定器抽象,用於連接到外部中介軟體中的實體目的地。本節提供有關綁定器 SPI 背後的主要概念、其主要組件以及實作特定詳細資訊的資訊。
生產者和消費者
下圖顯示了生產者和消費者的一般關係
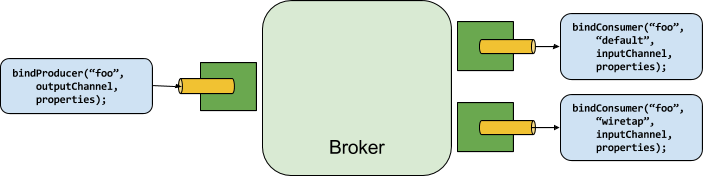
生產者是任何將訊息傳送到綁定目的地的組件。綁定目的地可以使用該代理程式的 Binder 實作綁定到外部訊息代理程式。當調用 bindProducer() 方法時,第一個參數是代理程式內的目的地名稱,第二個參數是生產者將訊息傳送到的本機目的地實例,第三個參數包含屬性 (例如分割區金鑰運算式),這些屬性將在為該綁定目的地建立的配接器中使用。
消費者是任何從綁定目的地接收訊息的組件。與生產者一樣,消費者可以綁定到外部訊息代理程式。當調用 bindConsumer() 方法時,第一個參數是目的地名稱,第二個參數提供消費者的邏輯群組名稱。由給定目的地的消費者綁定表示的每個群組都會接收生產者傳送到該目的地的每則訊息的副本 (也就是說,它遵循正常的發佈-訂閱語意)。如果有使用相同群組名稱綁定的多個消費者實例,則訊息會在這些消費者實例之間進行負載平衡,以便生產者傳送的每則訊息僅由每個群組中的單一消費者實例消耗 (也就是說,它遵循正常的佇列語意)。
綁定器 SPI
綁定器 SPI 由許多介面、開箱即用的公用程式類別和探索策略組成,這些介面、類別和策略提供了一個可插拔的機制,用於連接到外部中介軟體。
SPI 的重點是 Binder 介面,它是一種將輸入和輸出連接到外部中介軟體的策略。以下清單顯示了 Binder 介面的定義
public interface Binder<T, C extends ConsumerProperties, P extends ProducerProperties> {
Binding<T> bindConsumer(String bindingName, String group, T inboundBindTarget, C consumerProperties);
Binding<T> bindProducer(String bindingName, T outboundBindTarget, P producerProperties);
}
介面是參數化的,提供了一些擴充點
-
輸入和輸出綁定目標。
-
擴充的消費者和生產者屬性,允許特定的綁定器實作新增可以在類型安全方式中支援的補充屬性。
典型的綁定器實作包含以下內容
-
一個實作
Binder介面的類別; -
一個 Spring
@Configuration類別,它建立一個Binder類型的 bean 以及中介軟體連接基礎結構。 -
一個在類別路徑上找到的
META-INF/spring.binders檔案,其中包含一個或多個綁定器定義,如下列範例所示kafka:\ org.springframework.cloud.stream.binder.kafka.config.KafkaBinderConfiguration
正如先前所述,綁定器抽象也是框架的擴充點之一。因此,如果您在先前的清單中找不到合適的綁定器,您可以在 Spring Cloud Stream 之上實作您自己的綁定器。在 如何從頭開始建立 Spring Cloud Stream 綁定器 文章中,一位社群成員使用範例詳細記錄了實作自訂綁定器所需的步驟集。這些步驟也在 實作自訂綁定器 章節中重點介紹。 |
綁定器偵測
Spring Cloud Stream 依賴綁定器 SPI 的實作來執行將使用者程式碼連接 (綁定) 到訊息代理程式的任務。每個綁定器實作通常連接到一種訊息傳遞系統。
類別路徑偵測
預設情況下,Spring Cloud Stream 依賴 Spring Boot 的自動配置來配置綁定程序。如果在類別路徑上找到單個綁定器實作,Spring Cloud Stream 會自動使用它。例如,旨在僅綁定到 RabbitMQ 的 Spring Cloud Stream 專案可以新增以下依賴項
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-stream-binder-rabbit</artifactId>
</dependency>有關其他綁定器依賴項的特定 Maven 座標,請參閱該綁定器實作的文件。
類別路徑上的多個綁定器
當類別路徑上存在多個綁定器時,應用程式必須指示每個目的地綁定要使用哪個綁定器。每個綁定器組態都包含一個 META-INF/spring.binders 檔案,這是一個簡單的屬性檔案,如下列範例所示
rabbit:\
org.springframework.cloud.stream.binder.rabbit.config.RabbitServiceAutoConfiguration其他提供的綁定器實作 (例如 Kafka) 也存在類似的檔案,並且自訂綁定器實作也應提供這些檔案。鍵表示綁定器實作的識別名稱,而值是以逗號分隔的組態類別清單,每個組態類別都包含一個且僅一個 org.springframework.cloud.stream.binder.Binder 類型的 bean 定義。
綁定器選擇可以全域執行,使用 spring.cloud.stream.defaultBinder 屬性 (例如,spring.cloud.stream.defaultBinder=rabbit) 或個別執行,方法是在每個綁定上配置綁定器。例如,從 Kafka 讀取並寫入 RabbitMQ 的處理器應用程式 (具有分別用於讀取和寫入的名稱為 input 和 output 的綁定) 可以指定以下組態
spring.cloud.stream.bindings.input.binder=kafka
spring.cloud.stream.bindings.output.binder=rabbit連接到多個系統
預設情況下,綁定器會共用應用程式的 Spring Boot 自動配置,以便建立在類別路徑上找到的每個綁定器的一個實例。如果您的應用程式應連接到多個相同類型的代理程式,您可以指定多個綁定器組態,每個組態都具有不同的環境設定。
開啟明確的綁定器組態會完全停用預設的綁定器組態程序。如果您這樣做,則所有正在使用的綁定器都必須包含在組態中。旨在透明地使用 Spring Cloud Stream 的框架可以建立可以依名稱參考的綁定器組態,但它們不會影響預設的綁定器組態。為了做到這一點,綁定器組態可以將其 defaultCandidate 旗標設定為 false (例如,spring.cloud.stream.binders.<configurationName>.defaultCandidate=false)。這表示獨立於預設綁定器組態程序而存在的組態。 |
以下範例顯示了連接到兩個 RabbitMQ 代理程式實例的處理器應用程式的典型組態
spring:
cloud:
stream:
bindings:
input:
destination: thing1
binder: rabbit1
output:
destination: thing2
binder: rabbit2
binders:
rabbit1:
type: rabbit
environment:
spring:
rabbitmq:
host: <host1>
rabbit2:
type: rabbit
environment:
spring:
rabbitmq:
host: <host2>特定綁定器的 environment 屬性也可以用於任何 Spring Boot 屬性,包括此 spring.main.sources,它對於為特定綁定器新增額外組態非常有用,例如覆寫自動配置的 bean。 |
例如:
environment:
spring:
main:
sources: com.acme.config.MyCustomBinderConfiguration若要為特定綁定器環境啟用特定設定檔,您應該使用 spring.profiles.active 屬性
environment:
spring:
profiles:
active: myBinderProfile在多綁定器應用程式中自訂綁定器
當應用程式中有多個綁定器並且想要自訂綁定器時,可以透過提供 BinderCustomizer 實作來實現。在具有單個綁定器的應用程式的情況下,此特殊自訂器不是必要的,因為綁定器內容可以直接存取自訂 bean。但是,在多綁定器情境中情況並非如此,因為各種綁定器存在於不同的應用程式內容中。透過提供 BinderCustomizer 介面的實作,綁定器雖然駐留在不同的應用程式內容中,但仍將接收自訂。Spring Cloud Stream 確保在應用程式開始使用綁定器之前進行自訂。使用者必須檢查綁定器類型,然後套用必要的自訂。
以下是提供 BinderCustomizer bean 的範例。
@Bean
public BinderCustomizer binderCustomizer() {
return (binder, binderName) -> {
if (binder instanceof KafkaMessageChannelBinder kafkaMessageChannelBinder) {
kafkaMessageChannelBinder.setRebalanceListener(...);
}
else if (binder instanceof KStreamBinder) {
...
}
else if (binder instanceof RabbitMessageChannelBinder) {
...
}
};
}
請注意,當存在多個相同類型的綁定器實例時,可以使用綁定器名稱來篩選自訂。
綁定視覺化和控制
Spring Cloud Stream 透過 Actuator 端點以及程式化方式支援綁定的視覺化和控制。
程式化方式
自 3.1 版以來,我們公開了 org.springframework.cloud.stream.binding.BindingsLifecycleController,它已註冊為 bean,一旦注入,即可用於控制個別綁定的生命週期
例如,查看來自其中一個測試案例的片段。如您所見,我們從 spring 應用程式內容中擷取 BindingsLifecycleController,並執行個別方法來控制 echo-in-0 綁定的生命週期。
BindingsLifecycleController bindingsController = context.getBean(BindingsLifecycleController.class);
Binding binding = bindingsController.queryState("echo-in-0");
assertThat(binding.isRunning()).isTrue();
bindingsController.changeState("echo-in-0", State.STOPPED);
//Alternative way of changing state. For convenience we expose start/stop and pause/resume operations.
//bindingsController.stop("echo-in-0")
assertThat(binding.isRunning()).isFalse();
Actuator
由於 actuator 和 web 是選用的,您必須先新增其中一個 web 依賴項,然後手動新增 actuator 依賴項。以下範例顯示如何新增 Web 框架的依賴項
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>以下範例顯示如何新增 WebFlux 框架的依賴項
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-webflux</artifactId>
</dependency>您可以如下新增 Actuator 依賴項
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>若要在 Cloud Foundry 中執行 Spring Cloud Stream 2.0 應用程式,您必須將 spring-boot-starter-web 和 spring-boot-starter-actuator 新增到類別路徑。否則,應用程式將會因為健康檢查失敗而無法啟動。 |
您也必須透過設定以下屬性來啟用 bindings actuator 端點:--management.endpoints.web.exposure.include=bindings。
一旦滿足這些先決條件。您應該會在應用程式啟動時在日誌中看到以下內容
: Mapped "{[/actuator/bindings/{name}],methods=[POST]. . .
: Mapped "{[/actuator/bindings],methods=[GET]. . .
: Mapped "{[/actuator/bindings/{name}],methods=[GET]. . .
若要視覺化目前的綁定,請存取以下 URL:http://<host>:<port>/actuator/bindings
或者,若要查看單個綁定,請存取類似於以下的 URL 之一:http://<host>:<port>/actuator/bindings/<bindingName>;
您也可以透過張貼到相同的 URL,同時提供 JSON 格式的 state 引數,來停止、啟動、暫停和恢復個別綁定,如下列範例所示
curl -d '{"state":"STOPPED"}' -H "Content-Type: application/json" -X POST http://<host>:<port>/actuator/bindings/myBindingName
curl -d '{"state":"STARTED"}' -H "Content-Type: application/json" -X POST http://<host>:<port>/actuator/bindings/myBindingName
curl -d '{"state":"PAUSED"}' -H "Content-Type: application/json" -X POST http://<host>:<port>/actuator/bindings/myBindingName
curl -d '{"state":"RESUMED"}' -H "Content-Type: application/json" -X POST http://<host>:<port>/actuator/bindings/myBindingName
PAUSED 和 RESUMED 僅在對應的綁定器及其底層技術支援時才有效。否則,您會在日誌中看到警告訊息。目前,只有 Kafka 和 [Solace](https://github.com/SolaceProducts/solace-spring-cloud/tree/master/solace-spring-cloud-starters/solace-spring-cloud-stream-starter#consumer-bindings-pauseresume) 綁定器支援 PAUSED 和 RESUMED 狀態。 |
綁定器組態屬性
以下屬性可用於自訂綁定器組態。這些屬性透過 org.springframework.cloud.stream.config.BinderProperties 公開
它們必須以 spring.cloud.stream.binders.<configurationName> 為前綴。
- type
-
綁定器類型。它通常參考類別路徑上找到的綁定器之一,特別是
META-INF/spring.binders檔案中的一個鍵。預設情況下,它與組態名稱具有相同的值。
- inheritEnvironment
-
組態是否繼承應用程式本身的環境。
預設值:
true。 - environment
-
可用於自訂綁定器環境的一組屬性的根目錄。當設定此屬性時,建立綁定器的上下文不是應用程式上下文的子上下文。此設定允許綁定器組件和應用程式組件之間完全隔離。
預設值:
empty。 - defaultCandidate
-
綁定器組態是否為被視為預設綁定器的候選者,或僅在明確參考時才能使用。此設定允許新增綁定器組態,而不會干擾預設處理。
預設值:
true。
實作自訂綁定器
為了實作自訂 Binder,您只需要
-
新增所需的依賴項
-
提供 ProvisioningProvider 實作
-
提供 MessageProducer 實作
-
提供 MessageHandler 實作
-
提供 Binder 實作
-
建立綁定器組態
-
在 META-INF/spring.binders 中定義您的綁定器
新增所需的依賴項
將 spring-cloud-stream 依賴項新增到您的專案(例如,對於 Maven)
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-stream</artifactId>
<version>${spring.cloud.stream.version}</version>
</dependency>提供 ProvisioningProvider 實作
ProvisioningProvider 負責佈建消費者和生產者目的地,並且需要將 application.yml 或 application.properties 檔案中包含的邏輯目的地轉換為實體目的地參考。
以下是 ProvisioningProvider 實作的範例,該實作僅修剪透過輸入/輸出綁定組態提供的目的地
public class FileMessageBinderProvisioner implements ProvisioningProvider<ConsumerProperties, ProducerProperties> {
@Override
public ProducerDestination provisionProducerDestination(
final String name,
final ProducerProperties properties) {
return new FileMessageDestination(name);
}
@Override
public ConsumerDestination provisionConsumerDestination(
final String name,
final String group,
final ConsumerProperties properties) {
return new FileMessageDestination(name);
}
private class FileMessageDestination implements ProducerDestination, ConsumerDestination {
private final String destination;
private FileMessageDestination(final String destination) {
this.destination = destination;
}
@Override
public String getName() {
return destination.trim();
}
@Override
public String getNameForPartition(int partition) {
throw new UnsupportedOperationException("Partitioning is not implemented for file messaging.");
}
}
}
提供 MessageProducer 實作
MessageProducer 負責消費事件並將其作為訊息處理,傳遞給設定為消費這些事件的客戶端應用程式。
以下是 MessageProducer 實作的範例,它擴展了 MessageProducerSupport 抽象,以便輪詢與修剪後的目的地名稱相符且位於專案路徑中的檔案,同時也封存已讀取的訊息並捨棄後續相同的訊息
public class FileMessageProducer extends MessageProducerSupport {
public static final String ARCHIVE = "archive.txt";
private final ConsumerDestination destination;
private String previousPayload;
public FileMessageProducer(ConsumerDestination destination) {
this.destination = destination;
}
@Override
public void doStart() {
receive();
}
private void receive() {
ScheduledExecutorService executorService = Executors.newScheduledThreadPool(1);
executorService.scheduleWithFixedDelay(() -> {
String payload = getPayload();
if(payload != null) {
Message<String> receivedMessage = MessageBuilder.withPayload(payload).build();
archiveMessage(payload);
sendMessage(receivedMessage);
}
}, 0, 50, MILLISECONDS);
}
private String getPayload() {
try {
List<String> allLines = Files.readAllLines(Paths.get(destination.getName()));
String currentPayload = allLines.get(allLines.size() - 1);
if(!currentPayload.equals(previousPayload)) {
previousPayload = currentPayload;
return currentPayload;
}
} catch (IOException e) {
throw new RuntimeException(e);
}
return null;
}
private void archiveMessage(String payload) {
try {
Files.write(Paths.get(ARCHIVE), (payload + "\n").getBytes(), CREATE, APPEND);
} catch (IOException e) {
throw new RuntimeException(e);
}
}
}
| 在實作自訂綁定器時,此步驟並非絕對必要,因為您始終可以求助於使用現有的 MessageProducer 實作! |
提供 MessageHandler 實作
MessageHandler 提供產生事件所需的邏輯。
以下是 MessageHandler 實作的範例
public class FileMessageHandler implements MessageHandler{
@Override
public void handleMessage(Message<?> message) throws MessagingException {
//write message to file
}
}
| 在實作自訂綁定器時,此步驟並非絕對必要,因為您始終可以求助於使用現有的 MessageHandler 實作! |
提供 Binder 實作
您現在可以提供您自己的 Binder 抽象實作。這可以透過以下方式輕鬆完成
-
擴展
AbstractMessageChannelBinder類別 -
將您的 ProvisioningProvider 指定為 AbstractMessageChannelBinder 的泛型參數
-
覆寫
createProducerMessageHandler和createConsumerEndpoint方法
例如:
public class FileMessageBinder extends AbstractMessageChannelBinder<ConsumerProperties, ProducerProperties, FileMessageBinderProvisioner> {
public FileMessageBinder(
String[] headersToEmbed,
FileMessageBinderProvisioner provisioningProvider) {
super(headersToEmbed, provisioningProvider);
}
@Override
protected MessageHandler createProducerMessageHandler(
final ProducerDestination destination,
final ProducerProperties producerProperties,
final MessageChannel errorChannel) throws Exception {
return message -> {
String fileName = destination.getName();
String payload = new String((byte[])message.getPayload()) + "\n";
try {
Files.write(Paths.get(fileName), payload.getBytes(), CREATE, APPEND);
} catch (IOException e) {
throw new RuntimeException(e);
}
};
}
@Override
protected MessageProducer createConsumerEndpoint(
final ConsumerDestination destination,
final String group,
final ConsumerProperties properties) throws Exception {
return new FileMessageProducer(destination);
}
}
建立綁定器組態
嚴格要求您建立 Spring 組態來初始化綁定器實作的 Bean (以及您可能需要的所有其他 Bean)
@Configuration
public class FileMessageBinderConfiguration {
@Bean
@ConditionalOnMissingBean
public FileMessageBinderProvisioner fileMessageBinderProvisioner() {
return new FileMessageBinderProvisioner();
}
@Bean
@ConditionalOnMissingBean
public FileMessageBinder fileMessageBinder(FileMessageBinderProvisioner fileMessageBinderProvisioner) {
return new FileMessageBinder(null, fileMessageBinderProvisioner);
}
}
在 META-INF/spring.binders 中定義您的綁定器
最後,您必須在類別路徑上的 META-INF/spring.binders 檔案中定義您的綁定器,指定綁定器的名稱和您的綁定器組態類別的完整限定名稱
myFileBinder:\
com.example.springcloudstreamcustombinder.config.FileMessageBinderConfiguration組態選項
Spring Cloud Stream 支援一般組態選項以及綁定和綁定器的組態。某些綁定器允許額外的綁定屬性支援中介軟體特定的功能。
組態選項可以透過 Spring Boot 支援的任何機制提供給 Spring Cloud Stream 應用程式。這包括應用程式引數、環境變數以及 YAML 或 .properties 檔案。
綁定服務屬性
這些屬性透過 org.springframework.cloud.stream.config.BindingServiceProperties 公開
- spring.cloud.stream.instanceCount
-
應用程式的已部署實例數。必須在生產者端設定以進行分割。當使用 RabbitMQ 且 Kafka 的
autoRebalanceEnabled=false時,必須在消費者端設定。預設值:
1。 - spring.cloud.stream.instanceIndex
-
應用程式的實例索引:從
0到instanceCount - 1的數字。用於 RabbitMQ 的分割,以及 Kafka 的autoRebalanceEnabled=false情況。在 Cloud Foundry 中自動設定以符合應用程式的實例索引。 - spring.cloud.stream.dynamicDestinations
-
可以動態綁定的目的地列表(例如,在動態路由情境中)。如果設定,則只能綁定列出的目的地。
預設值:空(允許綁定任何目的地)。
- spring.cloud.stream.defaultBinder
-
如果設定了多個綁定器,則要使用的預設綁定器。請參閱 類別路徑上的多個綁定器。
預設值:空。
- spring.cloud.stream.overrideCloudConnectors
-
此屬性僅在
cloud設定檔處於活動狀態且應用程式提供 Spring Cloud Connectors 時適用。如果屬性為false(預設值),則綁定器會偵測到合適的已綁定服務(例如,在 Cloud Foundry 中為 RabbitMQ 綁定器綁定的 RabbitMQ 服務),並使用它來建立連線(通常透過 Spring Cloud Connectors)。當設定為true時,此屬性指示綁定器完全忽略已綁定服務,並依賴 Spring Boot 屬性(例如,依賴環境中為 RabbitMQ 綁定器提供的spring.rabbitmq.*屬性)。此屬性的典型用法是巢狀於自訂環境中,當連接到多個系統時。預設值:
false。 - spring.cloud.stream.bindingRetryInterval
-
當重試建立綁定時的間隔(以秒為單位),例如,當綁定器不支援延遲綁定且 broker(例如,Apache Kafka)關閉時。將其設定為零可將此類條件視為致命錯誤,從而阻止應用程式啟動。
預設值:
30
綁定屬性
綁定屬性是使用 spring.cloud.stream.bindings.<bindingName>.<property>=<value> 的格式提供的。<bindingName> 代表正在組態的綁定的名稱。
例如,對於以下函數
@Bean
public Function<String, String> uppercase() {
return v -> v.toUpperCase();
}
有兩個綁定,分別命名為 uppercase-in-0 用於輸入,以及 uppercase-out-0 用於輸出。請參閱 綁定和綁定名稱 以取得更多詳細資訊。
為了避免重複,Spring Cloud Stream 支援為所有綁定設定值,格式為 spring.cloud.stream.default.<property>=<value> 和 spring.cloud.stream.default.<producer|consumer>.<property>=<value> 用於常見的綁定屬性。
當要避免擴展綁定屬性的重複時,應使用此格式 - spring.cloud.stream.<binder-type>.default.<producer|consumer>.<property>=<value>。
常見綁定屬性
這些屬性透過 org.springframework.cloud.stream.config.BindingProperties 公開
以下綁定屬性適用於輸入和輸出綁定,並且必須以 spring.cloud.stream.bindings.<bindingName>. 為前綴(例如,spring.cloud.stream.bindings.uppercase-in-0.destination=ticktock)。
可以使用 spring.cloud.stream.default 前綴設定預設值(例如 spring.cloud.stream.default.contentType=application/json)。
- destination
-
綁定在已綁定中介軟體上的目標目的地(例如,RabbitMQ 交換器或 Kafka 主題)。如果綁定代表消費者綁定(輸入),則它可以綁定到多個目的地,並且目的地名稱可以指定為逗號分隔的
String值。否則,將使用實際的綁定名稱。此屬性的預設值無法覆寫。 - group
-
綁定的消費者群組。僅適用於輸入綁定。請參閱 消費者群組。
預設值:
null(表示匿名消費者)。 - contentType
-
此綁定的內容類型。請參閱
內容類型協商。預設值:
application/json。 - binder
-
此綁定使用的綁定器。請參閱
類別路徑上的多個綁定器以取得詳細資訊。預設值:
null(如果存在,則使用預設綁定器)。
消費者屬性
這些屬性透過 org.springframework.cloud.stream.binder.ConsumerProperties 公開
以下綁定屬性僅適用於輸入綁定,並且必須以 spring.cloud.stream.bindings.<bindingName>.consumer. 為前綴(例如,spring.cloud.stream.bindings.input.consumer.concurrency=3)。
可以使用 spring.cloud.stream.default.consumer 前綴設定預設值(例如,spring.cloud.stream.default.consumer.headerMode=none)。
- autoStartup
-
表示是否需要自動啟動此消費者
預設值:
true。 - concurrency
-
輸入消費者的並行性。
預設值:
1。 - partitioned
-
消費者是否接收來自已分割生產者的資料。
預設值:
false。 - headerMode
-
當設定為
none時,停用輸入的標頭剖析。僅對不原生支援訊息標頭且需要標頭嵌入的訊息中介軟體有效。當從不支援原生標頭的非 Spring Cloud Stream 應用程式消費資料時,此選項很有用。當設定為headers時,它會使用中介軟體的原生標頭機制。當設定為embeddedHeaders時,它會將標頭嵌入到訊息酬載中。預設值:取決於綁定器實作。
- maxAttempts
-
如果處理失敗,則嘗試處理訊息的次數(包括第一次)。設定為
1以停用重試。預設值:
3。 - backOffInitialInterval
-
重試時的回退初始間隔。
預設值:
1000。 - backOffMaxInterval
-
最大回退間隔。
預設值:
10000。 - backOffMultiplier
-
回退乘數。
預設值:
2.0。 - defaultRetryable
-
未在
retryableExceptions中列出的接聽器擲回的例外是否可重試。預設值:
true。 - instanceCount
-
當設定為大於或等於零的值時,它允許自訂此消費者的實例計數(如果與
spring.cloud.stream.instanceCount不同)。當設定為負值時,它預設為spring.cloud.stream.instanceCount。請參閱實例索引和實例計數以取得更多資訊。預設值:
-1。 - instanceIndex
-
當設定為大於或等於零的值時,它允許自訂此消費者的實例索引(如果與
spring.cloud.stream.instanceIndex不同)。當設定為負值時,它預設為spring.cloud.stream.instanceIndex。如果提供了instanceIndexList,則忽略。請參閱實例索引和實例計數以取得更多資訊。預設值:
-1。 - instanceIndexList
-
與不支援原生分割的綁定器(例如 RabbitMQ)一起使用;允許應用程式實例從多個分割區消費。
預設值:空。
- retryableExceptions
-
鍵中 Throwable 類別名稱和值中布林值的對應。指定將要或不會重試的那些例外 (和子類別)。另請參閱
defaultRetriable。範例:spring.cloud.stream.bindings.input.consumer.retryable-exceptions.java.lang.IllegalStateException=false。預設值:空。
- useNativeDecoding
-
當設定為
true時,輸入訊息會由客戶端程式庫直接反序列化,必須相應地組態客戶端程式庫(例如,設定適當的 Kafka 生產者值反序列化器)。當使用此組態時,輸入訊息的解組不是基於綁定的contentType。當使用原生解碼時,生產者有責任使用適當的編碼器(例如,Kafka 生產者值序列化器)來序列化輸出訊息。此外,當使用原生編碼和解碼時,headerMode=embeddedHeaders屬性會被忽略,且標頭不會嵌入到訊息中。請參閱生產者屬性useNativeEncoding。預設值:
false。 - multiplex
-
當設定為 true 時,底層綁定器將在本機多工處理同一輸入綁定上的目的地。
預設值:
false。
進階消費者組態
為了對訊息驅動消費者的底層訊息監聽器容器進行進階組態,請將單個 ListenerContainerCustomizer Bean 新增到應用程式上下文中。它將在套用上述屬性後被調用,並可用於設定其他屬性。同樣地,對於輪詢消費者,請新增 MessageSourceCustomizer Bean。
以下是 RabbitMQ 綁定器的範例
@Bean
public ListenerContainerCustomizer<AbstractMessageListenerContainer> containerCustomizer() {
return (container, dest, group) -> container.setAdviceChain(advice1, advice2);
}
@Bean
public MessageSourceCustomizer<AmqpMessageSource> sourceCustomizer() {
return (source, dest, group) -> source.setPropertiesConverter(customPropertiesConverter);
}
生產者屬性
這些屬性透過 org.springframework.cloud.stream.binder.ProducerProperties 公開
以下綁定屬性僅適用於輸出綁定,並且必須以 spring.cloud.stream.bindings.<bindingName>.producer. 為前綴(例如,spring.cloud.stream.bindings.func-out-0.producer.partitionKeyExpression=headers.id)。
可以使用前綴 spring.cloud.stream.default.producer 設定預設值(例如,spring.cloud.stream.default.producer.partitionKeyExpression=headers.id)。
- autoStartup
-
表示是否需要自動啟動此消費者
預設值:
true。 - partitionKeyExpression
-
用於決定如何分割輸出資料的 SpEL 表達式。如果設定,則會分割此綁定上的輸出資料。
partitionCount必須設定為大於 1 的值才能生效。請參閱分割支援。預設值:null。
- partitionKeyExtractorName
-
實作
PartitionKeyExtractorStrategy的 Bean 名稱。用於提取用於計算分割區 ID 的鍵(請參閱 'partitionSelector*')。與 'partitionKeyExpression' 互斥。預設值:null。
- partitionSelectorName
-
實作
PartitionSelectorStrategy的 Bean 名稱。用於根據分割區鍵決定分割區 ID(請參閱 'partitionKeyExtractor*')。與 'partitionSelectorExpression' 互斥。預設值:null。
- partitionSelectorExpression
-
用於自訂分割區選擇的 SpEL 表達式。如果兩者都未設定,則分割區會被選為
hashCode(key) % partitionCount,其中key是透過partitionKeyExpression計算的。預設值:
null。 - partitionCount
-
如果啟用分割,則資料的目標分割區數量。如果生產者已分割,則必須設定為大於 1 的值。在 Kafka 上,它被解釋為提示。將使用此值和目標主題的分割區計數中較大的值。
預設值:
1。 - requiredGroups
-
以逗號分隔的群組列表,生產者必須確保訊息傳遞到這些群組,即使這些群組在生產者建立之後才啟動(例如,透過在 RabbitMQ 中預先建立持久佇列)。
- headerMode
-
當設定為
none時,停用輸出的標頭嵌入。僅對不原生支援訊息標頭且需要標頭嵌入的訊息中介軟體有效。當為不支援原生標頭的非 Spring Cloud Stream 應用程式產生資料時,此選項很有用。當設定為headers時,它會使用中介軟體的原生標頭機制。當設定為embeddedHeaders時,它會將標頭嵌入到訊息酬載中。預設值:取決於綁定器實作。
- useNativeEncoding
-
當設定為
true時,輸出訊息會由客戶端程式庫直接序列化,必須相應地組態客戶端程式庫(例如,設定適當的 Kafka 生產者值序列化器)。當使用此組態時,輸出訊息的編組不是基於綁定的contentType。當使用原生編碼時,消費者有責任使用適當的解碼器(例如,Kafka 消費者值反序列化器)來反序列化輸入訊息。此外,當使用原生編碼和解碼時,headerMode=embeddedHeaders屬性會被忽略,且標頭不會嵌入到訊息中。請參閱消費者屬性useNativeDecoding。預設值:
false。 - errorChannelEnabled
-
當設定為 true 時,如果綁定器支援非同步傳送結果,則傳送失敗會傳送到目的地的錯誤通道。請參閱錯誤處理以取得更多資訊。
預設值:false。
進階生產者組態
在某些情況下,生產者屬性不足以正確組態綁定器中的生產 MessageHandler,或者您可能更喜歡在組態此類生產 MessageHandler 時使用程式化方法。無論原因為何,spring-cloud-stream 都提供了 ProducerMessageHandlerCustomizer 來完成此操作。
@FunctionalInterface
public interface ProducerMessageHandlerCustomizer<H extends MessageHandler> {
/**
* Configure a {@link MessageHandler} that is being created by the binder for the
* provided destination name.
* @param handler the {@link MessageHandler} from the binder.
* @param destinationName the bound destination name.
*/
void configure(H handler, String destinationName);
}
如您所見,它讓您可以存取生產 MessageHandler 的實際實例,您可以根據需要進行組態。您只需要提供此策略的實作,並將其組態為 @Bean。
內容類型協商
資料轉換是任何訊息驅動微服務架構的核心功能之一。鑑於在 Spring Cloud Stream 中,此類資料表示為 Spring Message,訊息可能必須在到達目的地之前轉換為所需的形狀或大小。這是由於兩個原因而需要的
-
轉換傳入訊息的內容,以符合應用程式提供的處理常式的簽章。
-
將傳出訊息的內容轉換為線路格式。
線路格式通常是 byte[](對於 Kafka 和 Rabbit 綁定器來說是這樣),但它受綁定器實作的控制。
在 Spring Cloud Stream 中,訊息轉換是透過 org.springframework.messaging.converter.MessageConverter 完成的。
| 作為後續詳細資訊的補充,您可能還想閱讀以下 部落格文章。 |
機制
為了更好地理解內容類型協商背後的機制和必要性,我們透過使用以下訊息處理常式作為範例來查看一個非常簡單的使用案例
public Function<Person, String> personFunction {..}
| 為了簡單起見,我們假設這是應用程式中唯一的處理常式函數(我們假設沒有內部管道)。 |
前面範例中顯示的處理常式預期 Person 物件作為引數,並產生 String 類型作為輸出。為了使框架成功將傳入的 Message 作為引數傳遞給此處理常式,它必須以某種方式將 Message 類型的酬載從線路格式轉換為 Person 類型。換句話說,框架必須找到並套用適當的 MessageConverter。為了完成此操作,框架需要來自使用者的某些指示。其中一個指示已經由處理常式方法本身的簽章提供(Person 類型)。因此,理論上,這應該(並且在某些情況下是)足夠的。但是,對於大多數使用案例,為了選擇適當的 MessageConverter,框架需要額外的資訊。缺少的部分是 contentType。
Spring Cloud Stream 提供了三種機制來定義 contentType(依優先順序排列)
-
標頭:
contentType可以透過訊息本身傳達。透過提供contentType標頭,您宣告要使用的內容類型,以尋找並套用適當的MessageConverter。 -
綁定:可以透過設定
spring.cloud.stream.bindings.input.content-type屬性,為每個目的地綁定設定contentType。屬性名稱中的 input區段對應於目的地的實際名稱(在我們的案例中為 “input”)。此方法可讓您在每個綁定的基礎上宣告要使用的內容類型,以尋找並套用適當的MessageConverter。 -
預設值:如果
contentType不存在於Message標頭或綁定中,則會使用預設的application/json內容類型來尋找並套用適當的MessageConverter。
如前所述,前面的列表也示範了在發生衝突時的優先順序。例如,標頭提供的內容類型優先於任何其他內容類型。對於在每個綁定的基礎上設定的內容類型也是如此,這實質上可讓您覆寫預設內容類型。但是,它也提供了一個合理的預設值(這是根據社群回饋決定的)。
使 application/json 成為預設值的另一個原因是分散式微服務架構驅動的互通性要求,在分散式微服務架構中,生產者和消費者不僅在不同的 JVM 中執行,而且還可以在不同的非 JVM 平台上執行。
當非 void 處理常式方法傳回時,如果傳回值已經是 Message,則該 Message 將成為酬載。但是,當傳回值不是 Message 時,則會使用傳回值作為酬載建構新的 Message,同時從輸入 Message 繼承標頭,減去由 SpringIntegrationProperties.messageHandlerNotPropagatedHeaders 定義或篩選的標頭。預設情況下,那裡只設定了一個標頭:contentType。這表示新的 Message 沒有設定 contentType 標頭,從而確保 contentType 可以演進。您可以隨時選擇不從處理常式方法傳回 Message,在其中您可以注入您想要的任何標頭。
如果存在內部管道,則 Message 會透過相同的轉換過程發送到下一個處理常式。但是,如果沒有內部管道,或者您已到達管道的末端,則 Message 會發送回輸出目的地。
內容類型與引數類型
如前所述,為了讓框架選擇適當的 MessageConverter,它需要引數類型,以及可選的內容類型資訊。用於選擇適當 MessageConverter 的邏輯位於引數解析器(HandlerMethodArgumentResolvers)中,引數解析器在調用使用者定義的處理常式方法之前觸發(這時框架才知道實際的引數類型)。如果引數類型與當前酬載的類型不符,則框架會委派給預先組態的 MessageConverters 堆疊,以查看是否可以轉換酬載。如您所見,MessageConverter 的 Object fromMessage(Message<?> message, Class<?> targetClass); 操作將 targetClass 作為其引數之一。框架還確保提供的 Message 始終包含 contentType 標頭。當沒有 contentType 標頭時,它會注入每個綁定的 contentType 標頭或預設的 contentType 標頭。contentType 引數類型的組合是框架確定訊息是否可以轉換為目標類型的機制。如果找不到適當的 MessageConverter,則會擲回例外,您可以透過新增自訂 MessageConverter 來處理例外(請參閱 使用者定義的訊息轉換器)。
但是,如果酬載類型與處理常式方法宣告的目標類型相符怎麼辦?在這種情況下,沒有什麼需要轉換的,並且酬載會未經修改地傳遞。雖然這聽起來非常簡單且合乎邏輯,但請記住將 Message<?> 或 Object 作為引數的處理常式方法。透過將目標類型宣告為 Object(它是 Java 中一切事物的 instanceof),您實際上放棄了轉換過程。
不要期望僅基於 contentType 將 Message 轉換為某些其他類型。請記住,contentType 是目標類型的補充。如果您願意,可以提供提示,MessageConverter 可能會或可能不會考慮該提示。 |
訊息轉換器
MessageConverters 定義了兩個方法
Object fromMessage(Message<?> message, Class<?> targetClass);
Message<?> toMessage(Object payload, @Nullable MessageHeaders headers);
重要的是要理解這些方法的合約及其用法,特別是在 Spring Cloud Stream 的上下文中。
fromMessage 方法將傳入的 Message 轉換為引數類型。Message 的酬載可以是任何類型,並且由 MessageConverter 的實際實作來支援多種類型。例如,某些 JSON 轉換器可能支援 byte[]、String 和其他類型的酬載類型。當應用程式包含內部管道時(即,輸入 → 處理常式 1 → 處理常式 2 → . . . → 輸出),並且上游處理常式的輸出導致 Message 可能不是初始線路格式時,這很重要。
但是,toMessage 方法具有更嚴格的合約,並且必須始終將 Message 轉換為線路格式:byte[]。
因此,就所有意圖和目的而言(尤其是在實作您自己的轉換器時),您將這兩種方法視為具有以下簽章
Object fromMessage(Message<?> message, Class<?> targetClass);
Message<byte[]> toMessage(Object payload, @Nullable MessageHeaders headers);
提供的 MessageConverters
如前所述,框架已經提供了一堆 MessageConverters 來處理最常見的使用案例。以下列表描述了提供的 MessageConverters,依優先順序排列(使用第一個有效的 MessageConverter)
-
JsonMessageConverter:顧名思義,它支援在contentType為application/json(預設值)時,將Message的酬載轉換為/從 POJO。 -
ByteArrayMessageConverter:支援在contentType為application/octet-stream時,將Message的酬載從byte[]轉換為byte[]。它本質上是一個直通,主要用於向後相容性。 -
ObjectStringMessageConverter:當contentType為text/plain時,支援將任何類型轉換為String。它會調用 Object 的toString()方法,或者,如果酬載是byte[],則為新的String(byte[])。
當找不到適當的轉換器時,框架會擲回例外。發生這種情況時,您應該檢查您的程式碼和組態,並確保您沒有遺漏任何內容(也就是說,確保您透過使用綁定或標頭提供了 contentType)。但是,最有可能的是,您找到了一些不常見的情況(例如自訂 contentType),並且當前提供的 MessageConverters 堆疊不知道如何轉換。如果是這種情況,您可以新增自訂 MessageConverter。請參閱 使用者定義的訊息轉換器。
使用者定義的訊息轉換器
Spring Cloud Stream 公開了一種機制來定義和註冊額外的 MessageConverter。要使用它,請實作 org.springframework.messaging.converter.MessageConverter,並將其組態為 @Bean。然後將其附加到現有的 MessageConverter 堆疊。
重要的是要理解,自訂 MessageConverter 實作會新增到現有堆疊的頭部。因此,自訂 MessageConverter 實作優先於現有的實作,這可讓您覆寫和新增到現有的轉換器。 |
以下範例顯示如何建立訊息轉換器 Bean 以支援名為 application/bar 的新內容類型
@SpringBootApplication
public static class SinkApplication {
...
@Bean
public MessageConverter customMessageConverter() {
return new MyCustomMessageConverter();
}
}
public class MyCustomMessageConverter extends AbstractMessageConverter {
public MyCustomMessageConverter() {
super(new MimeType("application", "bar"));
}
@Override
protected boolean supports(Class<?> clazz) {
return (Bar.class.equals(clazz));
}
@Override
protected Object convertFromInternal(Message<?> message, Class<?> targetClass, Object conversionHint) {
Object payload = message.getPayload();
return (payload instanceof Bar ? payload : new Bar((byte[]) payload));
}
}
應用程式間通訊
Spring Cloud Stream 啟用應用程式之間的通訊。應用程式間通訊是一個複雜的問題,涵蓋多個方面,如下列主題所述
連接多個應用程式實例
雖然 Spring Cloud Stream 使個別 Spring Boot 應用程式可以輕鬆連接到訊息系統,但 Spring Cloud Stream 的典型情境是建立多應用程式管道,其中微服務應用程式彼此傳送資料。您可以透過關聯「相鄰」應用程式的輸入和輸出目的地來實現此情境。
假設設計要求時間來源應用程式將資料傳送到日誌接收器應用程式。您可以為兩個應用程式內的綁定使用名為 ticktock 的通用目的地。
時間來源(具有名為 output 的綁定)將設定以下屬性
spring.cloud.stream.bindings.output.destination=ticktock
日誌接收器(具有名為 input 的綁定)將設定以下屬性
spring.cloud.stream.bindings.input.destination=ticktock
實例索引和實例計數
當擴展 Spring Cloud Stream 應用程式時,每個實例都可以接收有關同一應用程式存在多少其他實例以及其自身實例索引的資訊。Spring Cloud Stream 透過 spring.cloud.stream.instanceCount 和 spring.cloud.stream.instanceIndex 屬性來完成此操作。例如,如果有三個 HDFS 接收器應用程式的實例,則所有三個實例的 spring.cloud.stream.instanceCount 都設定為 3,並且個別應用程式的 spring.cloud.stream.instanceIndex 分別設定為 0、1 和 2。
當 Spring Cloud Stream 應用程式透過 Spring Cloud Data Flow 部署時,這些屬性會自動組態;當 Spring Cloud Stream 應用程式獨立啟動時,必須正確設定這些屬性。預設情況下,spring.cloud.stream.instanceCount 為 1,spring.cloud.stream.instanceIndex 為 0。
在擴展情境中,正確組態這兩個屬性對於解決分割行為非常重要(請參閱下文),並且某些綁定器(例如,Kafka 綁定器)始終需要這兩個屬性,以確保資料在多個消費者實例之間正確分割。
分割
Spring Cloud Stream 中的分割包含兩個任務
組態輸出綁定以進行分割
您可以透過設定其 partitionKeyExpression 或 partitionKeyExtractorName 屬性之一(且僅設定其中一個)以及其 partitionCount 屬性,來組態輸出綁定以傳送已分割的資料。
例如,以下是一個有效且典型的組態
spring.cloud.stream.bindings.func-out-0.producer.partitionKeyExpression=headers.id spring.cloud.stream.bindings.func-out-0.producer.partitionCount=5
根據該範例組態,資料會透過以下邏輯傳送至目標分割區。
分割區金鑰的值是針對傳送至分割輸出綁定的每則訊息計算而得,計算依據是 partitionKeyExpression。partitionKeyExpression 是一個 SpEL 運算式,會針對輸出訊息進行評估(在前述範例中,它是訊息標頭中 id 的值),以擷取分割金鑰。
如果 SpEL 運算式不足以滿足您的需求,您可以改為提供 org.springframework.cloud.stream.binder.PartitionKeyExtractorStrategy 的實作,並將其設定為 bean(使用 @Bean 註解),藉此計算分割區金鑰值。如果您在應用程式內容中有多個 org.springframework.cloud.stream.binder.PartitionKeyExtractorStrategy 類型的 bean 可用,您可以進一步使用 partitionKeyExtractorName 屬性指定其名稱來篩選它,如下列範例所示
--spring.cloud.stream.bindings.func-out-0.producer.partitionKeyExtractorName=customPartitionKeyExtractor
--spring.cloud.stream.bindings.func-out-0.producer.partitionCount=5
. . .
@Bean
public CustomPartitionKeyExtractorClass customPartitionKeyExtractor() {
return new CustomPartitionKeyExtractorClass();
}在 Spring Cloud Stream 的先前版本中,您可以透過設定 spring.cloud.stream.bindings.output.producer.partitionKeyExtractorClass 屬性來指定 org.springframework.cloud.stream.binder.PartitionKeyExtractorStrategy 的實作。自 3.0 版起,已移除此屬性。 |
一旦計算出訊息金鑰,分割區選取程序就會將目標分割區決定為介於 0 和 partitionCount - 1 之間的值。在大多數情況下適用的預設計算是根據以下公式:key.hashCode() % partitionCount。這可以在繫結上自訂,方法是設定要針對 'key' 評估的 SpEL 運算式(透過 partitionSelectorExpression 屬性),或是將 org.springframework.cloud.stream.binder.PartitionSelectorStrategy 的實作設定為 bean(使用 @Bean 註解)。與 PartitionKeyExtractorStrategy 類似,當應用程式內容中有多個此類型的 bean 可用時,您可以進一步使用 spring.cloud.stream.bindings.output.producer.partitionSelectorName 屬性來篩選它,如下列範例所示
--spring.cloud.stream.bindings.func-out-0.producer.partitionSelectorName=customPartitionSelector
. . .
@Bean
public CustomPartitionSelectorClass customPartitionSelector() {
return new CustomPartitionSelectorClass();
}在 Spring Cloud Stream 的先前版本中,您可以透過設定 spring.cloud.stream.bindings.output.producer.partitionSelectorClass 屬性來指定 org.springframework.cloud.stream.binder.PartitionSelectorStrategy 的實作。自 3.0 版起,已移除此屬性。 |
設定分割的輸入綁定
輸入綁定(綁定名稱為 uppercase-in-0)設定為接收分割資料,方法是在應用程式本身上設定其 partitioned 屬性,以及 instanceIndex 和 instanceCount 屬性,如下列範例所示
spring.cloud.stream.bindings.uppercase-in-0.consumer.partitioned=true spring.cloud.stream.instanceIndex=3 spring.cloud.stream.instanceCount=5
instanceCount 值代表應該在其中分割資料的應用程式實例總數。instanceIndex 在多個實例之間必須是唯一值,值介於 0 和 instanceCount - 1 之間。實例索引可協助每個應用程式實例識別它從中接收資料的唯一分割區。對於使用不原生支援分割技術的綁定器而言,這是必要的。例如,對於 RabbitMQ,每個分割區都有一個佇列,佇列名稱包含實例索引。對於 Kafka,如果 autoRebalanceEnabled 為 true(預設值),Kafka 會負責在實例之間分配分割區,而且這些屬性不是必要的。如果 autoRebalanceEnabled 設定為 false,則綁定器會使用 instanceCount 和 instanceIndex 來判斷實例訂閱哪些分割區(您必須至少有與實例一樣多的分割區)。綁定器會分配分割區,而不是 Kafka。如果您希望特定分割區的訊息始終傳送到相同的實例,這可能會很有用。當綁定器組態需要它們時,務必正確設定這兩個值,以確保所有資料都已取用,且應用程式實例接收互斥的資料集。
雖然在獨立案例中,使用多個實例進行分割資料處理的場景可能很難設定,但 Spring Cloud Dataflow 可以顯著簡化此程序,方法是正確填入輸入和輸出值,並讓您依賴執行階段基礎架構來提供有關實例索引和實例計數的資訊。
測試
Spring Cloud Stream 提供支援來測試您的微服務應用程式,而無需連線至訊息傳遞系統。
Spring Integration 測試綁定器
Spring Cloud Stream 隨附一個測試綁定器,您可以用於測試各種應用程式元件,而無需實際的真實世界綁定器實作或訊息代理程式。
此測試綁定器充當單元和整合測試之間的橋樑,並且基於 Spring Integration 框架作為 JVM 內訊息代理程式,基本上為您提供兩全其美的優勢 - 真實的綁定器而無需網路連線。
測試綁定器組態
若要啟用 Spring Integration 測試綁定器,您只需將其新增為相依性即可。
新增必要的相依性
以下是必要 Maven POM 項目的範例。
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-stream-test-binder</artifactId>
<scope>test</scope>
</dependency>或用於 build.gradle.kts
testImplementation("org.springframework.cloud:spring-cloud-stream-test-binder")
測試綁定器用法
現在您可以將您的微服務作為簡單的單元測試進行測試
@SpringBootTest
public class SampleStreamTests {
@Autowired
private InputDestination input;
@Autowired
private OutputDestination output;
@Test
public void testEmptyConfiguration() {
this.input.send(new GenericMessage<byte[]>("hello".getBytes()));
assertThat(output.receive().getPayload()).isEqualTo("HELLO".getBytes());
}
@SpringBootApplication
@Import(TestChannelBinderConfiguration.class)
public static class SampleConfiguration {
@Bean
public Function<String, String> uppercase() {
return v -> v.toUpperCase();
}
}
}
如果您需要更多控制權,或想要在同一個測試套件中測試多個組態,您也可以執行以下操作
@EnableAutoConfiguration
public static class MyTestConfiguration {
@Bean
public Function<String, String> uppercase() {
return v -> v.toUpperCase();
}
}
. . .
@Test
public void sampleTest() {
try (ConfigurableApplicationContext context = new SpringApplicationBuilder(
TestChannelBinderConfiguration.getCompleteConfiguration(
MyTestConfiguration.class))
.run("--spring.cloud.function.definition=uppercase")) {
InputDestination source = context.getBean(InputDestination.class);
OutputDestination target = context.getBean(OutputDestination.class);
source.send(new GenericMessage<byte[]>("hello".getBytes()));
assertThat(target.receive().getPayload()).isEqualTo("HELLO".getBytes());
}
}
對於您有多個綁定和/或多個輸入和輸出的情況,或者只是想明確說明您要傳送至或接收自的目的地名稱,InputDestination 和 OutputDestination 的 send() 和 receive() 方法會被覆寫,以允許您提供輸入和輸出目的地的名稱。
考慮以下範例
@EnableAutoConfiguration
public static class SampleFunctionConfiguration {
@Bean
public Function<String, String> uppercase() {
return value -> value.toUpperCase();
}
@Bean
public Function<String, String> reverse() {
return value -> new StringBuilder(value).reverse().toString();
}
}
以及實際的測試
@Test
public void testMultipleFunctions() {
try (ConfigurableApplicationContext context = new SpringApplicationBuilder(
TestChannelBinderConfiguration.getCompleteConfiguration(
SampleFunctionConfiguration.class))
.run("--spring.cloud.function.definition=uppercase;reverse")) {
InputDestination inputDestination = context.getBean(InputDestination.class);
OutputDestination outputDestination = context.getBean(OutputDestination.class);
Message<byte[]> inputMessage = MessageBuilder.withPayload("Hello".getBytes()).build();
inputDestination.send(inputMessage, "uppercase-in-0");
inputDestination.send(inputMessage, "reverse-in-0");
Message<byte[]> outputMessage = outputDestination.receive(0, "uppercase-out-0");
assertThat(outputMessage.getPayload()).isEqualTo("HELLO".getBytes());
outputMessage = outputDestination.receive(0, "reverse-out-0");
assertThat(outputMessage.getPayload()).isEqualTo("olleH".getBytes());
}
}
對於您有其他對應屬性(例如 destination)的情況,您應該使用這些名稱。例如,考慮先前測試的不同版本,其中我們明確地將 uppercase 函數的輸入和輸出對應到 myInput 和 myOutput 綁定名稱
@Test
public void testMultipleFunctions() {
try (ConfigurableApplicationContext context = new SpringApplicationBuilder(
TestChannelBinderConfiguration.getCompleteConfiguration(
SampleFunctionConfiguration.class))
.run(
"--spring.cloud.function.definition=uppercase;reverse",
"--spring.cloud.stream.bindings.uppercase-in-0.destination=myInput",
"--spring.cloud.stream.bindings.uppercase-out-0.destination=myOutput"
)) {
InputDestination inputDestination = context.getBean(InputDestination.class);
OutputDestination outputDestination = context.getBean(OutputDestination.class);
Message<byte[]> inputMessage = MessageBuilder.withPayload("Hello".getBytes()).build();
inputDestination.send(inputMessage, "myInput");
inputDestination.send(inputMessage, "reverse-in-0");
Message<byte[]> outputMessage = outputDestination.receive(0, "myOutput");
assertThat(outputMessage.getPayload()).isEqualTo("HELLO".getBytes());
outputMessage = outputDestination.receive(0, "reverse-out-0");
assertThat(outputMessage.getPayload()).isEqualTo("olleH".getBytes());
}
}
測試綁定器和 PollableMessageSource
當您使用 PollableMessageSource 時,Spring Integration 測試綁定器也允許您編寫測試(請參閱 使用輪詢消費者 以取得更多詳細資訊)。
不過,需要理解的重要事項是,輪詢不是事件驅動的,而且 PollableMessageSource 是一種策略,它公開產生(輪詢)訊息(單數)的操作。您輪詢的頻率或您使用的執行緒數,或您從哪裡輪詢(訊息佇列或檔案系統)完全取決於您;換句話說,配置 Poller 或 Threads 或訊息的實際來源是您的責任。幸運的是,Spring 有大量抽象概念可以準確地配置它。
讓我們看一個範例
@Test
public void samplePollingTest() {
ApplicationContext context = new SpringApplicationBuilder(SamplePolledConfiguration.class)
.web(WebApplicationType.NONE)
.run("--spring.jmx.enabled=false", "--spring.cloud.stream.pollable-source=myDestination");
OutputDestination destination = context.getBean(OutputDestination.class);
System.out.println("Message 1: " + new String(destination.receive().getPayload()));
System.out.println("Message 2: " + new String(destination.receive().getPayload()));
System.out.println("Message 3: " + new String(destination.receive().getPayload()));
}
@Import(TestChannelBinderConfiguration.class)
@EnableAutoConfiguration
public static class SamplePolledConfiguration {
@Bean
public ApplicationRunner poller(PollableMessageSource polledMessageSource, StreamBridge output, TaskExecutor taskScheduler) {
return args -> {
taskScheduler.execute(() -> {
for (int i = 0; i < 3; i++) {
try {
if (!polledMessageSource.poll(m -> {
String newPayload = ((String) m.getPayload()).toUpperCase();
output.send("myOutput", newPayload);
})) {
Thread.sleep(2000);
}
}
catch (Exception e) {
// handle failure
}
}
});
};
}
}
以上(非常基本的)範例將在 2 秒間隔內產生 3 則訊息,並將它們傳送到 Source 的輸出目的地,此綁定器會將其傳送到 OutputDestination,我們在其中擷取它們(用於任何斷言)。目前,它會印出以下內容
Message 1: POLLED DATA
Message 2: POLLED DATA
Message 3: POLLED DATA如您所見,資料是相同的。這是因為此綁定器定義了實際 MessageSource 的預設實作 - 從中使用 poll() 操作輪詢訊息的來源。雖然對於大多數測試場景來說已足夠,但在某些情況下,您可能想要定義自己的 MessageSource。若要這樣做,只需在您的測試組態中配置 MessageSource 類型的 bean,並提供您自己的訊息來源實作即可。
以下是範例
@Bean
public MessageSource<?> source() {
return () -> new GenericMessage<>("My Own Data " + UUID.randomUUID());
}
呈現以下輸出;
Message 1: MY OWN DATA 1C180A91-E79F-494F-ABF4-BA3F993710DA
Message 2: MY OWN DATA D8F3A477-5547-41B4-9434-E69DA7616FEE
Message 3: MY OWN DATA 20BF2E64-7FF4-4CB6-A823-4053D30B5C74請勿將此 bean 命名為 messageSource,因為它會與 Spring Boot 針對不相關原因提供的同名 (不同類型) bean 衝突。 |
關於混合測試綁定器和常規中介軟體綁定器進行測試的特別注意事項
Spring Integration 基礎測試綁定器用於測試應用程式,而無需涉及實際的基於中介軟體的綁定器,例如 Kafka 或 RabbitMQ 綁定器。如以上章節所述,測試綁定器可協助您透過依賴記憶體內 Spring Integration 通道來快速驗證應用程式行為。當測試綁定器存在於測試類別路徑上時,Spring Cloud Stream 將嘗試針對所有需要綁定器進行通訊的測試目的使用此綁定器。換句話說,您無法在同一個模組中混合測試綁定器和常規中介軟體綁定器以進行測試。在使用測試綁定器測試應用程式之後,如果您想要繼續使用實際的中介軟體綁定器進行進一步的整合測試,建議將使用實際綁定器的那些測試新增到單獨的模組中,以便這些測試可以正確連線到實際的中介軟體,而不是依賴測試綁定器提供的記憶體內通道。
健康指示器
Spring Cloud Stream 為綁定器提供健康指示器。它以名稱 binders 註冊,並且可以透過設定 management.health.binders.enabled 屬性來啟用或停用。
若要啟用健康檢查,您首先需要透過包含其相依性來啟用 "web" 和 "actuator"(請參閱 綁定視覺化和控制)
如果應用程式未明確設定 management.health.binders.enabled,則會將 management.health.defaults.enabled 比對為 true,並且會啟用綁定器健康指示器。如果您想要完全停用健康指示器,則必須將 management.health.binders.enabled 設定為 false。
您可以使用 Spring Boot actuator 健康端點來存取健康指示器 - /actuator/health。預設情況下,當您點擊上述端點時,您只會收到頂層應用程式狀態。為了從綁定器特定的健康指示器接收完整詳細資訊,您需要在應用程式中包含屬性 management.endpoint.health.show-details,其值為 ALWAYS。
健康指示器是綁定器特定的,某些綁定器實作可能不一定會提供健康指示器。
如果您想要完全停用所有現成的健康指示器,而是提供您自己的健康指示器,您可以透過將屬性 management.health.binders.enabled 設定為 false,然後在您的應用程式中提供您自己的 HealthIndicator bean 來實現。在這種情況下,來自 Spring Boot 的健康指示器基礎架構仍會選取這些自訂 bean。即使您未停用綁定器健康指示器,您仍然可以透過在現成的健康檢查之外提供您自己的 HealthIndicator bean 來增強健康檢查。
當您在同一個應用程式中有多個綁定器時,健康指示器預設為啟用,除非應用程式透過將 management.health.binders.enabled 設定為 false 來關閉它們。在這種情況下,如果使用者想要針對綁定器的子集停用健康檢查,則應該透過在多個綁定器組態的環境中將 management.health.binders.enabled 設定為 false 來完成。請參閱 連線至多個系統,以取得有關如何提供特定於環境的屬性的詳細資訊。
如果類別路徑中存在多個綁定器,但並非所有綁定器都在應用程式中使用,這可能會在健康指示器的上下文中造成一些問題。關於如何執行健康檢查,可能存在特定於實作的詳細資訊。例如,如果綁定器未註冊任何目的地,則 Kafka 綁定器可能會將狀態決定為 DOWN。
讓我們來看一個具體情況。假設您的類別路徑中同時存在 Kafka 和 Kafka Streams 綁定器,但在應用程式程式碼中僅使用 Kafka Streams 綁定器,即僅使用 Kafka Streams 綁定器提供綁定。由於 Kafka 綁定器未使用,並且它具有檢查是否註冊任何目的地的特定檢查,因此綁定器健康檢查將會失敗。頂層應用程式健康檢查狀態將報告為 DOWN。在這種情況下,您可以從您的應用程式中移除 kafka 綁定器的相依性,因為您未使用它。
範例
如需 Spring Cloud Stream 範例,請參閱 GitHub 上的 spring-cloud-stream-samples 儲存庫。
在 CloudFoundry 上部署 Stream 應用程式
在 CloudFoundry 上,服務通常透過名為 VCAP_SERVICES 的特殊環境變數公開。
在組態您的綁定器連線時,您可以使用環境變數中的值,如 dataflow Cloud Foundry Server 文件中所述。
綁定器實作
以下是可用的綁定器實作清單
正如先前所述,綁定器抽象也是框架的擴充點之一。因此,如果您在先前的清單中找不到合適的綁定器,您可以在 Spring Cloud Stream 之上實作您自己的綁定器。在 如何從頭開始建立 Spring Cloud Stream 綁定器 文章中,一位社群成員使用範例詳細記錄了實作自訂綁定器所需的步驟集。這些步驟也在 實作自訂綁定器 章節中重點介紹。