3.0.13.RELEASE
參考指南
本指南描述了 Spring Cloud Stream Binder 的 Apache Kafka 實作。它包含關於其設計、用法和組態選項的資訊,以及 Stream Cloud Stream 概念如何映射到 Apache Kafka 特定結構的資訊。此外,本指南還說明了 Spring Cloud Stream 的 Kafka Streams 綁定功能。
1. Apache Kafka Binder
1.1. 用法
要使用 Apache Kafka binder,您需要將 spring-cloud-stream-binder-kafka 作為依賴項添加到您的 Spring Cloud Stream 應用程式,如下面的 Maven 範例所示
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-stream-binder-kafka</artifactId>
</dependency>或者,您也可以使用 Spring Cloud Stream Kafka Starter,如下面的 Maven 範例所示
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-stream-kafka</artifactId>
</dependency>1.2. 概述
下圖顯示了 Apache Kafka binder 如何運作的簡化圖
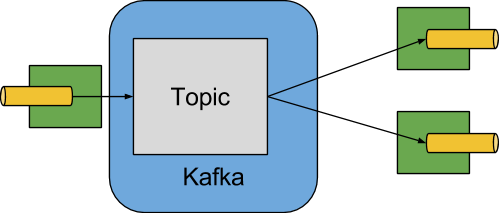
Apache Kafka Binder 實作將每個目的地映射到一個 Apache Kafka 主題。消費者群組直接映射到相同的 Apache Kafka 概念。分割也直接映射到 Apache Kafka 分割區。
binder 目前使用 Apache Kafka kafka-clients 版本 2.3.1。此客戶端可以與較舊的 brokers 通訊 (請參閱 Kafka 文件),但某些功能可能不可用。例如,對於早於 0.11.x.x 的版本,不支援原生標頭。此外,0.11.x.x 不支援 autoAddPartitions 屬性。
1.3. 組態選項
本節包含 Apache Kafka binder 使用的組態選項。
有關與 binder 相關的通用組態選項和屬性,請參閱核心文件中的 綁定屬性。
1.3.1. Kafka Binder 屬性
- spring.cloud.stream.kafka.binder.brokers
-
Kafka binder 連接的 brokers 列表。
預設值:
localhost。 - spring.cloud.stream.kafka.binder.defaultBrokerPort
-
brokers允許指定帶或不帶埠資訊的主機 (例如,host1,host2:port2)。當 broker 列表中未組態埠時,此設定預設埠。預設值:
9092。 - spring.cloud.stream.kafka.binder.configuration
-
傳遞給 binder 建立的所有客戶端的客戶端屬性 (生產者和消費者) 的鍵/值對應。由於這些屬性由生產者和消費者使用,因此用法應限制為通用屬性,例如安全性設定。通過此組態提供的未知 Kafka 生產者或消費者屬性將被過濾掉,並且不允許傳播。此處的屬性取代在 boot 中設定的任何屬性。
預設值:空對應。
- spring.cloud.stream.kafka.binder.consumerProperties
-
任意 Kafka 客戶端消費者屬性的鍵/值對應。除了支援已知的 Kafka 消費者屬性外,此處也允許未知的消費者屬性。此處的屬性取代在 boot 和上面的
configuration屬性中設定的任何屬性。預設值:空對應。
- spring.cloud.stream.kafka.binder.headers
-
binder 傳輸的自訂標頭列表。僅在與版本較舊的應用程式 (⇐ 1.3.x) 以及
kafka-clients版本 < 0.11.0.0 通訊時才需要。較新版本原生支援標頭。預設值:空。
- spring.cloud.stream.kafka.binder.healthTimeout
-
等待獲取分割區資訊的時間 (秒)。如果此計時器過期,則健康報告為關閉。
預設值:10。
- spring.cloud.stream.kafka.binder.requiredAcks
-
broker 上所需的確認數。請參閱 Kafka 文件以了解生產者
acks屬性。預設值:
1。 - spring.cloud.stream.kafka.binder.minPartitionCount
-
僅在設定
autoCreateTopics或autoAddPartitions時有效。binder 在其生產或消費資料的主題上組態的全域最小分割區數。它可以被生產者的partitionCount設定或生產者的instanceCount * concurrency設定值 (如果任一值較大) 取代。預設值:
1。 - spring.cloud.stream.kafka.binder.producerProperties
-
任意 Kafka 客戶端生產者屬性的鍵/值對應。除了支援已知的 Kafka 生產者屬性外,此處也允許未知的生產者屬性。此處的屬性取代在 boot 和上面的
configuration屬性中設定的任何屬性。預設值:空對應。
- spring.cloud.stream.kafka.binder.replicationFactor
-
如果
autoCreateTopics處於活動狀態,則自動建立主題的複寫因數。可以在每個綁定上覆寫。如果您使用的 Kafka broker 版本早於 2.4,則此值應設定為至少 1。從 3.0.8 版開始,binder 使用-1作為預設值,表示 broker 'default.replication.factor' 屬性將用於確定複本數。請諮詢您的 Kafka broker 管理員,以查看是否有需要最小複寫因數的策略,如果有的話,通常 'default.replication.factor' 將與該值匹配,並且應使用-1,除非您需要大於最小值的複寫因數。預設值:
-1。 - spring.cloud.stream.kafka.binder.autoCreateTopics
-
如果設定為
true,則 binder 會自動建立新主題。如果設定為false,則 binder 依賴於已組態的主題。在後一種情況下,如果主題不存在,則 binder 無法啟動。此設定獨立於 broker 的 auto.create.topics.enable設定,並且不影響它。如果伺服器設定為自動建立主題,則它們可能會作為元數據檢索請求的一部分建立,並使用預設 broker 設定。預設值:
true。 - spring.cloud.stream.kafka.binder.autoAddPartitions
-
如果設定為
true,則 binder 會在需要時建立新的分割區。如果設定為false,則 binder 依賴於已組態的主題的分割區大小。如果目標主題的分割區計數小於預期值,則 binder 無法啟動。預設值:
false。 - spring.cloud.stream.kafka.binder.transaction.transactionIdPrefix
-
在 binder 中啟用交易。請參閱 Kafka 文件中的
transaction.id和spring-kafka文件中的 交易。啟用交易後,將忽略個別producer屬性,並且所有生產者都使用spring.cloud.stream.kafka.binder.transaction.producer.*屬性。預設值
null(無交易) - spring.cloud.stream.kafka.binder.transaction.producer.*
-
交易式 binder 中生產者的全域生產者屬性。請參閱
spring.cloud.stream.kafka.binder.transaction.transactionIdPrefix和 Kafka 生產者屬性 以及所有 binder 支援的通用生產者屬性。預設值:請參閱個別生產者屬性。
- spring.cloud.stream.kafka.binder.headerMapperBeanName
-
用於將
spring-messaging標頭映射到 Kafka 標頭和從 Kafka 標頭映射回來的KafkaHeaderMapper的 bean 名稱。例如,如果您希望自訂BinderHeaderMapperbean 中使用 JSON 反序列化標頭的受信任套件,請使用此選項。如果此自訂BinderHeaderMapperbean 沒有使用此屬性提供給 binder,則 binder 將在回退到 binder 建立的預設BinderHeaderMapper之前,尋找名稱為kafkaBinderHeaderMapper且類型為BinderHeaderMapper的標頭映射器 bean。預設值:無。
- spring.cloud.stream.kafka.binder.considerDownWhenAnyPartitionHasNoLeader
-
當主題上的任何分割區 (無論是哪個消費者正在接收來自該分割區的資料) 被發現沒有領導者時,將 binder 健康狀態設定為
down的標誌。預設值:
false。 - spring.cloud.stream.kafka.binder.certificateStoreDirectory
-
當信任儲存區或金鑰儲存區憑證位置作為類路徑 URL (
classpath:…) 給出時,binder 會將 JAR 檔案內類路徑位置的資源複製到檔案系統上的位置。檔案將移動到指定為此屬性值的location,該位置必須是檔案系統上應用程式執行進程可寫入的現有目錄。如果未設定此值,並且憑證檔案是類路徑資源,則它將移動到系統的臨時目錄,如System.getProperty("java.io.tmpdir")返回的那樣。如果此值存在,但無法在檔案系統上找到目錄或目錄不可寫入,則也是如此。預設值:無。
1.3.2. Kafka 消費者屬性
為了避免重複,Spring Cloud Stream 支援設定所有通道的值,格式為 spring.cloud.stream.kafka.default.consumer.<property>=<value>。 |
以下屬性僅適用於 Kafka 消費者,並且必須以 spring.cloud.stream.kafka.bindings.<channelName>.consumer. 為前綴。
- admin.configuration
-
自 2.1.1 版起,此屬性已被棄用,改用
topic.properties,並且對它的支援將在未來版本中移除。 - admin.replicas-assignment
-
自 2.1.1 版起,此屬性已被棄用,改用
topic.replicas-assignment,並且對它的支援將在未來版本中移除。 - admin.replication-factor
-
自 2.1.1 版起,此屬性已被棄用,改用
topic.replication-factor,並且對它的支援將在未來版本中移除。 - autoRebalanceEnabled
-
當
true時,主題分割區會在消費者群組的成員之間自動重新平衡。當false時,每個消費者都根據spring.cloud.stream.instanceCount和spring.cloud.stream.instanceIndex分配一組固定的分割區。這需要適當地在每個啟動的實例上設定spring.cloud.stream.instanceCount和spring.cloud.stream.instanceIndex屬性。在這種情況下,spring.cloud.stream.instanceCount屬性的值通常必須大於 1。預設值:
true。 - ackEachRecord
-
當
autoCommitOffset為true時,此設定指示是否在處理每個記錄後提交偏移量。預設情況下,在處理完consumer.poll()返回的記錄批次中的所有記錄後提交偏移量。可以使用消費者configuration屬性設定的max.poll.recordsKafka 屬性來控制輪詢返回的記錄數。將此設定為true可能會導致效能下降,但這樣做可以減少發生故障時重新傳遞記錄的可能性。另請參閱 binderrequiredAcks屬性,它也會影響提交偏移量的效能。預設值:
false。 - autoCommitOffset
-
是否在處理完訊息後自動提交偏移量。如果設定為
false,則類型為org.springframework.kafka.support.Acknowledgment標頭且鍵為kafka_acknowledgment的標頭將出現在輸入訊息中。應用程式可以使用此標頭來確認訊息。有關詳細資訊,請參閱範例章節。當此屬性設定為false時,Kafka binder 會將確認模式設定為org.springframework.kafka.listener.AbstractMessageListenerContainer.AckMode.MANUAL,並且應用程式負責確認記錄。另請參閱ackEachRecord。預設值:
true。 - autoCommitOnError
-
僅在
autoCommitOffset設定為true時有效。如果設定為false,則會抑制導致錯誤的訊息的自動提交,並且僅提交成功的訊息。它允許串流在發生持久性故障時,從上次成功處理的訊息自動重播。如果設定為true,則始終自動提交 (如果啟用了自動提交)。如果未設定 (預設值),則它實際上具有與enableDlq相同的值,如果錯誤訊息已發送到 DLQ,則自動提交錯誤訊息,否則不提交。預設值:未設定。
- resetOffsets
-
是否將消費者上的偏移量重設為 startOffset 提供的值。如果提供了
KafkaRebalanceListener,則必須為 false;請參閱 使用 KafkaRebalanceListener。預設值:
false。 - startOffset
-
新群組的起始偏移量。允許的值:
earliest和latest。如果為消費者 'binding' (通過spring.cloud.stream.bindings.<channelName>.group) 明確設定了消費者群組,則 'startOffset' 設定為earliest。否則,對於anonymous消費者群組,它設定為latest。另請參閱resetOffsets(在此列表的前面)。預設值:null (等效於
earliest)。 - enableDlq
-
設定為 true 時,它會為消費者啟用 DLQ 行為。預設情況下,導致錯誤的訊息會轉發到名為
error.<destination>.<group>的主題。DLQ 主題名稱可以通過設定dlqName屬性或定義DlqDestinationResolver類型的@Bean來組態。對於錯誤數量相對較少且重播整個原始主題可能太麻煩的情況,這為更常見的 Kafka 重播場景提供了替代選項。有關更多資訊,請參閱 死信主題處理 處理。從 2.0 版開始,發送到 DLQ 主題的訊息會使用以下標頭增強:x-original-topic、x-exception-message和x-exception-stacktrace作為byte[]。預設情況下,失敗的記錄會發送到 DLQ 主題中與原始記錄相同的分割區號。有關如何更改該行為的信息,請參閱 死信主題分割區選擇。當destinationIsPattern為true時不允許。預設值:
false。 - dlqPartitions
-
當
enableDlq為 true,並且未設定此屬性時,將建立與主要主題具有相同分割區數的死信主題。通常,死信記錄會發送到死信主題中與原始記錄相同的分割區。可以更改此行為;請參閱 死信主題分割區選擇。如果此屬性設定為1並且沒有DqlPartitionFunctionbean,則所有死信記錄都將寫入分割區0。如果此屬性大於1,則您必須提供DlqPartitionFunctionbean。請注意,實際分割區計數會受到 binder 的minPartitionCount屬性的影響。預設值:
none - configuration
-
包含通用 Kafka 消費者屬性的鍵/值對的對應。除了具有 Kafka 消費者屬性外,此處還可以傳遞其他組態屬性。例如,應用程式需要的一些屬性,例如
spring.cloud.stream.kafka.bindings.input.consumer.configuration.foo=bar。預設值:空對應。
- dlqName
-
接收錯誤訊息的 DLQ 主題的名稱。
預設值:null (如果未指定,導致錯誤的訊息將轉發到名為
error.<destination>.<group>的主題)。 - dlqProducerProperties
-
使用此屬性,可以設定 DLQ 特定的生產者屬性。所有通過 kafka 生產者屬性可用的屬性都可以通過此屬性設定。當在消費者上啟用原生解碼 (即,useNativeDecoding: true) 時,應用程式必須為 DLQ 提供相應的鍵/值序列化器。這必須以
dlqProducerProperties.configuration.key.serializer和dlqProducerProperties.configuration.value.serializer的形式提供。預設值:預設 Kafka 生產者屬性。
- standardHeaders
-
指示入站通道適配器填充哪些標準標頭。允許的值:
none、id、timestamp或both。如果使用原生反序列化,並且接收訊息的第一個組件需要id(例如,組態為使用 JDBC 訊息儲存區的聚合器),則很有用。預設值:
none - converterBeanName
-
實作
RecordMessageConverter的 bean 的名稱。在入站通道適配器中用於替換預設的MessagingMessageConverter。預設值:
null - idleEventInterval
-
指示最近沒有收到訊息的事件之間的時間間隔 (毫秒)。使用
ApplicationListener<ListenerContainerIdleEvent>接收這些事件。有關用法範例,請參閱 範例:暫停和恢復消費者。預設值:
30000 - destinationIsPattern
-
為 true 時,目的地被視為用於匹配 broker 的主題名稱的正則表達式
Pattern。為 true 時,不配置主題,並且不允許enableDlq,因為 binder 在配置階段不知道主題名稱。請注意,檢測與模式匹配的新主題所需的時間由消費者屬性metadata.max.age.ms控制,該屬性 (在撰寫本文時) 預設為 300,000 毫秒 (5 分鐘)。可以使用上面的configuration屬性來組態此屬性。預設值:
false - topic.properties
-
用於配置新主題的 Kafka 主題屬性的
Map,例如,spring.cloud.stream.kafka.bindings.input.consumer.topic.properties.message.format.version=0.9.0.0預設值:無。
- topic.replicas-assignment
-
複本分配的 Map<Integer, List<Integer>>,其中鍵是分割區,值是分配。配置新主題時使用。請參閱
kafka-clientsjar 中的NewTopicJavadocs。預設值:無。
- topic.replication-factor
-
配置主題時要使用的複寫因數。覆寫 binder 範圍的設定。如果存在
replicas-assignments,則忽略。預設值:無 (使用 binder 範圍的預設值 -1)。
- pollTimeout
-
用於可輪詢消費者的輪詢逾時。
預設值:5 秒。
- transactionManager
-
用於覆寫此綁定的 binder 交易管理器的
KafkaAwareTransactionManager的 Bean 名稱。如果您想使用ChainedKafkaTransactionManaager將另一個交易與 Kafka 交易同步,則通常需要此選項。為了實現記錄的精確一次消費和生產,消費者和生產者綁定都必須使用相同的交易管理器進行組態。預設值:無。
- txCommitRecovered
-
當使用交易式 binder 時,預設情況下,已恢復記錄的偏移量 (例如,當重試耗盡並且記錄已發送到死信主題時) 將通過新交易提交。將此屬性設定為
false會抑制提交已恢復記錄的偏移量。預設值:true。
1.3.3. 重設偏移量
當應用程式啟動時,每個已分配分割區中的初始位置取決於兩個屬性 startOffset 和 resetOffsets。如果 resetOffsets 為 false,則適用正常的 Kafka 消費者 auto.offset.reset 語義。即,如果綁定的消費者群組的分割區沒有已提交的偏移量,則位置為 earliest 或 latest。預設情況下,具有明確 group 的綁定使用 earliest,而匿名綁定 (沒有 group) 使用 latest。可以通過設定 startOffset 綁定屬性來覆寫這些預設值。第一次使用特定 group 啟動綁定時,將不會有已提交的偏移量。沒有已提交偏移量的另一種情況是偏移量已過期。對於現代 broker (自 2.1 起) 和預設 broker 屬性,偏移量在最後一個成員離開群組後 7 天過期。有關更多資訊,請參閱 offsets.retention.minutes broker 屬性。
當 resetOffsets 為 true 時,binder 應用與 broker 上沒有已提交偏移量時類似的語義,就好像此綁定從未從主題消費過一樣;即,任何當前已提交的偏移量都將被忽略。
以下是可能使用此功能的兩種用例。
-
從包含鍵/值對的壓縮主題消費。將
resetOffsets設定為true,將startOffset設定為earliest;綁定將對所有新分配的分割區執行seekToBeginning。 -
從包含事件的主題消費,您只對此綁定正在執行時發生的事件感興趣。將
resetOffsets設定為true,將startOffset設定為latest;綁定將對所有新分配的分割區執行seekToEnd。
| 如果在初始分配後發生重新平衡,則僅對在初始分配期間未分配的任何新分配的分割區執行搜尋。 |
有關主題偏移量的更多控制,請參閱 使用 KafkaRebalanceListener;當提供監聽器時,不應將 resetOffsets 設定為 true,否則會導致錯誤。>>>>>>> 7bc90c10… GH-1084: Add txCommitRecovered Property
1.3.4. 消費批次
從 3.0 版開始,當 spring.cloud.stream.binding.<name>.consumer.batch-mode 設定為 true 時,通過輪詢 Kafka Consumer 接收的所有記錄將作為 List<?> 呈現給監聽器方法。否則,將一次調用一個記錄的方法。批次的大小由 Kafka 消費者屬性 max.poll.records、fetch.min.bytes、fetch.max.wait.ms 控制;有關更多資訊,請參閱 Kafka 文件。
請記住,批次模式不支援 @StreamListener - 它僅適用於較新的函數式程式設計模型。
在使用批次模式時,binder 內不支援重試,因此 maxAttempts 將被覆寫為 1。您可以組態 SeekToCurrentBatchErrorHandler (使用 ListenerContainerCustomizer) 以實現與 binder 中重試類似的功能。您還可以使用手動 AckMode 並調用 Ackowledgment.nack(index, sleep) 來提交部分批次的偏移量,並重新傳遞剩餘記錄。有關這些技術的更多資訊,請參閱 Spring for Apache Kafka 文件。 |
1.3.5. Kafka 生產者屬性
為了避免重複,Spring Cloud Stream 支援設定所有通道的值,格式為 spring.cloud.stream.kafka.default.producer.<property>=<value>。 |
以下屬性僅適用於 Kafka 生產者,並且必須以 spring.cloud.stream.kafka.bindings.<channelName>.producer. 為前綴。
- admin.configuration
-
自 2.1.1 版起,此屬性已被棄用,改用
topic.properties,並且對它的支援將在未來版本中移除。 - admin.replicas-assignment
-
自 2.1.1 版起,此屬性已被棄用,改用
topic.replicas-assignment,並且對它的支援將在未來版本中移除。 - admin.replication-factor
-
自 2.1.1 版起,此屬性已被棄用,改用
topic.replication-factor,並且對它的支援將在未來版本中移除。 - bufferSize
-
Kafka 生產者在發送之前嘗試批次處理的資料量的上限 (以位元組為單位)。
預設值:
16384。 - sync
-
生產者是否同步。
預設值:
false。 - sendTimeoutExpression
-
針對傳出訊息評估的 SpEL 表達式,用於評估啟用同步發佈時等待確認的時間,例如,
headers['mySendTimeout']。逾時值以毫秒為單位。在 3.0 之前的版本中,除非使用原生編碼,否則無法使用有效負載,因為在評估此表達式時,有效負載已採用byte[]的形式。現在,表達式在轉換有效負載之前評估。預設值:
none。 - batchTimeout
-
生產者等待多長時間以允許更多訊息在同一批次中累積,然後再發送訊息。(通常,生產者根本不等待,而只是發送在上一次發送正在進行時累積的所有訊息。) 非零值可能會提高吞吐量,但會犧牲延遲。
預設值:
0。 - messageKeyExpression
-
針對傳出訊息評估的 SpEL 表達式,用於填充產生的 Kafka 訊息的鍵,例如,
headers['myKey']。在 3.0 之前的版本中,除非使用原生編碼,否則無法使用有效負載,因為在評估此表達式時,有效負載已採用byte[]的形式。現在,表達式在轉換有效負載之前評估。在常規處理器 (Function<String, String>或Function<Message<?>, Message<?>) 的情況下,如果產生的鍵需要與來自主題的輸入鍵相同,則可以將此屬性設定如下。spring.cloud.stream.kafka.bindings.<output-binding-name>.producer.messageKeyExpression: headers['kafka_receivedMessageKey']對於反應式函數,需要記住一個重要的注意事項。在這種情況下,由應用程式手動將標頭從輸入訊息複製到輸出訊息。您可以設定標頭,例如myKey並使用headers['myKey'](如上建議),或者為了方便起見,只需設定KafkaHeaders.MESSAGE_KEY標頭,您根本不需要設定此屬性。預設值:
none。 - headerPatterns
-
以逗號分隔的簡單模式列表,用於匹配要映射到
ProducerRecord中的 KafkaHeaders的 Spring 訊息標頭。模式可以以萬用字元 (星號) 開頭或結尾。模式可以通過以!為前綴來否定。匹配在第一次匹配 (肯定或否定) 後停止。例如,!ask,as*將通過ash,但不通過ask。id和timestamp永遠不會映射。預設值:
*(所有標頭 - 除了id和timestamp) - configuration
-
包含通用 Kafka 生產者屬性的鍵/值對的對應。
預設值:空對應。
- topic.properties
-
用於配置新主題的 Kafka 主題屬性的
Map,例如,spring.cloud.stream.kafka.bindings.output.producer.topic.properties.message.format.version=0.9.0.0 - topic.replicas-assignment
-
複本分配的 Map<Integer, List<Integer>>,其中鍵是分割區,值是分配。配置新主題時使用。請參閱
kafka-clientsjar 中的NewTopicJavadocs。預設值:無。
- topic.replication-factor
-
配置主題時要使用的複寫因數。覆寫 binder 範圍的設定。如果存在
replicas-assignments,則忽略。預設值:無 (使用 binder 範圍的預設值 -1)。
- useTopicHeader
-
設定為
true以使用輸出訊息中KafkaHeaders.TOPIC訊息標頭的值覆寫預設綁定目的地 (主題名稱)。如果標頭不存在,則使用預設綁定目的地。預設值:false。 - recordMetadataChannel
-
MessageChannel的 bean 名稱,成功發送結果應發送到該通道;bean 必須存在於應用程式上下文中。發送到通道的訊息是已發送的訊息 (如果有的話,在轉換之後),並帶有一個額外的標頭KafkaHeaders.RECORD_METADATA。標頭包含 Kafka 客戶端提供的RecordMetadata物件;它包括記錄寫入主題的分割區和偏移量。
ResultMetadata meta = sendResultMsg.getHeaders().get(KafkaHeaders.RECORD_METADATA, RecordMetadata.class)
失敗的發送會轉到生產者錯誤通道 (如果已組態);請參閱 錯誤通道。預設值:null
+
Kafka binder 使用生產者的 partitionCount 設定作為提示,以建立具有給定分割區計數的主題 (與 minPartitionCount 結合使用,兩者中的最大值是使用的值)。在為 binder 組態 minPartitionCount 和為應用程式組態 partitionCount 時要謹慎,因為會使用較大的值。如果主題已存在,分割區計數較小,並且 autoAddPartitions 已禁用 (預設值),則 binder 無法啟動。如果主題已存在,分割區計數較小,並且 autoAddPartitions 已啟用,則會添加新的分割區。如果主題已存在,分割區數大於 (minPartitionCount 或 partitionCount) 的最大值,則使用現有的分割區計數。 |
- compression
-
設定
compression.type生產者屬性。支援的值為none、gzip、snappy和lz4。如果您將kafka-clientsjar 覆寫為 2.1.0 (或更高版本),如 Spring for Apache Kafka 文件 中所述,並且希望使用zstd壓縮,請使用spring.cloud.stream.kafka.bindings.<binding-name>.producer.configuration.compression.type=zstd。預設值:
none。 - closeTimeout
-
關閉生產者時等待的逾時時間 (秒)。
預設值:
30
1.3.6. 用法範例
在本節中,我們展示了在特定場景中使用上述屬性的方法。
範例:設定 autoCommitOffset 為 false 並依賴手動確認
此範例說明瞭如何在消費者應用程式中手動確認偏移量。
此範例要求將 spring.cloud.stream.kafka.bindings.input.consumer.autoCommitOffset 設定為 false。為您的範例使用相應的輸入通道名稱。
@SpringBootApplication
@EnableBinding(Sink.class)
public class ManuallyAcknowdledgingConsumer {
public static void main(String[] args) {
SpringApplication.run(ManuallyAcknowdledgingConsumer.class, args);
}
@StreamListener(Sink.INPUT)
public void process(Message<?> message) {
Acknowledgment acknowledgment = message.getHeaders().get(KafkaHeaders.ACKNOWLEDGMENT, Acknowledgment.class);
if (acknowledgment != null) {
System.out.println("Acknowledgment provided");
acknowledgment.acknowledge();
}
}
}範例:安全性組態
Apache Kafka 0.9 支援客戶端和 broker 之間的安全連線。要利用此功能,請遵循 Apache Kafka 文件 以及 Confluent 文件中的 Kafka 0.9 安全指南 中的準則。使用 spring.cloud.stream.kafka.binder.configuration 選項為 binder 建立的所有客戶端設定安全性屬性。
例如,要將 security.protocol 設定為 SASL_SSL,請設定以下屬性
spring.cloud.stream.kafka.binder.configuration.security.protocol=SASL_SSL所有其他安全性屬性都可以以類似的方式設定。
使用 Kerberos 時,請按照 參考文件 中的說明建立和引用 JAAS 組態。
Spring Cloud Stream 支援通過使用 JAAS 組態檔案和 Spring Boot 屬性將 JAAS 組態資訊傳遞到應用程式。
使用 JAAS 組態檔案
可以使用系統屬性為 Spring Cloud Stream 應用程式設定 JAAS 和 (可選) krb5 檔案位置。以下範例顯示瞭如何通過使用 JAAS 組態檔案啟動具有 SASL 和 Kerberos 的 Spring Cloud Stream 應用程式
java -Djava.security.auth.login.config=/path.to/kafka_client_jaas.conf -jar log.jar \
--spring.cloud.stream.kafka.binder.brokers=secure.server:9092 \
--spring.cloud.stream.bindings.input.destination=stream.ticktock \
--spring.cloud.stream.kafka.binder.configuration.security.protocol=SASL_PLAINTEXT使用 Spring Boot 屬性
作為 JAAS 組態檔案的替代方案,Spring Cloud Stream 提供了一種通過使用 Spring Boot 屬性為 Spring Cloud Stream 應用程式設定 JAAS 組態的機制。
以下屬性可用於組態 Kafka 客戶端的登入上下文
- spring.cloud.stream.kafka.binder.jaas.loginModule
-
登入模組名稱。在正常情況下不需要設定。
預設值:
com.sun.security.auth.module.Krb5LoginModule。 - spring.cloud.stream.kafka.binder.jaas.controlFlag
-
登入模組的控制標誌。
預設值:
required。 - spring.cloud.stream.kafka.binder.jaas.options
-
包含登入模組選項的鍵/值對的對應。
預設值:空對應。
以下範例顯示瞭如何通過使用 Spring Boot 組態屬性啟動具有 SASL 和 Kerberos 的 Spring Cloud Stream 應用程式
java --spring.cloud.stream.kafka.binder.brokers=secure.server:9092 \
--spring.cloud.stream.bindings.input.destination=stream.ticktock \
--spring.cloud.stream.kafka.binder.autoCreateTopics=false \
--spring.cloud.stream.kafka.binder.configuration.security.protocol=SASL_PLAINTEXT \
--spring.cloud.stream.kafka.binder.jaas.options.useKeyTab=true \
--spring.cloud.stream.kafka.binder.jaas.options.storeKey=true \
--spring.cloud.stream.kafka.binder.jaas.options.keyTab=/etc/security/keytabs/kafka_client.keytab \
--spring.cloud.stream.kafka.binder.jaas.options.principal=kafka-client-1@EXAMPLE.COM前面的範例表示以下 JAAS 檔案的等效項
KafkaClient {
com.sun.security.auth.module.Krb5LoginModule required
useKeyTab=true
storeKey=true
keyTab="/etc/security/keytabs/kafka_client.keytab"
principal="[email protected]";
};如果所需的主題已存在於 broker 上或將由管理員建立,則可以關閉自動建立,並且只需要發送客戶端 JAAS 屬性。
不要在同一應用程式中混合使用 JAAS 組態檔案和 Spring Boot 屬性。如果 -Djava.security.auth.login.config 系統屬性已存在,則 Spring Cloud Stream 將忽略 Spring Boot 屬性。 |
使用 Kerberos 時,請小心使用 autoCreateTopics 和 autoAddPartitions。通常,應用程式可能會使用在 Kafka 和 Zookeeper 中不具管理權限的主體 (principals)。因此,依賴 Spring Cloud Stream 建立/修改主題可能會失敗。在安全環境中,我們強烈建議使用 Kafka 工具以管理方式建立主題和管理 ACL。 |
範例:暫停和恢復消費者
如果您希望暫停消費,但不想引起分割區重新平衡,您可以暫停和恢復消費者。這可以透過將 Consumer 作為參數添加到您的 @StreamListener 來實現。要恢復,您需要一個用於 ListenerContainerIdleEvent 實例的 ApplicationListener。事件發布的頻率由 idleEventInterval 屬性控制。由於消費者不是執行緒安全的,您必須在調用執行緒上調用這些方法。
以下簡單的應用程式展示了如何暫停和恢復
@SpringBootApplication
@EnableBinding(Sink.class)
public class Application {
public static void main(String[] args) {
SpringApplication.run(Application.class, args);
}
@StreamListener(Sink.INPUT)
public void in(String in, @Header(KafkaHeaders.CONSUMER) Consumer<?, ?> consumer) {
System.out.println(in);
consumer.pause(Collections.singleton(new TopicPartition("myTopic", 0)));
}
@Bean
public ApplicationListener<ListenerContainerIdleEvent> idleListener() {
return event -> {
System.out.println(event);
if (event.getConsumer().paused().size() > 0) {
event.getConsumer().resume(event.getConsumer().paused());
}
};
}
}1.4. 交易式 Binder
透過將 spring.cloud.stream.kafka.binder.transaction.transactionIdPrefix 設定為非空值(例如 tx-)來啟用交易。在處理器應用程式中使用時,消費者會啟動交易;在消費者執行緒上傳送的任何記錄都會參與同一個交易。當監聽器正常退出時,監聽器容器會將偏移量傳送至交易並提交它。通用生產者工廠用於所有使用 spring.cloud.stream.kafka.binder.transaction.producer.* 屬性配置的生產者綁定;個別綁定 Kafka 生產者屬性會被忽略。
正常的綁定器重試(和死信佇列)在交易中不受支援,因為重試將在原始交易中運行,原始交易可能會回滾,並且任何發布的記錄也將被回滾。當啟用重試時(通用屬性 maxAttempts 大於零),重試屬性會用於配置 DefaultAfterRollbackProcessor 以在容器層級啟用重試。同樣地,此功能不是在交易中發布死信記錄,而是移至監聽器容器,再次透過在主要交易回滾後運行的 DefaultAfterRollbackProcessor。 |
如果您希望在來源應用程式或來自某些任意執行緒的生產者專用交易(例如 @Scheduled 方法)中使用交易,您必須取得對交易生產者工廠的引用,並使用它定義 KafkaTransactionManager bean。
@Bean
public PlatformTransactionManager transactionManager(BinderFactory binders) {
ProducerFactory<byte[], byte[]> pf = ((KafkaMessageChannelBinder) binders.getBinder(null,
MessageChannel.class)).getTransactionalProducerFactory();
return new KafkaTransactionManager<>(pf);
}請注意,我們使用 BinderFactory 取得對綁定器的引用;當僅配置一個綁定器時,在第一個引數中使用 null。如果配置了多個綁定器,請使用綁定器名稱來取得引用。一旦我們有了對綁定器的引用,我們就可以取得對 ProducerFactory 的引用並建立交易管理器。
然後,您將使用正常的 Spring 交易支援,例如 TransactionTemplate 或 @Transactional,例如
public static class Sender {
@Transactional
public void doInTransaction(MessageChannel output, List<String> stuffToSend) {
stuffToSend.forEach(stuff -> output.send(new GenericMessage<>(stuff)));
}
}如果您希望將僅生產者交易與來自其他交易管理器的交易同步,請使用 ChainedTransactionManager。
1.5. 錯誤通道
從 1.3 版開始,綁定器會無條件地將例外狀況傳送到每個消費者目的地的一個錯誤通道,並且還可以配置為將非同步生產者傳送失敗傳送到錯誤通道。有關更多資訊,請參閱 關於錯誤處理的此章節。
傳送失敗的 ErrorMessage 的有效負載是具有以下屬性的 KafkaSendFailureException
-
failedMessage:未能傳送的 Spring MessagingMessage<?>。 -
record:從failedMessage建立的原始ProducerRecord
沒有生產者例外狀況的自動處理(例如傳送到 死信佇列)。您可以使用自己的 Spring Integration 流程來消費這些例外狀況。
1.6. Kafka 指標
Kafka 綁定器模組公開以下指標
spring.cloud.stream.binder.kafka.offset:此指標指示給定消費者群組尚未從給定綁定器的主題消費多少訊息。提供的指標基於 Micrometer 程式庫。如果 Micrometer 在類別路徑上,並且應用程式未提供其他此類 bean,則綁定器會建立 KafkaBinderMetrics bean。該指標包含消費者群組資訊、主題以及已提交偏移量與主題上最新偏移量之間的實際延遲。此指標對於向 PaaS 平台提供自動縮放回饋特別有用。
您可以透過在應用程式中提供以下元件,將 KafkaBinderMetrics 從建立必要基礎設施(例如消費者)和報告指標中排除。
@Component
class NoOpBindingMeters {
NoOpBindingMeters(MeterRegistry registry) {
registry.config().meterFilter(
MeterFilter.denyNameStartsWith(KafkaBinderMetrics.OFFSET_LAG_METRIC_NAME));
}
}有關如何有選擇地抑制計量器的更多詳細資訊,請參閱 此處。
1.7. Tombstone 記錄 (null 記錄值)
當使用壓縮主題時,具有 null 值(也稱為墓碑記錄)的記錄表示刪除索引鍵。要在 @StreamListener 方法中接收此類訊息,必須將參數標記為非必要,以接收 null 值引數。
@StreamListener(Sink.INPUT)
public void in(@Header(KafkaHeaders.RECEIVED_MESSAGE_KEY) byte[] key,
@Payload(required = false) Customer customer) {
// customer is null if a tombstone record
...
}1.8. 使用 KafkaRebalanceListener
應用程式可能希望在最初分配分割區時,將主題/分割區搜尋到任意偏移量,或對消費者執行其他操作。從 2.1 版開始,如果您在應用程式內容中提供單個 KafkaRebalanceListener bean,它將被連接到所有 Kafka 消費者綁定。
public interface KafkaBindingRebalanceListener {
/**
* Invoked by the container before any pending offsets are committed.
* @param bindingName the name of the binding.
* @param consumer the consumer.
* @param partitions the partitions.
*/
default void onPartitionsRevokedBeforeCommit(String bindingName, Consumer<?, ?> consumer,
Collection<TopicPartition> partitions) {
}
/**
* Invoked by the container after any pending offsets are committed.
* @param bindingName the name of the binding.
* @param consumer the consumer.
* @param partitions the partitions.
*/
default void onPartitionsRevokedAfterCommit(String bindingName, Consumer<?, ?> consumer, Collection<TopicPartition> partitions) {
}
/**
* Invoked when partitions are initially assigned or after a rebalance.
* Applications might only want to perform seek operations on an initial assignment.
* @param bindingName the name of the binding.
* @param consumer the consumer.
* @param partitions the partitions.
* @param initial true if this is the initial assignment.
*/
default void onPartitionsAssigned(String bindingName, Consumer<?, ?> consumer, Collection<TopicPartition> partitions,
boolean initial) {
}
}當您提供重新平衡監聽器時,您無法將 resetOffsets 消費者屬性設定為 true。
1.9. 自訂消費者和生產者組態
如果您想要對用於在 Kafka 中建立 ConsumerFactory 和 ProducerFactory 的消費者和生產者配置進行進階自訂,您可以實作以下自訂器。
-
ConsusumerConfigCustomizer
-
ProducerConfigCustomizer
這兩個介面都提供了一種配置用於消費者和生產者屬性的配置映射的方法。例如,如果您想存取在應用程式層級定義的 bean,您可以將其注入到 configure 方法的實作中。當綁定器發現這些自訂器作為 bean 可用時,它將在建立消費者和生產者工廠之前立即調用 configure 方法。
1.10. 自訂 AdminClient 組態
與上面的消費者和生產者配置自訂一樣,應用程式也可以透過提供 AdminClientConfigCustomizer 來客製化管理用戶端的配置。AdminClientConfigCustomizer 的 configure 方法提供對管理用戶端屬性的存取權,您可以使用這些屬性來定義進一步的自訂。綁定器的 Kafka 主題佈建器為透過此自訂器給定的屬性提供最高優先權。以下是提供此自訂器 bean 的範例。
@Bean
public AdminClientConfigCustomizer adminClientConfigCustomizer() {
return props -> {
props.put(CommonClientConfigs.SECURITY_PROTOCOL_CONFIG, "SASL_SSL");
};
}1.11. 死信主題處理
1.11.1. 死信主題分割區選擇
預設情況下,記錄會使用與原始記錄相同的分割區發布到死信主題。這表示死信主題必須至少具有與原始記錄一樣多的分割區。
要變更此行為,請將 DlqPartitionFunction 實作作為 @Bean 新增至應用程式內容。只能存在一個此類 bean。該函數提供消費者群組、失敗的 ConsumerRecord 和例外狀況。例如,如果您始終想要路由到分割區 0,您可以使用
@Bean
public DlqPartitionFunction partitionFunction() {
return (group, record, ex) -> 0;
}如果您將消費者綁定的 dlqPartitions 屬性設定為 1(且綁定器的 minPartitionCount 等於 1),則無需提供 DlqPartitionFunction;框架將始終使用分割區 0。如果您將消費者綁定的 dlqPartitions 屬性設定為大於 1 的值(或綁定器的 minPartitionCount 大於 1),即使分割區計數與原始主題的計數相同,您也**必須**提供 DlqPartitionFunction bean。 |
也可以為 DLQ 主題定義自訂名稱。為此,請建立 DlqDestinationResolver 的實作作為應用程式內容的 @Bean。當綁定器偵測到此類 bean 時,它會優先使用它,否則它將使用 dlqName 屬性。如果兩者都找不到,則預設為 error.<destination>.<group>。以下是作為 @Bean 的 DlqDestinationResolver 範例。
@Bean
public DlqDestinationResolver dlqDestinationResolver() {
return (rec, ex) -> {
if (rec.topic().equals("word1")) {
return "topic1-dlq";
}
else {
return "topic2-dlq";
}
};
}在為 DlqDestinationResolver 提供實作時,需要記住的一件重要事情是,綁定器中的佈建器不會自動為應用程式建立主題。這是因為綁定器無法推斷實作可能傳送到的所有 DLQ 主題的名稱。因此,如果您使用此策略提供 DLQ 名稱,則應用程式有責任確保事先建立這些主題。
1.11.2. 處理死信主題中的記錄
由於框架無法預料使用者希望如何處置死信訊息,因此它不提供任何標準機制來處理它們。如果死信的原因是暫時性的,您可能希望將訊息路由回原始主題。但是,如果問題是永久性的問題,則可能會導致無限迴圈。本主題中的範例 Spring Boot 應用程式示範了如何將這些訊息路由回原始主題,但在三次嘗試後,它會將它們移動到「停車場」主題。該應用程式是另一個 spring-cloud-stream 應用程式,它從死信主題讀取。當 5 秒內未收到訊息時,它會終止。
範例假設原始目的地是 so8400out,消費者群組是 so8400。
有幾種策略需要考慮
-
考慮僅在主要應用程式未運行時才運行重新路由。否則,暫時性錯誤的重試會很快用完。
-
或者,使用兩階段方法:使用此應用程式路由到第三個主題,另一個應用程式從那裡路由回主要主題。
以下程式碼清單顯示了範例應用程式
spring.cloud.stream.bindings.input.group=so8400replay
spring.cloud.stream.bindings.input.destination=error.so8400out.so8400
spring.cloud.stream.bindings.output.destination=so8400out
spring.cloud.stream.bindings.parkingLot.destination=so8400in.parkingLot
spring.cloud.stream.kafka.binder.configuration.auto.offset.reset=earliest
spring.cloud.stream.kafka.binder.headers=x-retries@SpringBootApplication
@EnableBinding(TwoOutputProcessor.class)
public class ReRouteDlqKApplication implements CommandLineRunner {
private static final String X_RETRIES_HEADER = "x-retries";
public static void main(String[] args) {
SpringApplication.run(ReRouteDlqKApplication.class, args).close();
}
private final AtomicInteger processed = new AtomicInteger();
@Autowired
private MessageChannel parkingLot;
@StreamListener(Processor.INPUT)
@SendTo(Processor.OUTPUT)
public Message<?> reRoute(Message<?> failed) {
processed.incrementAndGet();
Integer retries = failed.getHeaders().get(X_RETRIES_HEADER, Integer.class);
if (retries == null) {
System.out.println("First retry for " + failed);
return MessageBuilder.fromMessage(failed)
.setHeader(X_RETRIES_HEADER, new Integer(1))
.setHeader(BinderHeaders.PARTITION_OVERRIDE,
failed.getHeaders().get(KafkaHeaders.RECEIVED_PARTITION_ID))
.build();
}
else if (retries.intValue() < 3) {
System.out.println("Another retry for " + failed);
return MessageBuilder.fromMessage(failed)
.setHeader(X_RETRIES_HEADER, new Integer(retries.intValue() + 1))
.setHeader(BinderHeaders.PARTITION_OVERRIDE,
failed.getHeaders().get(KafkaHeaders.RECEIVED_PARTITION_ID))
.build();
}
else {
System.out.println("Retries exhausted for " + failed);
parkingLot.send(MessageBuilder.fromMessage(failed)
.setHeader(BinderHeaders.PARTITION_OVERRIDE,
failed.getHeaders().get(KafkaHeaders.RECEIVED_PARTITION_ID))
.build());
}
return null;
}
@Override
public void run(String... args) throws Exception {
while (true) {
int count = this.processed.get();
Thread.sleep(5000);
if (count == this.processed.get()) {
System.out.println("Idle, terminating");
return;
}
}
}
public interface TwoOutputProcessor extends Processor {
@Output("parkingLot")
MessageChannel parkingLot();
}
}1.12. 使用 Kafka Binder 進行分割
Apache Kafka 原生支援主題分割區。
有時,將資料傳送到特定分割區是有利的,例如,當您想要嚴格排序訊息處理時(特定客戶的所有訊息都應進入同一個分割區)。
以下範例顯示如何配置生產者和消費者端
@SpringBootApplication
@EnableBinding(Source.class)
public class KafkaPartitionProducerApplication {
private static final Random RANDOM = new Random(System.currentTimeMillis());
private static final String[] data = new String[] {
"foo1", "bar1", "qux1",
"foo2", "bar2", "qux2",
"foo3", "bar3", "qux3",
"foo4", "bar4", "qux4",
};
public static void main(String[] args) {
new SpringApplicationBuilder(KafkaPartitionProducerApplication.class)
.web(false)
.run(args);
}
@InboundChannelAdapter(channel = Source.OUTPUT, poller = @Poller(fixedRate = "5000"))
public Message<?> generate() {
String value = data[RANDOM.nextInt(data.length)];
System.out.println("Sending: " + value);
return MessageBuilder.withPayload(value)
.setHeader("partitionKey", value)
.build();
}
}spring:
cloud:
stream:
bindings:
output:
destination: partitioned.topic
producer:
partition-key-expression: headers['partitionKey']
partition-count: 12必須佈建主題以具有足夠的分割區,以實現所有消費者群組所需的並行性。上述配置最多支援 12 個消費者實例(如果其 concurrency 為 2,則為 6 個,如果其並行性為 3,則為 4 個,依此類推)。通常最好「過度佈建」分割區,以便未來可以增加消費者或並行性。 |
先前的配置使用預設分割區(key.hashCode() % partitionCount)。根據索引鍵值,這可能會或可能不會提供適當平衡的演算法。您可以使用 partitionSelectorExpression 或 partitionSelectorClass 屬性覆寫此預設值。 |
由於分割區由 Kafka 原生處理,因此消費者端不需要特殊配置。Kafka 在實例之間分配分割區。
以下 Spring Boot 應用程式監聽 Kafka 串流並(向主控台)列印每個訊息所進入的分割區 ID
@SpringBootApplication
@EnableBinding(Sink.class)
public class KafkaPartitionConsumerApplication {
public static void main(String[] args) {
new SpringApplicationBuilder(KafkaPartitionConsumerApplication.class)
.web(false)
.run(args);
}
@StreamListener(Sink.INPUT)
public void listen(@Payload String in, @Header(KafkaHeaders.RECEIVED_PARTITION_ID) int partition) {
System.out.println(in + " received from partition " + partition);
}
}spring:
cloud:
stream:
bindings:
input:
destination: partitioned.topic
group: myGroup您可以根據需要新增實例。Kafka 會重新平衡分割區分配。如果實例計數(或 instance count * concurrency)超過分割區數量,則某些消費者會處於閒置狀態。
2. Kafka Streams Binder
2.1. 用法
為了使用 Kafka Streams 綁定器,您只需將其新增到您的 Spring Cloud Stream 應用程式,使用以下 Maven 座標
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-stream-binder-kafka-streams</artifactId>
</dependency>啟動 Kafka Streams 綁定器新專案的快速方法是使用 Spring Initializr,然後選擇「Cloud Streams」和「Spring for Kafka Streams」,如下所示

2.2. 概述
Spring Cloud Stream 包含一個專門為 Apache Kafka Streams 綁定設計的綁定器實作。透過這種原生整合,Spring Cloud Stream「處理器」應用程式可以直接在核心業務邏輯中使用 Apache Kafka Streams API。
Kafka Streams 綁定器實作建立在 Spring for Apache Kafka 專案提供的基礎之上。
Kafka Streams 綁定器為 Kafka Streams 中的三種主要類型提供綁定功能 - KStream、KTable 和 GlobalKTable。
Kafka Streams 應用程式通常遵循一種模型,其中記錄從輸入主題讀取,應用業務邏輯,然後將轉換後的記錄寫入輸出主題。或者,也可以定義沒有輸出目的地的處理器應用程式。
在以下章節中,我們將研究 Spring Cloud Stream 與 Kafka Streams 整合的詳細資訊。
2.3. 程式設計模型
當使用 Kafka Streams 綁定器提供的程式設計模型時,高階 Streams DSL 和高階與低階 Processor-API 的混合都可以用作選項。當混合使用高階和低階 API 時,通常是透過在 KStream 上調用 transform 或 process API 方法來實現。
2.3.1. 函數式風格
從 Spring Cloud Stream 3.0.0 開始,Kafka Streams 綁定器允許使用 Java 8 中提供的函數式程式設計風格來設計和開發應用程式。這表示應用程式可以簡潔地表示為 java.util.function.Function 或 java.util.function.Consumer 類型的 Lambda 運算式。
讓我們來看一個非常基本的範例。
@SpringBootApplication
public class SimpleConsumerApplication {
@Bean
public java.util.function.Consumer<KStream<Object, String>> process() {
return input ->
input.foreach((key, value) -> {
System.out.println("Key: " + key + " Value: " + value);
});
}
}雖然很簡單,但這是一個完整的獨立 Spring Boot 應用程式,它利用 Kafka Streams 進行串流處理。這是一個沒有輸出綁定且只有單個輸入綁定的消費者應用程式。該應用程式消費資料,並且僅將來自 KStream 索引鍵和值的資訊記錄在標準輸出上。該應用程式包含 SpringBootApplication 註解和一個標記為 Bean 的方法。bean 方法的類型為 java.util.function.Consumer,它使用 KStream 進行參數化。然後在實作中,我們傳回一個本質上是 Lambda 運算式的 Consumer 物件。在 Lambda 運算式內部,提供了用於處理資料的程式碼。
在此應用程式中,有一個類型為 KStream 的單個輸入綁定。綁定器使用名稱 process-in-0 為應用程式建立此綁定,即函數 bean 名稱後跟一個破折號字元 (-) 和字面值 in,後跟另一個破折號,然後是參數的序數位置。您可以使用此綁定名稱來設定其他屬性,例如目的地。例如,spring.cloud.stream.bindings.process-in-0.destination=my-topic。
| 如果未在綁定上設定目的地屬性,則會建立一個與綁定同名的主題(如果應用程式具有足夠的權限),或者預期該主題已可用。 |
一旦建置為 uber-jar(例如,kstream-consumer-app.jar),您可以像下面這樣運行上面的範例。
java -jar kstream-consumer-app.jar --spring.cloud.stream.bindings.process-in-0.destination=my-topic這是另一個範例,它是一個具有輸入和輸出綁定的完整處理器。這是經典的單字計數範例,其中應用程式從主題接收資料,然後在滾動時間視窗中計算每個單字的出現次數。
@SpringBootApplication
public class WordCountProcessorApplication {
@Bean
public Function<KStream<Object, String>, KStream<?, WordCount>> process() {
return input -> input
.flatMapValues(value -> Arrays.asList(value.toLowerCase().split("\\W+")))
.map((key, value) -> new KeyValue<>(value, value))
.groupByKey(Serialized.with(Serdes.String(), Serdes.String()))
.windowedBy(TimeWindows.of(5000))
.count(Materialized.as("word-counts-state-store"))
.toStream()
.map((key, value) -> new KeyValue<>(key.key(), new WordCount(key.key(), value,
new Date(key.window().start()), new Date(key.window().end()))));
}
public static void main(String[] args) {
SpringApplication.run(WordCountProcessorApplication.class, args);
}
}同樣,這是一個完整的 Spring Boot 應用程式。此處與第一個應用程式的不同之處在於,bean 方法的類型為 java.util.function.Function。Function 的第一個參數化類型用於輸入 KStream,第二個參數化類型用於輸出。在方法主體中,提供了一個類型為 Function 的 Lambda 運算式,並作為實作,給出了實際的業務邏輯。與先前討論的基於 Consumer 的應用程式類似,此處的輸入綁定預設命名為 process-in-0。對於輸出,綁定名稱也會自動設定為 process-out-0。
一旦建置為 uber-jar(例如,wordcount-processor.jar),您可以像下面這樣運行上面的範例。
java -jar wordcount-processor.jar --spring.cloud.stream.bindings.process-in-0.destination=words --spring.cloud.stream.bindings.process-out-0.destination=counts此應用程式將從 Kafka 主題 words 消費訊息,並且計算結果將發布到輸出主題 counts。
Spring Cloud Stream 將確保來自輸入和輸出主題的訊息會自動綁定為 KStream 物件。作為開發人員,您可以專注於程式碼的業務方面,即編寫處理器中所需的邏輯。設定 Kafka Streams 基礎架構所需的 Kafka Streams 特定配置由框架自動處理。
我們在上面看到的兩個範例都有單個 KStream 輸入綁定。在這兩種情況下,綁定都從單個主題接收記錄。如果您想將多個主題多工處理到單個 KStream 綁定中,您可以提供逗號分隔的 Kafka 主題作為以下目的地。
spring.cloud.stream.bindings.process-in-0.destination=topic-1,topic-2,topic-3
此外,如果您想將主題與規則運算式匹配,您也可以提供主題模式作為目的地。
spring.cloud.stream.bindings.process-in-0.destination=input.*
多個輸入綁定
許多非平凡的 Kafka Streams 應用程式通常透過多個綁定從多個主題消費資料。例如,一個主題作為 Kstream 消費,另一個主題作為 KTable 或 GlobalKTable 消費。應用程式可能希望以表格類型接收資料的原因有很多。考慮一個用例,其中基礎主題是透過資料庫的變更資料擷取 (CDC) 機制填充的,或者應用程式可能只關心下游處理的最新更新。如果應用程式指定需要將資料綁定為 KTable 或 GlobalKTable,則 Kafka Streams 綁定器將正確地將目的地綁定到 KTable 或 GlobalKTable,並使其可用於應用程式操作。我們將研究幾種不同的情境,說明如何在 Kafka Streams 綁定器中處理多個輸入綁定。
Kafka Streams 綁定器中的 BiFunction
這是一個範例,其中我們有兩個輸入和一個輸出。在這種情況下,應用程式可以利用 java.util.function.BiFunction。
@Bean
public BiFunction<KStream<String, Long>, KTable<String, String>, KStream<String, Long>> process() {
return (userClicksStream, userRegionsTable) -> (userClicksStream
.leftJoin(userRegionsTable, (clicks, region) -> new RegionWithClicks(region == null ?
"UNKNOWN" : region, clicks),
Joined.with(Serdes.String(), Serdes.Long(), null))
.map((user, regionWithClicks) -> new KeyValue<>(regionWithClicks.getRegion(),
regionWithClicks.getClicks()))
.groupByKey(Grouped.with(Serdes.String(), Serdes.Long()))
.reduce(Long::sum)
.toStream());
}同樣,基本主題與之前的範例相同,但這裡我們有兩個輸入。Java 的 BiFunction 支援用於將輸入綁定到所需的目的地。綁定器為輸入產生的預設綁定名稱分別為 process-in-0 和 process-in-1。預設輸出綁定為 process-out-0。在此範例中,BiFunction 的第一個參數綁定為第一個輸入的 KStream,第二個參數綁定為第二個輸入的 KTable。
Kafka Streams 綁定器中的 BiConsumer
如果有兩個輸入,但沒有輸出,在這種情況下,我們可以像下面這樣使用 java.util.function.BiConsumer。
@Bean
public BiConsumer<KStream<String, Long>, KTable<String, String>> process() {
return (userClicksStream, userRegionsTable) -> {}
}超出兩個輸入
如果您有兩個以上的輸入怎麼辦?在某些情況下,您需要兩個以上的輸入。在這種情況下,綁定器允許您鏈接部分函數。在函數式程式設計術語中,此技術通常稱為柯里化。透過作為 Java 8 一部分新增的函數式程式設計支援,Java 現在使您能夠編寫柯里化函數。Spring Cloud Stream Kafka Streams 綁定器可以利用此功能來啟用多個輸入綁定。
讓我們看一個範例。
@Bean
public Function<KStream<Long, Order>,
Function<GlobalKTable<Long, Customer>,
Function<GlobalKTable<Long, Product>, KStream<Long, EnrichedOrder>>>> enrichOrder() {
return orders -> (
customers -> (
products -> (
orders.join(customers,
(orderId, order) -> order.getCustomerId(),
(order, customer) -> new CustomerOrder(customer, order))
.join(products,
(orderId, customerOrder) -> customerOrder
.productId(),
(customerOrder, product) -> {
EnrichedOrder enrichedOrder = new EnrichedOrder();
enrichedOrder.setProduct(product);
enrichedOrder.setCustomer(customerOrder.customer);
enrichedOrder.setOrder(customerOrder.order);
return enrichedOrder;
})
)
)
);
}讓我們看看上面呈現的綁定模型的詳細資訊。在此模型中,我們在輸入端有 3 個部分應用的函數。讓我們將它們稱為 f(x)、f(y) 和 f(z)。如果我們在真數學函數的意義上展開這些函數,它將如下所示:f(x) → (fy) → f(z) → KStream<Long, EnrichedOrder>。x 變數代表 KStream<Long, Order>,y 變數代表 GlobalKTable<Long, Customer>,z 變數代表 GlobalKTable<Long, Product>。第一個函數 f(x) 具有應用程式的第一個輸入綁定 (KStream<Long, Order>),其輸出是函數 f(y)。函數 f(y) 具有應用程式的第二個輸入綁定 (GlobalKTable<Long, Customer>),其輸出是另一個函數 f(z)。函數 f(z) 的輸入是應用程式的第三個輸入 (GlobalKTable<Long, Product>),其輸出是 KStream<Long, EnrichedOrder>,它是應用程式的最終輸出綁定。來自三個部分函數(分別為 KStream、GlobalKTable、GlobalKTable)的輸入可在方法主體中供您使用,以實作業務邏輯作為 Lambda 運算式的一部分。
輸入綁定分別命名為 enrichOrder-in-0、enrichOrder-in-1 和 enrichOrder-in-2。輸出綁定命名為 enrichOrder-out-0。
使用柯里化函數,您可以實際上擁有任意數量的輸入。但是,請記住,任何超過少量輸入以及它們的部分應用函數(如上面的 Java 中所示)都可能導致程式碼難以閱讀。因此,如果您的 Kafka Streams 應用程式需要超過合理數量的輸入綁定,並且您想使用此函數式模型,那麼您可能需要重新思考您的設計並適當地分解應用程式。
多個輸出綁定
Kafka Streams 允許將輸出資料寫入多個主題。此功能在 Kafka Streams 中稱為分支。當使用多個輸出綁定時,您需要提供 KStream 陣列 (KStream[]) 作為輸出傳回類型。
這是一個範例
@Bean
public Function<KStream<Object, String>, KStream<?, WordCount>[]> process() {
Predicate<Object, WordCount> isEnglish = (k, v) -> v.word.equals("english");
Predicate<Object, WordCount> isFrench = (k, v) -> v.word.equals("french");
Predicate<Object, WordCount> isSpanish = (k, v) -> v.word.equals("spanish");
return input -> input
.flatMapValues(value -> Arrays.asList(value.toLowerCase().split("\\W+")))
.groupBy((key, value) -> value)
.windowedBy(TimeWindows.of(5000))
.count(Materialized.as("WordCounts-branch"))
.toStream()
.map((key, value) -> new KeyValue<>(null, new WordCount(key.key(), value,
new Date(key.window().start()), new Date(key.window().end()))))
.branch(isEnglish, isFrench, isSpanish);
}程式設計模型保持不變,但是輸出參數化類型是 KStream[]。預設輸出綁定名稱分別為 process-out-0、process-out-1、process-out-2。綁定器產生三個輸出綁定的原因是它偵測到傳回的 KStream 陣列的長度。
Kafka Streams 函數式程式設計風格摘要
總之,下表顯示了可以在函數式範例中使用的各種選項。
| 輸入數量 | 輸出數量 | 要使用的元件 |
|---|---|---|
1 |
0 |
0 |
2 |
0 |
1 |
1 |
2 |
1 |
2 |
2 |
2 |
>= 3 |
1 |
1.. |
-
在多個輸出的情況下,類型只是變成
KStream[]。
2.3.2. 命令式程式設計模型。
雖然上面概述的函數式程式設計模型是首選方法,但如果您願意,仍然可以使用基於經典 StreamListener 的方法。
以下是一些範例。
以下是使用 StreamListener 的單字計數範例的等效版本。
@SpringBootApplication
@EnableBinding(KafkaStreamsProcessor.class)
public class WordCountProcessorApplication {
@StreamListener("input")
@SendTo("output")
public KStream<?, WordCount> process(KStream<?, String> input) {
return input
.flatMapValues(value -> Arrays.asList(value.toLowerCase().split("\\W+")))
.groupBy((key, value) -> value)
.windowedBy(TimeWindows.of(5000))
.count(Materialized.as("WordCounts-multi"))
.toStream()
.map((key, value) -> new KeyValue<>(null, new WordCount(key.key(), value, new Date(key.window().start()), new Date(key.window().end()))));
}
public static void main(String[] args) {
SpringApplication.run(WordCountProcessorApplication.class, args);
}如您所見,這有點冗長,因為您需要提供 EnableBinding 和其他額外註解,例如 StreamListener 和 SendTo,才能使其成為完整的應用程式。EnableBinding 是您在其中指定包含綁定的綁定介面的位置。在這種情況下,我們正在使用庫存 KafkaStreamsProcessor 綁定介面,它具有以下合約。
public interface KafkaStreamsProcessor {
@Input("input")
KStream<?, ?> input();
@Output("output")
KStream<?, ?> output();
}綁定器將為輸入 KStream 和輸出 KStream 建立綁定,因為您正在使用包含這些宣告的綁定介面。
除了函數式風格中提供的程式設計模型中的明顯差異之外,此處需要提到的一件特別的事情是綁定名稱是您在綁定介面中指定的名稱。例如,在上面的應用程式中,由於我們正在使用 KafkaStreamsProcessor,因此綁定名稱為 input 和 output。綁定屬性需要使用這些名稱。例如 spring.cloud.stream.bindings.input.destination、spring.cloud.stream.bindings.output.destination 等。請記住,這與函數式風格有根本的不同,因為在函數式風格中,綁定器會為應用程式產生綁定名稱。這是因為應用程式在使用 EnableBinding 的函數式模型中不提供任何綁定介面。
這是另一個接收器的範例,其中我們有兩個輸入。
@EnableBinding(KStreamKTableBinding.class)
.....
.....
@StreamListener
public void process(@Input("inputStream") KStream<String, PlayEvent> playEvents,
@Input("inputTable") KTable<Long, Song> songTable) {
....
....
}
interface KStreamKTableBinding {
@Input("inputStream")
KStream<?, ?> inputStream();
@Input("inputTable")
KTable<?, ?> inputTable();
}以下是我們在上面看到的相同基於 BiFunction 的處理器的 StreamListener 等效版本。
@EnableBinding(KStreamKTableBinding.class)
....
....
@StreamListener
@SendTo("output")
public KStream<String, Long> process(@Input("input") KStream<String, Long> userClicksStream,
@Input("inputTable") KTable<String, String> userRegionsTable) {
....
....
}
interface KStreamKTableBinding extends KafkaStreamsProcessor {
@Input("inputX")
KTable<?, ?> inputTable();
}最後,這是具有三個輸入和柯里化函數的應用程式的 StreamListener 等效版本。
@EnableBinding(CustomGlobalKTableProcessor.class)
...
...
@StreamListener
@SendTo("output")
public KStream<Long, EnrichedOrder> process(
@Input("input-1") KStream<Long, Order> ordersStream,
@Input("input-2") GlobalKTable<Long, Customer> customers,
@Input("input-3") GlobalKTable<Long, Product> products) {
KStream<Long, CustomerOrder> customerOrdersStream = ordersStream.join(
customers, (orderId, order) -> order.getCustomerId(),
(order, customer) -> new CustomerOrder(customer, order));
return customerOrdersStream.join(products,
(orderId, customerOrder) -> customerOrder.productId(),
(customerOrder, product) -> {
EnrichedOrder enrichedOrder = new EnrichedOrder();
enrichedOrder.setProduct(product);
enrichedOrder.setCustomer(customerOrder.customer);
enrichedOrder.setOrder(customerOrder.order);
return enrichedOrder;
});
}
interface CustomGlobalKTableProcessor {
@Input("input-1")
KStream<?, ?> input1();
@Input("input-2")
GlobalKTable<?, ?> input2();
@Input("input-3")
GlobalKTable<?, ?> input3();
@Output("output")
KStream<?, ?> output();
}您可能會注意到,以上兩個範例甚至更冗長,因為除了提供 EnableBinding 之外,您還需要編寫自己的自訂綁定介面。使用函數式模型,您可以避免所有這些儀式性的細節。
在我們繼續研究 Kafka Streams 綁定器提供的一般程式設計模型之前,這是多個輸出綁定的 StreamListener 版本。
EnableBinding(KStreamProcessorWithBranches.class)
public static class WordCountProcessorApplication {
@Autowired
private TimeWindows timeWindows;
@StreamListener("input")
@SendTo({"output1","output2","output3"})
public KStream<?, WordCount>[] process(KStream<Object, String> input) {
Predicate<Object, WordCount> isEnglish = (k, v) -> v.word.equals("english");
Predicate<Object, WordCount> isFrench = (k, v) -> v.word.equals("french");
Predicate<Object, WordCount> isSpanish = (k, v) -> v.word.equals("spanish");
return input
.flatMapValues(value -> Arrays.asList(value.toLowerCase().split("\\W+")))
.groupBy((key, value) -> value)
.windowedBy(timeWindows)
.count(Materialized.as("WordCounts-1"))
.toStream()
.map((key, value) -> new KeyValue<>(null, new WordCount(key.key(), value, new Date(key.window().start()), new Date(key.window().end()))))
.branch(isEnglish, isFrench, isSpanish);
}
interface KStreamProcessorWithBranches {
@Input("input")
KStream<?, ?> input();
@Output("output1")
KStream<?, ?> output1();
@Output("output2")
KStream<?, ?> output2();
@Output("output3")
KStream<?, ?> output3();
}
}總之,我們回顧了使用 Kafka Streams 綁定器時的各種程式設計模型選擇。
綁定器為輸入端的 KStream、KTable 和 GlobalKTable 提供綁定功能。KTable 和 GlobalKTable 綁定僅在輸入端可用。綁定器支援 KStream 的輸入和輸出綁定。
Kafka Streams 綁定器的程式設計模型的結果是,綁定器為您提供了靈活性,可以選擇完全採用函數式程式設計模型,也可以使用基於 StreamListener 的命令式方法。
2.4. 程式設計模型的輔助功能
2.4.1. 單一應用程式內的多個 Kafka Streams 處理器
綁定器允許在單個 Spring Cloud Stream 應用程式中擁有多個 Kafka Streams 處理器。您可以擁有如下所示的應用程式。
@Bean
public java.util.function.Function<KStream<Object, String>, KStream<Object, String>> process() {
...
}
@Bean
public java.util.function.Consumer<KStream<Object, String>> anotherProcess() {
...
}
@Bean
public java.util.function.BiFunction<KStream<Object, String>, KTable<Integer, String>, KStream<Object, String>> yetAnotherProcess() {
...
}在這種情況下,綁定器將建立 3 個具有不同應用程式 ID 的獨立 Kafka Streams 物件(更多資訊如下)。但是,如果您的應用程式中有一個以上的處理器,則必須告訴 Spring Cloud Stream 哪些函數需要啟動。以下是如何啟動函數。
spring.cloud.stream.function.definition: process;anotherProcess;yetAnotherProcess
如果您希望某些函數不要立即啟動,您可以從此列表中刪除它們。
當您在同一應用程式中具有單個 Kafka Streams 處理器和其他類型的 Function bean 時,情況也是如此,這些 bean 是透過不同的綁定器處理的(例如,基於常規 Kafka 訊息通道綁定器的函數 bean)
2.4.2. Kafka Streams 應用程式 ID
應用程式 ID 是您需要為 Kafka Streams 應用程式提供的強制屬性。Spring Cloud Stream Kafka Streams 綁定器允許您以多種方式配置此應用程式 ID。
如果您的應用程式中只有一個單個處理器或 StreamListener,那麼您可以使用以下屬性在綁定器層級設定此 ID
spring.cloud.stream.kafka.streams.binder.applicationId.
為方便起見,如果您只有一個處理器,您也可以使用 spring.application.name 作為委派應用程式 ID 的屬性。
如果您的應用程式中有多個 Kafka Streams 處理器,則需要為每個處理器設定應用程式 ID。在函數式模型的情況下,您可以將其作為屬性附加到每個函數。
例如,假設您有以下函數。
@Bean
public java.util.function.Consumer<KStream<Object, String>> process() {
...
}和
@Bean
public java.util.function.Consumer<KStream<Object, String>> anotherProcess() {
...
}然後,您可以使用以下綁定器層級屬性為每個函數設定應用程式 ID。
spring.cloud.stream.kafka.streams.binder.functions.process.applicationId
和
spring.cloud.stream.kafka.streams.binder.functions.anotherProcess.applicationId
在 StreamListener 的情況下,您需要在處理器上的第一個輸入綁定上設定此 ID。
例如,假設您有以下兩個基於 StreamListener 的處理器。
@StreamListener
@SendTo("output")
public KStream<String, String> process(@Input("input") <KStream<Object, String>> input) {
...
}
@StreamListener
@SendTo("anotherOutput")
public KStream<String, String> anotherProcess(@Input("anotherInput") <KStream<Object, String>> input) {
...
}然後,您必須使用以下綁定屬性為此設定應用程式 ID。
spring.cloud.stream.kafka.streams.bindings.input.consumer.applicationId
和
spring.cloud.stream.kafka.streams.bindings.anotherInput.consumer.applicationId
對於基於函數的模型,這種在綁定層級設定應用程式 ID 的方法也適用。但是,如果您使用函數式模型,則在綁定器層級為每個函數設定 ID 要容易得多。
對於生產部署,強烈建議透過配置明確指定應用程式 ID。如果您自動擴展應用程式,這種做法尤其重要,在這種情況下,您需要確保使用相同的應用程式 ID 部署每個實例。
如果應用程式未提供應用程式 ID,則在這種情況下,綁定器將為您自動產生靜態應用程式 ID。這在開發情境中很方便,因為它避免了明確提供應用程式 ID 的需要。以此方式產生的應用程式 ID 在應用程式重新啟動時將保持靜態。在函數式模型的情況下,產生的應用程式 ID 將是函數 bean 名稱後跟字面值 applicationID,例如,如果 process 是函數 bean 名稱,則為 process-applicationID。在 StreamListener 的情況下,產生的應用程式 ID 將使用包含類別名稱後跟方法名稱後跟字面值 applicationId,而不是使用函數 bean 名稱。
設定應用程式 ID 摘要
-
預設情況下,綁定器將為每個函數或
StreamListener方法自動產生應用程式 ID。 -
如果您只有一個處理器,則可以使用
spring.kafka.streams.applicationId、spring.application.name或spring.cloud.stream.kafka.streams.binder.applicationId。 -
如果您有多個處理器,則可以使用屬性為每個函數設定應用程式 ID -
spring.cloud.stream.kafka.streams.binder.functions.<function-name>.applicationId。在StreamListener的情況下,可以使用spring.cloud.stream.kafka.streams.bindings.input.applicationId來完成此操作,前提是輸入綁定名稱為input。
2.4.3. 使用函數式風格覆寫 binder 產生的預設綁定名稱
預設情況下,當使用函數式風格時,綁定器會使用上面討論的策略來產生綁定名稱,即 <function-bean-name>-<in>|<out>-[0..n],例如 process-in-0、process-out-0 等。如果您想覆寫這些綁定名稱,您可以透過指定以下屬性來完成。
spring.cloud.stream.function.bindings.<default binding name>。預設綁定名稱是綁定器產生的原始綁定名稱。
例如,假設您有這個函數。
@Bean
public BiFunction<KStream<String, Long>, KTable<String, String>, KStream<String, Long>> process() {
...
}綁定器將產生名稱為 process-in-0、process-in-1 和 process-out-0 的綁定。現在,如果您想將它們完全更改為其他名稱,也許是更特定於網域的綁定名稱,那麼您可以像下面這樣做。
spring.cloud.stream.function.bindings.process-in-0=users
spring.cloud.stream.function.bindings.process-in-0=regions
和
spring.cloud.stream.function.bindings.process-out-0=clicks
之後,您必須在這些新綁定名稱上設定所有綁定層級屬性。
請記住,對於上面描述的函數式程式設計模型,堅持預設綁定名稱在大多數情況下是有意義的。您可能仍然想要執行此覆寫的唯一原因是當您有大量配置屬性並且想要將綁定映射到更友善於網域的名稱時。
2.4.4. 設定 bootstrap server 組態
運行 Kafka Streams 應用程式時,您必須提供 Kafka broker 伺服器資訊。如果您不提供此資訊,則綁定器會預期您在預設 localhost:9092 運行 broker。如果不是這種情況,則需要覆寫它。有幾種方法可以做到這一點。
-
使用啟動屬性 -
spring.kafka.bootstrapServers -
綁定器層級屬性 -
spring.cloud.stream.kafka.streams.binder.brokers
對於綁定器層級屬性,您是否使用透過常規 Kafka 綁定器提供的 broker 屬性並不重要 - spring.cloud.stream.kafka.binder.brokers。Kafka Streams 綁定器將首先檢查是否設定了 Kafka Streams 綁定器特定的 broker 屬性 (spring.cloud.stream.kafka.streams.binder.brokers),如果未找到,它會尋找 spring.cloud.stream.kafka.binder.brokers。
2.5. 記錄序列化和反序列化
Kafka Streams 綁定器允許您以兩種方式序列化和反序列化記錄。一種是 Kafka 提供的原生序列化和反序列化功能,另一種是 Spring Cloud Stream 框架的訊息轉換功能。讓我們看看一些細節。
2.5.1. 輸入反序列化
金鑰始終使用原生 Serdes 進行反序列化。
對於值,預設情況下,入站的反序列化由 Kafka 原生執行。請注意,這與先前 Kafka Streams binder 版本中的預設行為有重大變更,在先前的版本中,反序列化是由框架完成的。
Kafka Streams binder 將嘗試透過查看 java.util.function.Function|Consumer 或 StreamListener 的類型簽名來推斷匹配的 Serde 類型。以下是它匹配 Serdes 的順序。
-
如果應用程式提供類型為
Serde的 bean,並且如果回傳類型使用傳入金鑰或值類型的實際類型參數化,則它將使用該Serde進行入站反序列化。例如,如果您在應用程式中具有以下內容,binder 會偵測到KStream的傳入值類型與在Serdebean 上參數化的類型匹配。它將使用該類型進行入站反序列化。
@Bean
public Serde<Foo() customSerde{
...
}
@Bean
public Function<KStream<String, Foo>, KStream<String, Foo>> process() {
}-
接下來,它會查看類型,並查看它們是否為 Kafka Streams 公開的類型之一。如果是,則使用它們。以下是 binder 將嘗試從 Kafka Streams 匹配的 Serde 類型。
Integer, Long, Short, Double, Float, byte[], UUID and String.
-
如果 Kafka Streams 提供的 Serdes 皆不符合類型,則它將使用 Spring Kafka 提供的 JsonSerde。在這種情況下,binder 會假設類型是 JSON 友善的。如果您有多個值物件作為輸入,這會很有用,因為 binder 將在內部將它們推斷為正確的 Java 類型。不過,在回退到
JsonSerde之前,binder 會檢查 Kafka Streams 配置中設定的預設Serde,以查看它是否為可以與傳入 KStream 類型匹配的Serde。
如果以上策略皆無效,則應用程式必須透過組態提供 Serde。這可以透過兩種方式配置 - 綁定或預設。
首先,binder 將查看是否在綁定層級提供了 Serde。例如,如果您有以下處理器,
@Bean
public BiFunction<KStream<CustomKey, AvroIn1>, KTable<CustomKey, AvroIn2>, KStream<CustomKey, AvroOutput>> process() {...}那麼,您可以使用以下方式提供綁定層級的 Serde
spring.cloud.stream.kafka.streams.bindings.process-in-0.consumer.keySerde=CustomKeySerde
spring.cloud.stream.kafka.streams.bindings.process-in-0.consumer.valueSerde=io.confluent.kafka.streams.serdes.avro.SpecificAvroSerde
spring.cloud.stream.kafka.streams.bindings.process-in-1.consumer.keySerde=CustomKeySerde
spring.cloud.stream.kafka.streams.bindings.process-in-1.consumer.valueSerde=io.confluent.kafka.streams.serdes.avro.SpecificAvroSerde如果您如上所述為每個輸入綁定提供 Serde,則它將具有更高的優先順序,並且 binder 將避開任何 Serde 推斷。 |
如果您希望將預設金鑰/值 Serdes 用於入站反序列化,您可以在 binder 層級執行此操作。
spring.cloud.stream.kafka.streams.binder.configuration.default.key.serde
spring.cloud.stream.kafka.streams.binder.configuration.default.value.serde如果您不想要 Kafka 提供的原生解碼,您可以依賴 Spring Cloud Stream 提供的訊息轉換功能。由於原生解碼是預設值,為了讓 Spring Cloud Stream 反序列化入站值物件,您需要明確停用原生解碼。
例如,如果您具有與上述相同的 BiFunction 處理器,則 spring.cloud.stream.bindings.process-in-0.consumer.nativeDecoding: false。您需要為所有輸入個別停用原生解碼。否則,原生解碼仍將應用於您未停用的那些輸入。
預設情況下,Spring Cloud Stream 將使用 application/json 作為內容類型,並使用適當的 json 訊息轉換器。您可以使用以下屬性和適當的 MessageConverter bean 來使用自訂訊息轉換器。
spring.cloud.stream.bindings.process-in-0.contentType2.5.2. 輸出序列化
出站序列化在很大程度上遵循與上述入站反序列化相同的規則。與入站反序列化一樣,與先前版本的 Spring Cloud Stream 相比,一個主要的變更是出站的序列化由 Kafka 原生處理。在 binder 的 3.0 版本之前,這是由框架本身完成的。
出站的金鑰始終由 Kafka 使用 binder 推斷的匹配 Serde 進行序列化。如果它無法推斷金鑰的類型,則需要使用組態指定。
值 serdes 使用與入站反序列化相同的規則進行推斷。首先,它會匹配以查看輸出類型是否來自應用程式中提供的 bean。如果不是,它會檢查是否與 Kafka 公開的 Serde 匹配,例如 - Integer、Long、Short、Double、Float、byte[]、UUID 和 String。如果這不起作用,則它會回退到 Spring Kafka 專案提供的 JsonSerde,但首先查看預設 Serde 組態,以查看是否有匹配項。請記住,所有這些都是對應用程式透明地發生的。如果這些方法皆無效,則使用者必須透過組態提供要使用的 Serde。
假設您正在使用與上述相同的 BiFunction 處理器。那麼您可以將出站金鑰/值 Serdes 配置如下。
spring.cloud.stream.kafka.streams.bindings.process-out-0.producer.keySerde=CustomKeySerde
spring.cloud.stream.kafka.streams.bindings.process-out-0.producer.valueSerde=io.confluent.kafka.streams.serdes.avro.SpecificAvroSerde如果 Serde 推斷失敗,並且未提供綁定層級的 Serdes,則 binder 會回退到 JsonSerde,但會查看預設 Serdes 是否有匹配項。
預設 serdes 的配置方式與上面描述的反序列化下的方式相同。
spring.cloud.stream.kafka.streams.binder.configuration.default.key.serde spring.cloud.stream.kafka.streams.binder.configuration.default.value.serde
如果您的應用程式使用分支功能並具有多個輸出綁定,則必須針對每個綁定進行配置。再次強調,如果 binder 能夠推斷 Serde 類型,則您不需要進行此配置。
如果您不想要 Kafka 提供的原生編碼,但想要使用框架提供的訊息轉換,則您需要明確停用原生編碼,因為原生編碼是預設值。例如,如果您具有與上述相同的 BiFunction 處理器,則 spring.cloud.stream.bindings.process-out-0.producer.nativeEncoding: false。在分支的情況下,您需要為所有輸出個別停用原生編碼。否則,原生編碼仍將應用於您未停用的那些輸出。
當轉換由 Spring Cloud Stream 完成時,預設情況下,它將使用 application/json 作為內容類型,並使用適當的 json 訊息轉換器。您可以使用以下屬性和對應的 MessageConverter bean 來使用自訂訊息轉換器。
spring.cloud.stream.bindings.process-out-0.contentType當停用原生編碼/解碼時,binder 將不會像原生 Serdes 的情況那樣進行任何推斷。應用程式需要明確提供所有配置選項。因此,通常建議保持 de/serialization 的預設選項,並在使用 Spring Cloud Stream Kafka Streams 應用程式時堅持 Kafka Streams 提供的原生 de/serialization。您必須使用框架提供的訊息轉換功能的一種情況是,當您的上游生產者正在使用特定的序列化策略時。在這種情況下,您希望使用匹配的反序列化策略,因為原生機制可能會失敗。當依賴預設的 Serde 機制時,應用程式必須確保 binder 有辦法正確地將入站和出站與適當的 Serde 對應,否則可能會失敗。
值得一提的是,上面概述的資料 de/serialization 方法僅適用於處理器的邊緣,即 - 入站和出站。您的業務邏輯可能仍然需要呼叫 Kafka Streams API,這些 API 明確需要 Serde 物件。這些仍然是應用程式的責任,並且必須由開發人員相應地處理。
2.6. 錯誤處理
Apache Kafka Streams 提供了原生處理來自反序列化錯誤的異常的功能。有關此支援的詳細資訊,請參閱此處。Apache Kafka Streams 開箱即用提供了兩種反序列化異常處理器 - LogAndContinueExceptionHandler 和 LogAndFailExceptionHandler。顧名思義,前者將記錄錯誤並繼續處理下一個記錄,而後者將記錄錯誤並失敗。LogAndFailExceptionHandler 是預設的反序列化異常處理器。
2.6.1. 處理 Binder 中的反序列化例外
Kafka Streams binder 允許使用以下屬性指定上述反序列化異常處理器。
spring.cloud.stream.kafka.streams.binder.deserializationExceptionHandler: logAndContinue或
spring.cloud.stream.kafka.streams.binder.deserializationExceptionHandler: logAndFail除了上述兩個反序列化異常處理器之外,binder 還提供了第三個處理器,用於將錯誤記錄(毒丸)發送到 DLQ(死信佇列)主題。以下是如何啟用此 DLQ 異常處理器。
spring.cloud.stream.kafka.streams.binder.deserializationExceptionHandler: sendToDlq當設定上述屬性時,所有反序列化錯誤中的記錄都會自動發送到 DLQ 主題。
您可以設定發布 DLQ 訊息的主題名稱,如下所示。
您可以為 DlqDestinationResolver 提供實作,這是一個函數介面。DlqDestinationResolver 接受 ConsumerRecord 和異常作為輸入,然後允許指定主題名稱作為輸出。透過存取 Kafka ConsumerRecord,可以在 BiFunction 的實作中檢查標頭記錄。
以下是為 DlqDestinationResolver 提供實作的範例。
@Bean
public DlqDestinationResolver dlqDestinationResolver() {
return (rec, ex) -> {
if (rec.topic().equals("word1")) {
return "topic1-dlq";
}
else {
return "topic2-dlq";
}
};
}在為 DlqDestinationResolver 提供實作時,需要記住的一件重要事情是,綁定器中的佈建器不會自動為應用程式建立主題。這是因為綁定器無法推斷實作可能傳送到的所有 DLQ 主題的名稱。因此,如果您使用此策略提供 DLQ 名稱,則應用程式有責任確保事先建立這些主題。
如果 DlqDestinationResolver 作為 bean 存在於應用程式中,則它具有更高的優先順序。如果您不想遵循此方法,而是希望使用組態提供靜態 DLQ 名稱,則可以設定以下屬性。
spring.cloud.stream.kafka.streams.bindings.process-in-0.consumer.dlqName: custom-dlq (Change the binding name accordingly)如果設定了此屬性,則錯誤記錄將發送到主題 custom-dlq。如果應用程式未使用上述任何策略,則它將建立一個 DLQ 主題,名稱為 error.<input-topic-name>.<application-id>。例如,如果您的綁定目的地主題是 inputTopic,且應用程式 ID 是 process-applicationId,則預設的 DLQ 主題是 error.inputTopic.process-applicationId。始終建議為每個輸入綁定明確建立一個 DLQ 主題,如果您的目的是啟用 DLQ。
2.6.2. 每個輸入消費者綁定的 DLQ
屬性 spring.cloud.stream.kafka.streams.binder.deserializationExceptionHandler 適用於整個應用程式。這表示如果同一個應用程式中有多個函數或 StreamListener 方法,則此屬性將應用於所有這些方法。但是,如果您在單個處理器中有多個處理器或多個輸入綁定,則可以使用 binder 為每個輸入消費者綁定提供的更細緻的 DLQ 控制。
如果您有以下處理器,
@Bean
public BiFunction<KStream<String, Long>, KTable<String, String>, KStream<String, Long>> process() {
...
}並且您只想在第一個輸入綁定上啟用 DLQ,在第二個綁定上啟用 logAndSkip,那麼您可以在消費者上執行此操作,如下所示。
spring.cloud.stream.kafka.streams.bindings.process-in-0.consumer.deserializationExceptionHandler: sendToDlq spring.cloud.stream.kafka.streams.bindings.process-in-1.consumer.deserializationExceptionHandler: logAndSkip
以這種方式設定反序列化異常處理器比在 binder 層級設定具有更高的優先順序。
2.6.3. DLQ 分割
預設情況下,記錄會使用與原始記錄相同的分割區發布到死信主題。這表示死信主題必須至少具有與原始記錄一樣多的分割區。
若要變更此行為,請將 DlqPartitionFunction 實作新增為應用程式內容中的 @Bean。只能存在一個此類 bean。該函數會收到消費者群組(在大多數情況下與應用程式 ID 相同)、失敗的 ConsumerRecord 和異常。例如,如果您始終想要路由到分割區 0,您可以使用
@Bean
public DlqPartitionFunction partitionFunction() {
return (group, record, ex) -> 0;
}如果您將消費者綁定的 dlqPartitions 屬性設定為 1(且綁定器的 minPartitionCount 等於 1),則無需提供 DlqPartitionFunction;框架將始終使用分割區 0。如果您將消費者綁定的 dlqPartitions 屬性設定為大於 1 的值(或綁定器的 minPartitionCount 大於 1),即使分割區計數與原始主題的計數相同,您也**必須**提供 DlqPartitionFunction bean。 |
在使用 Kafka Streams binder 中的異常處理功能時,需要記住幾件事。
-
屬性
spring.cloud.stream.kafka.streams.binder.deserializationExceptionHandler適用於整個應用程式。這表示如果同一個應用程式中有多個函數或StreamListener方法,則此屬性將應用於所有這些方法。 -
反序列化異常處理與原生反序列化和框架提供的訊息轉換一致地工作。
2.6.4. 處理 Binder 中的生產例外
與上述對反序列化異常處理器的支援不同,binder 沒有提供此類一流的機制來處理生產異常。但是,您仍然可以使用 StreamsBuilderFactoryBean 自訂器來配置生產異常處理器,您可以在下面的後續章節中找到有關它的更多詳細資訊。
2.7. 重試關鍵業務邏輯
在某些情況下,您可能想要重試對應用程式至關重要的業務邏輯的某些部分。可能存在對關係資料庫的外部呼叫或從 Kafka Streams 處理器調用 REST 端點。這些呼叫可能會因各種原因而失敗,例如網路問題或遠端服務不可用。通常,如果您可以再次嘗試它們,這些失敗可能會自行解決。預設情況下,Kafka Streams binder 為所有輸入綁定建立 RetryTemplate bean。
如果函數具有以下簽名,
@Bean
public java.util.function.Consumer<KStream<Object, String>> process()並且使用預設綁定名稱,則 RetryTemplate 將註冊為 process-in-0-RetryTemplate。這遵循綁定名稱 (process-in-0) 後跟字面文字 -RetryTemplate 的慣例。在多個輸入綁定的情況下,每個綁定將有一個單獨的 RetryTemplate bean 可用。如果應用程式中存在自訂 RetryTemplate bean,並透過 spring.cloud.stream.bindings.<binding-name>.consumer.retryTemplateName 提供,則它優先於任何輸入綁定層級的重試範本配置屬性。
一旦將來自綁定的 RetryTemplate 注入到應用程式中,就可以使用它來重試應用程式的任何關鍵部分。以下是一個範例
@Bean
public java.util.function.Consumer<KStream<Object, String>> process(@Lazy @Qualifier("process-in-0-RetryTemplate") RetryTemplate retryTemplate) {
return input -> input
.process(() -> new Processor<Object, String>() {
@Override
public void init(ProcessorContext processorContext) {
}
@Override
public void process(Object o, String s) {
retryTemplate.execute(context -> {
//Critical business logic goes here.
});
}
@Override
public void close() {
}
});
}或者您可以使用自訂 RetryTemplate,如下所示。
@EnableAutoConfiguration
public static class CustomRetryTemplateApp {
@Bean
@StreamRetryTemplate
RetryTemplate fooRetryTemplate() {
RetryTemplate retryTemplate = new RetryTemplate();
RetryPolicy retryPolicy = new SimpleRetryPolicy(4);
FixedBackOffPolicy backOffPolicy = new FixedBackOffPolicy();
backOffPolicy.setBackOffPeriod(1);
retryTemplate.setBackOffPolicy(backOffPolicy);
retryTemplate.setRetryPolicy(retryPolicy);
return retryTemplate;
}
@Bean
public java.util.function.Consumer<KStream<Object, String>> process() {
return input -> input
.process(() -> new Processor<Object, String>() {
@Override
public void init(ProcessorContext processorContext) {
}
@Override
public void process(Object o, String s) {
fooRetryTemplate().execute(context -> {
//Critical business logic goes here.
});
}
@Override
public void close() {
}
});
}
}請注意,當重試耗盡時,預設情況下,將會擲回最後一個異常,導致處理器終止。如果您希望處理異常並繼續處理,您可以將 RecoveryCallback 新增到 execute 方法:以下是一個範例。
retryTemplate.execute(context -> {
//Critical business logic goes here.
}, context -> {
//Recovery logic goes here.
return null;
));有關 RetryTemplate、重試策略、退避策略等的更多資訊,請參閱 Spring Retry 專案。
2.8. 狀態儲存區
當使用高階 DSL 並進行適當的呼叫時,狀態儲存區會由 Kafka Streams 自動建立,這些呼叫會觸發狀態儲存區。
如果您想要將傳入的 KTable 綁定實體化為具名的狀態儲存區,則可以使用以下策略。
假設您有以下函數。
@Bean
public BiFunction<KStream<String, Long>, KTable<String, String>, KStream<String, Long>> process() {
...
}然後透過設定以下屬性,傳入的 KTable 資料將實體化到具名的狀態儲存區中。
spring.cloud.stream.kafka.streams.bindings.process-in-1.consumer.materializedAs: incoming-store您可以在應用程式中定義自訂狀態儲存區作為 bean,這些 bean 將被偵測到並由 binder 新增到 Kafka Streams builder。特別是當使用處理器 API 時,您需要手動註冊狀態儲存區。為了做到這一點,您可以在應用程式中建立 StateStore 作為 bean。以下是定義此類 bean 的範例。
@Bean
public StoreBuilder myStore() {
return Stores.keyValueStoreBuilder(
Stores.persistentKeyValueStore("my-store"), Serdes.Long(),
Serdes.Long());
}
@Bean
public StoreBuilder otherStore() {
return Stores.windowStoreBuilder(
Stores.persistentWindowStore("other-store",
1L, 3, 3L, false), Serdes.Long(),
Serdes.Long());
}然後應用程式可以直接存取這些狀態儲存區。
在啟動期間,binder 將處理上述 bean 並將其傳遞到 Streams builder 物件。
存取狀態儲存區
Processor<Object, Product>() {
WindowStore<Object, String> state;
@Override
public void init(ProcessorContext processorContext) {
state = (WindowStore)processorContext.getStateStore("mystate");
}
...
}當涉及到註冊全域狀態儲存區時,這將不起作用。若要註冊全域狀態儲存區,請參閱下面有關自訂 StreamsBuilderFactoryBean 的章節。
2.9. 互動式查詢
Kafka Streams binder API 公開了一個名為 InteractiveQueryService 的類別,以互動式查詢狀態儲存區。您可以將其作為 Spring bean 在您的應用程式中存取。從您的應用程式存取此 bean 的一種簡單方法是 autowire bean。
@Autowired
private InteractiveQueryService interactiveQueryService;一旦您取得對此 bean 的存取權限,您就可以查詢您感興趣的特定狀態儲存區。請參閱下文。
ReadOnlyKeyValueStore<Object, Object> keyValueStore =
interactiveQueryService.getQueryableStoreType("my-store", QueryableStoreTypes.keyValueStore());在啟動期間,上述用於檢索儲存區的方法呼叫可能會失敗。例如,它可能仍在初始化狀態儲存區的中間。在這種情況下,重試此操作將會很有用。Kafka Streams binder 提供了一個簡單的重試機制來適應這一點。
以下是您可以用於控制此重試的兩個屬性。
-
spring.cloud.stream.kafka.streams.binder.stateStoreRetry.maxAttempts - 預設值為
1。 -
spring.cloud.stream.kafka.streams.binder.stateStoreRetry.backOffInterval - 預設值為
1000毫秒。
如果正在運行 kafka streams 應用程式的多個執行個體,那麼在您可以互動式查詢它們之前,您需要識別哪個應用程式執行個體託管您正在查詢的特定金鑰。InteractiveQueryService API 提供了用於識別主機資訊的方法。
為了使此功能正常運作,您必須配置屬性 application.server,如下所示
spring.cloud.stream.kafka.streams.binder.configuration.application.server: <server>:<port>以下是一些程式碼片段
org.apache.kafka.streams.state.HostInfo hostInfo = interactiveQueryService.getHostInfo("store-name",
key, keySerializer);
if (interactiveQueryService.getCurrentHostInfo().equals(hostInfo)) {
//query from the store that is locally available
}
else {
//query from the remote host
}2.9.1. 通過 InteractiveQueryService 提供的其他 API 方法
使用以下 API 方法檢索與給定儲存區和金鑰組合相關聯的 KeyQueryMetadata 物件。
public <K> KeyQueryMetadata getKeyQueryMetadata(String store, K key, Serializer<K> serializer)使用以下 API 方法檢索與給定儲存區和金鑰組合相關聯的 KakfaStreams 物件。
public <K> KafkaStreams getKafkaStreams(String store, K key, Serializer<K> serializer)2.10. 健康指示器
健康指示器需要依賴項 spring-boot-starter-actuator。對於 maven,請使用
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>Spring Cloud Stream Kafka Streams Binder 提供了一個健康指示器來檢查底層 streams 執行緒的狀態。Spring Cloud Stream 定義了一個屬性 management.health.binders.enabled 來啟用健康指示器。請參閱 Spring Cloud Stream 文件。
健康指示器為每個 stream 執行緒的中繼資料提供以下詳細資訊
-
執行緒名稱
-
執行緒狀態:
CREATED、RUNNING、PARTITIONS_REVOKED、PARTITIONS_ASSIGNED、PENDING_SHUTDOWN或DEAD -
活動任務:任務 ID 和分割區
-
備用任務:任務 ID 和分割區
預設情況下,只有全域狀態可見(UP 或 DOWN)。若要顯示詳細資訊,必須將屬性 management.endpoint.health.show-details 設定為 ALWAYS 或 WHEN_AUTHORIZED。有關健康資訊的更多詳細資訊,請參閱 Spring Boot Actuator 文件。
如果所有註冊的 Kafka 執行緒都處於 RUNNING 狀態,則健康指示器的狀態為 UP。 |
由於 Kafka Streams binder 中有三個個別的 binder(KStream、KTable 和 GlobalKTable),因此它們都將報告健康狀態。當啟用 show-details 時,報告的某些資訊可能顯得冗餘。
當同一個應用程式中存在多個 Kafka Streams 處理器時,將會為所有這些處理器報告健康檢查,並將按 Kafka Streams 的應用程式 ID 進行分類。
2.11. 訪問 Kafka Streams 指標
Spring Cloud Stream Kafka Streams binder 提供 Kafka Streams 指標,這些指標可以透過 Micrometer MeterRegistry 匯出。
對於 Spring Boot 版本 2.2.x,指標支援是透過 binder 的自訂 Micrometer 指標實作提供的。對於 Spring Boot 版本 2.3.x,Kafka Streams 指標支援是透過 Micrometer 原生提供的。
當透過 Boot actuator 端點存取指標時,請務必將 metrics 新增到屬性 management.endpoints.web.exposure.include。然後您可以存取 /acutator/metrics 以取得所有可用指標的清單,然後可以透過相同的 URI (/actuator/metrics/<metric-name>) 個別存取這些指標。
2.12. 混合高階 DSL 和低階 Processor API
Kafka Streams 提供了兩種變體的 API。它具有較高階的 DSL 類 API,您可以在其中鏈接許多功能程式設計師可能熟悉的各種操作。Kafka Streams 還允許存取低階處理器 API。處理器 API 雖然非常強大並且可以更低階地控制事物,但本質上是命令式的。用於 Spring Cloud Stream 的 Kafka Streams binder 允許您使用高階 DSL 或混合使用 DSL 和處理器 API。混合使用這兩種變體為您提供了許多選項來控制應用程式中的各種用例。應用程式可以使用 transform 或 process 方法 API 呼叫來存取處理器 API。
以下是如何在 Spring Cloud Stream 應用程式中使用 process API 將 DSL 和處理器 API 組合在一起的範例。
@Bean
public Consumer<KStream<Object, String>> process() {
return input ->
input.process(() -> new Processor<Object, String>() {
@Override
@SuppressWarnings("unchecked")
public void init(ProcessorContext context) {
this.context = context;
}
@Override
public void process(Object key, String value) {
//business logic
}
@Override
public void close() {
});
}以下是使用 transform API 的範例。
@Bean
public Consumer<KStream<Object, String>> process() {
return (input, a) ->
input.transform(() -> new Transformer<Object, String, KeyValue<Object, String>>() {
@Override
public void init(ProcessorContext context) {
}
@Override
public void close() {
}
@Override
public KeyValue<Object, String> transform(Object key, String value) {
// business logic - return transformed KStream;
}
});
}process API 方法呼叫是終端操作,而 transform API 是非終端操作,並為您提供潛在轉換的 KStream,您可以使用它繼續使用 DSL 或處理器 API 進行進一步處理。
2.13. 輸出端的分割支援
Kafka Streams 處理器通常將處理後的輸出發送到出站 Kafka 主題。如果出站主題已分割,並且處理器需要將外發資料發送到特定分割區,則應用程式需要提供類型為 StreamPartitioner 的 bean。有關更多詳細資訊,請參閱 StreamPartitioner。讓我們看一些範例。
這是我們已經多次看到的相同處理器,
@Bean
public Function<KStream<Object, String>, KStream<?, WordCount>> process() {
...
}以下是輸出綁定目的地
spring.cloud.stream.bindings.process-out-0.destination: outputTopic如果主題 outputTopic 有 4 個分割區,如果您不提供分割策略,Kafka Streams 將使用預設分割策略,這可能不是您想要的結果,具體取決於特定用例。假設,您想要將任何與 spring 匹配的金鑰發送到分割區 0,將 cloud 發送到分割區 1,將 stream 發送到分割區 2,並將所有其他內容發送到分割區 3。這就是您需要在應用程式中執行的操作。
@Bean
public StreamPartitioner<String, WordCount> streamPartitioner() {
return (t, k, v, n) -> {
if (k.equals("spring")) {
return 0;
}
else if (k.equals("cloud")) {
return 1;
}
else if (k.equals("stream")) {
return 2;
}
else {
return 3;
}
};
}這是一個基本的實作,但是,您可以存取記錄的金鑰/值、主題名稱和分割區總數。因此,如果需要,您可以實作複雜的分割策略。
您還需要提供此 bean 名稱以及應用程式配置。
spring.cloud.stream.kafka.streams.bindings.process-out-0.producer.streamPartitionerBeanName: streamPartitioner應用程式中的每個輸出主題都需要像這樣單獨配置。
2.14. StreamsBuilderFactoryBean 自訂器
通常需要自訂建立 KafkaStreams 物件的 StreamsBuilderFactoryBean。基於 Spring Kafka 提供的底層支援,binder 允許您自訂 StreamsBuilderFactoryBean。您可以使用 StreamsBuilderFactoryBeanCustomizer 來自訂 StreamsBuilderFactoryBean 本身。然後,一旦您透過此自訂器存取 StreamsBuilderFactoryBean,您可以使用 KafkaStreamsCustomzier 自訂對應的 KafkaStreams。這兩個自訂器都是 Spring for Apache Kafka 專案的一部分。
以下是使用 StreamsBuilderFactoryBeanCustomizer 的範例。
@Bean
public StreamsBuilderFactoryBeanCustomizer streamsBuilderFactoryBeanCustomizer() {
return sfb -> sfb.setStateListener((newState, oldState) -> {
//Do some action here!
});
}上面顯示的是您可以執行以自訂 StreamsBuilderFactoryBean 的操作的說明。您基本上可以從 StreamsBuilderFactoryBean 呼叫任何可用的突變操作來對其進行自訂。此自訂器將在工廠 bean 啟動之前由 binder 調用。
一旦您取得對 StreamsBuilderFactoryBean 的存取權限,您也可以自訂底層的 KafkaStreams 物件。以下是執行此操作的藍圖。
@Bean
public StreamsBuilderFactoryBeanCustomizer streamsBuilderFactoryBeanCustomizer() {
return factoryBean -> {
factoryBean.setKafkaStreamsCustomizer(new KafkaStreamsCustomizer() {
@Override
public void customize(KafkaStreams kafkaStreams) {
kafkaStreams.setUncaughtExceptionHandler((t, e) -> {
});
}
});
};
}KafkaStreamsCustomizer 將在底層 KafkaStreams 啟動之前由 StreamsBuilderFactoryBeabn 呼叫。
整個應用程式中只能有一個 StreamsBuilderFactoryBeanCustomizer。那麼,我們如何解釋多個 Kafka Streams 處理器,因為每個處理器都由個別的 StreamsBuilderFactoryBean 物件支援?在這種情況下,如果這些處理器的自訂需要不同,則應用程式需要根據應用程式 ID 應用一些篩選器。
例如,
@Bean
public StreamsBuilderFactoryBeanCustomizer streamsBuilderFactoryBeanCustomizer() {
return factoryBean -> {
if (factoryBean.getStreamsConfiguration().getProperty(StreamsConfig.APPLICATION_ID_CONFIG)
.equals("processor1-application-id")) {
factoryBean.setKafkaStreamsCustomizer(new KafkaStreamsCustomizer() {
@Override
public void customize(KafkaStreams kafkaStreams) {
kafkaStreams.setUncaughtExceptionHandler((t, e) -> {
});
}
});
}
};2.14.1. 使用自訂器註冊全域狀態儲存區
如上所述,binder 沒有提供一流的方式來註冊全域狀態儲存區作為一項功能。為此,您需要使用自訂器。以下是如何執行此操作。
@Bean
public StreamsBuilderFactoryBeanCustomizer customizer() {
return fb -> {
try {
final StreamsBuilder streamsBuilder = fb.getObject();
streamsBuilder.addGlobalStore(...);
}
catch (Exception e) {
}
};
}同樣,如果您有多個處理器,您希望透過使用如上所述的應用程式 ID 篩選掉其他 StreamsBuilderFactoryBean 物件,將全域狀態儲存區附加到正確的 StreamsBuilder。
2.14.2. 使用自訂器註冊生產例外處理器
在錯誤處理章節中,我們指出 binder 沒有提供一流的方式來處理生產異常。儘管如此,您仍然可以使用 StreamsBuilderFacotryBean 自訂器來註冊生產異常處理器。請參閱下文。
@Bean
public StreamsBuilderFactoryBeanCustomizer customizer() {
return fb -> {
fb.getStreamsConfiguration().put(StreamsConfig.DEFAULT_PRODUCTION_EXCEPTION_HANDLER_CLASS_CONFIG,
CustomProductionExceptionHandler.class);
};
}再次強調,如果您有多個處理器,您可能希望針對正確的 StreamsBuilderFactoryBean 適當地設定它。您也可以使用組態屬性新增此類生產異常處理器(有關更多資訊,請參閱下文),但如果您選擇採用程式化方法,這是一個選項。
2.15. 時間戳記提取器
Kafka Streams 允許您根據時間戳記的各種概念來控制消費者記錄的處理。預設情況下,Kafka Streams 會提取嵌入在消費者記錄中的時間戳記中繼資料。您可以透過為每個輸入綁定提供不同的 TimestampExtractor 實作來變更此預設行為。以下是有關如何執行此操作的一些詳細資訊。
@Bean
public Function<KStream<Long, Order>,
Function<KTable<Long, Customer>,
Function<GlobalKTable<Long, Product>, KStream<Long, Order>>>> process() {
return orderStream ->
customers ->
products -> orderStream;
}
@Bean
public TimestampExtractor timestampExtractor() {
return new WallclockTimestampExtractor();
}然後,您為每個消費者綁定設定上述 TimestampExtractor bean 名稱。
spring.cloud.stream.kafka.streams.bindings.process-in-0.consumer.timestampExtractorBeanName=timestampExtractor
spring.cloud.stream.kafka.streams.bindings.process-in-1.consumer.timestampExtractorBeanName=timestampExtractor
spring.cloud.stream.kafka.streams.bindings.process-in-2.consumer.timestampExtractorBeanName=timestampExtractor"如果您跳過輸入消費者綁定以設定自訂時間戳記提取器,則該消費者將使用預設設定。
2.16. 具有 Kafka Streams based binders 和常規 Kafka Binder 的多個 binders
您的應用程式可以同時具有基於常規 Kafka binder 的函數/消費者/供應商和基於 Kafka Streams 的處理器。但是,您不能在單個函數或消費者中混合使用它們。
以下是一個範例,其中您在同一個應用程式中同時具有基於 binder 的元件。
@Bean
public Function<String, String> process() {
return s -> s;
}
@Bean
public Function<KStream<Object, String>, KStream<?, WordCount>> kstreamProcess() {
return input -> input;
}這是來自配置的相關部分
spring.cloud.stream.function.definition=process;kstreamProcess
spring.cloud.stream.bindings.process-in-0.destination=foo
spring.cloud.stream.bindings.process-out-0.destination=bar
spring.cloud.stream.bindings.kstreamProcess-in-0.destination=bar
spring.cloud.stream.bindings.kstreamProcess-out-0.destination=foobar如果您具有與上述相同的應用程式,但正在處理兩個不同的 Kafka 叢集,例如,常規 process 作用於 Kafka 叢集 1 和叢集 2(從叢集 1 接收資料並發送到叢集 2),並且 Kafka Streams 處理器作用於 Kafka 叢集 2,則情況會變得更加複雜。然後,您必須使用 Spring Cloud Stream 提供的 多個 binder 功能。
以下是該場景中您的配置可能發生的變更。
# multi binder configuration
spring.cloud.stream.binders.kafka1.type: kafka
spring.cloud.stream.binders.kafka1.environment.spring.cloud.stream.kafka.streams.binder.brokers=${kafkaCluster-1} #Replace kafkaCluster-1 with the approprate IP of the cluster
spring.cloud.stream.binders.kafka2.type: kafka
spring.cloud.stream.binders.kafka2.environment.spring.cloud.stream.kafka.streams.binder.brokers=${kafkaCluster-2} #Replace kafkaCluster-2 with the approprate IP of the cluster
spring.cloud.stream.binders.kafka3.type: kstream
spring.cloud.stream.binders.kafka3.environment.spring.cloud.stream.kafka.streams.binder.brokers=${kafkaCluster-2} #Replace kafkaCluster-2 with the approprate IP of the cluster
spring.cloud.stream.function.definition=process;kstreamProcess
# From cluster 1 to cluster 2 with regular process function
spring.cloud.stream.bindings.process-in-0.destination=foo
spring.cloud.stream.bindings.process-in-0.binder=kafka1 # source from cluster 1
spring.cloud.stream.bindings.process-out-0.destination=bar
spring.cloud.stream.bindings.process-out-0.binder=kafka2 # send to cluster 2
# Kafka Streams processor on cluster 2
spring.cloud.stream.bindings.kstreamProcess-in-0.destination=bar
spring.cloud.stream.bindings.kstreamProcess-in-0.binder=kafka3
spring.cloud.stream.bindings.kstreamProcess-out-0.destination=foobar
spring.cloud.stream.bindings.kstreamProcess-out-0.binder=kafka3請注意以上配置。我們有兩種 binder 類型,但總共有 3 個 binder,第一個是基於叢集 1 (kafka1) 的常規 Kafka binder,然後是另一個基於叢集 2 (kafka2) 的 Kafka binder,最後是 kstream (kafka3) 。應用程式中的第一個處理器從 kafka1 接收資料並發布到 kafka2,其中兩個 binder 都基於常規 Kafka binder,但叢集不同。第二個處理器是 Kafka Streams 處理器,它從 kafka3 消費資料,kafka3 與 kafka2 屬於同一個叢集,但 binder 類型不同。
由於 Kafka Streams binder 系列中有三種不同的 binder 類型 - kstream、ktable 和 globalktable - 如果您的應用程式具有基於這些 binder 中任何一種的多個綁定,則需要明確提供該類型作為 binder 類型。
例如,如果您有如下處理器,
@Bean
public Function<KStream<Long, Order>,
Function<KTable<Long, Customer>,
Function<GlobalKTable<Long, Product>, KStream<Long, EnrichedOrder>>>> enrichOrder() {
...
}那麼,這必須在多個 binder 場景中配置為如下所示。請注意,這僅在您具有真正的多個 binder 場景時才需要,在這種場景中,有多個處理器在單個應用程式中處理多個叢集。在這種情況下,需要為 binder 明確提供綁定,以區分其他處理器的 binder 類型和叢集。
spring.cloud.stream.binders.kafka1.type: kstream
spring.cloud.stream.binders.kafka1.environment.spring.cloud.stream.kafka.streams.binder.brokers=${kafkaCluster-2}
spring.cloud.stream.binders.kafka2.type: ktable
spring.cloud.stream.binders.kafka2.environment.spring.cloud.stream.kafka.streams.binder.brokers=${kafkaCluster-2}
spring.cloud.stream.binders.kafka3.type: globalktable
spring.cloud.stream.binders.kafka3.environment.spring.cloud.stream.kafka.streams.binder.brokers=${kafkaCluster-2}
spring.cloud.stream.bindings.enrichOrder-in-0.binder=kafka1 #kstream
spring.cloud.stream.bindings.enrichOrder-in-1.binder=kafka2 #ktablr
spring.cloud.stream.bindings.enrichOrder-in-2.binder=kafka3 #globalktable
spring.cloud.stream.bindings.enrichOrder-out-0.binder=kafka1 #kstream
# rest of the configuration is omitted.2.17. 狀態清除
預設情況下,當綁定停止時,會呼叫 Kafkastreams.cleanup() 方法。請參閱 Spring Kafka 文件。若要修改此行為,只需將單個 CleanupConfig @Bean(配置為在啟動、停止或都不清理)新增到應用程式內容中;bean 將被偵測到並連接到工廠 bean。
2.18. Kafka Streams 拓撲視覺化
Kafka Streams binder 提供了以下 actuator 端點,用於檢索拓撲描述,您可以使用該描述使用外部工具視覺化拓撲。
/actuator/kafkastreamstopology
/actuator/kafkastreamstopology/<處理器的 application-id>
您需要包含來自 Spring Boot 的 actuator 和 web 依賴項才能存取這些端點。此外,您還需要將 kafkastreamstopology 新增到 management.endpoints.web.exposure.include 屬性。預設情況下,kafkastreamstopology 端點已停用。
2.19. 組態選項
本節包含 Kafka Streams binder 使用的配置選項。
有關與 binder 相關的通用配置選項和屬性,請參閱核心文件。
2.19.1. Kafka Streams Binder 屬性
以下屬性在 binder 層級可用,並且必須以 spring.cloud.stream.kafka.streams.binder. 為前綴。
- configuration
-
包含與 Apache Kafka Streams API 相關屬性的金鑰/值對的 Map。此屬性必須以
spring.cloud.stream.kafka.streams.binder.為前綴。以下是使用此屬性的一些範例。
spring.cloud.stream.kafka.streams.binder.configuration.default.key.serde=org.apache.kafka.common.serialization.Serdes$StringSerde
spring.cloud.stream.kafka.streams.binder.configuration.default.value.serde=org.apache.kafka.common.serialization.Serdes$StringSerde
spring.cloud.stream.kafka.streams.binder.configuration.commit.interval.ms=1000有關可能進入 streams 配置的所有屬性的更多資訊,請參閱 Apache Kafka Streams 文件中的 StreamsConfig JavaDocs。您可以透過此屬性設定可以從 StreamsConfig 設定的所有配置。當使用此屬性時,它適用於整個應用程式,因為這是一個 binder 層級屬性。如果您的應用程式中有更多處理器,則所有處理器都將獲取這些屬性。在 application.id 等屬性的情況下,這將變得有問題,因此您必須仔細檢查如何使用此 binder 層級 configuration 屬性對應來自 StreamsConfig 的屬性。
- functions.<function-bean-name>.applicationId
-
僅適用於函數式處理器。這可用於在應用程式中為每個函數設定應用程式 ID。在有多個函數的情況下,這是一種方便設定應用程式 ID 的方式。
- functions.<function-bean-name>.configuration
-
僅適用於函數式處理器。此映射包含鍵/值對,其中包含與 Apache Kafka Streams API 相關的屬性。這與上面描述的繫結器層級
configuration屬性類似,但此層級的configuration屬性僅限於指定的函數。當您有多個處理器,並且想要根據特定函數限制對組態的存取時,您可能需要使用此屬性。所有StreamsConfig屬性都可以在此處使用。 - brokers
-
Broker URL
預設值:
localhost - zkNodes
-
Zookeeper URL
預設值:
localhost - deserializationExceptionHandler
-
還原序列化錯誤處理常式類型。此處理常式應用於繫結器層級,因此應用於應用程式中的所有輸入繫結。有一種更精細的方式可以在消費者繫結層級控制它。可能的值為 -
logAndContinue、logAndFail或sendToDlq預設值:
logAndFail - applicationId
-
在繫結器層級全域設定 Kafka Streams 應用程式的 application.id 的便捷方式。如果應用程式包含多個函數或
StreamListener方法,則應以不同的方式設定應用程式 ID。請參閱上面詳細討論設定應用程式 ID 的部分。預設值:應用程式將產生靜態應用程式 ID。 有關更多詳細資訊,請參閱應用程式 ID 章節。
- stateStoreRetry.maxAttempts
-
嘗試連線到狀態儲存的最大次數。
預設值: 1
- stateStoreRetry.backoffPeriod
-
在重試時嘗試連線到狀態儲存的回退週期。
預設值: 1000 毫秒
- consumerProperties
-
繫結器層級的任意消費者屬性。
- producerProperties
-
繫結器層級的任意生產者屬性。
2.19.2. Kafka Streams 生產者屬性
以下屬性僅適用於 Kafka Streams 生產者,並且必須以 spring.cloud.stream.kafka.streams.bindings.<binding name>.producer. 為前綴。為了方便起見,如果有多個輸出繫結並且它們都需要一個通用值,則可以使用前綴 spring.cloud.stream.kafka.streams.default.producer. 來配置。
- keySerde
-
要使用的 key serde
預設值:請參閱上面關於訊息反/序列化的討論
- valueSerde
-
要使用的 value serde
預設值:請參閱上面關於訊息反/序列化的討論
- useNativeEncoding
-
啟用/停用原生編碼的旗標
預設值:
true。
streamPartitionerBeanName:要在消費者端使用的自訂輸出分割器 bean 名稱。應用程式可以提供自訂的 StreamPartitioner 作為 Spring bean,並且可以將此 bean 的名稱提供給生產者以取代預設的分割器。
+ 預設值:請參閱上面關於輸出分割支援的討論。
- producedAs
-
處理器產生輸出的接收器組件的自訂名稱。
預設值:
none(由 Kafka Streams 產生)
2.19.3. Kafka Streams 消費者屬性
以下屬性適用於 Kafka Streams 消費者,並且必須以 spring.cloud.stream.kafka.streams.bindings.<binding-name>.consumer. 為前綴。為了方便起見,如果有多個輸入繫結並且它們都需要一個通用值,則可以使用前綴 spring.cloud.stream.kafka.streams.default.consumer. 來配置。
- applicationId
-
為每個輸入繫結設定 application.id。這僅適用於基於
StreamListener的處理器,對於基於函數的處理器,請參閱上面概述的其他方法。預設值:請參閱上面。
- keySerde
-
要使用的 key serde
預設值:請參閱上面關於訊息反/序列化的討論
- valueSerde
-
要使用的 value serde
預設值:請參閱上面關於訊息反/序列化的討論
- materializedAs
-
在使用傳入的 KTable 類型時要具體化的狀態儲存
預設值:
none。 - useNativeDecoding
-
啟用/停用原生解碼的旗標
預設值:
true。 - dlqName
-
DLQ 主題名稱。
預設值:請參閱上面關於錯誤處理和 DLQ 的討論。
- startOffset
-
如果沒有可供消費的已提交偏移量,則從哪個偏移量開始。這主要用於消費者第一次從主題消費時。Kafka Streams 使用
earliest作為預設策略,而繫結器使用相同的預設值。可以使用此屬性將其覆蓋為latest。預設值:
earliest。
注意:在消費者端使用 resetOffsets 對 Kafka Streams 繫結器沒有任何影響。與基於訊息通道的繫結器不同,Kafka Streams 繫結器不會按需搜尋開頭或結尾。
- deserializationExceptionHandler
-
還原序列化錯誤處理常式類型。此處理常式應用於每個消費者繫結,與之前描述的繫結器層級屬性相反。可能的值為 -
logAndContinue、logAndFail或sendToDlq預設值:
logAndFail - timestampExtractorBeanName
-
要在消費者端使用的特定時間戳記提取器 bean 名稱。應用程式可以提供
TimestampExtractor作為 Spring bean,並且可以將此 bean 的名稱提供給消費者以取代預設的提取器。預設值:請參閱上面關於時間戳記提取器的討論。
- eventTypes
-
此繫結支援的事件類型逗號分隔列表。
預設值:
none - eventTypeHeaderKey
-
通過此繫結的每個傳入記錄上的事件類型標頭鍵。
預設值:
event_type - consumedAs
-
處理器從中消費的來源組件的自訂名稱。
預設值:
none(由 Kafka Streams 產生)
2.19.4. 關於並發性的特別注意事項
在 Kafka Streams 中,您可以使用 num.stream.threads 屬性來控制處理器可以建立的執行緒數量。您可以使用上面在繫結器、函數、生產者或消費者層級下描述的各種 configuration 選項來執行此操作。您也可以使用核心 Spring Cloud Stream 為此目的提供的 concurrency 屬性。使用此屬性時,您需要在消費者端使用它。當您在函數或 StreamListener 中有多個輸入繫結時,請在第一個輸入繫結上設定此屬性。例如,當設定 spring.cloud.stream.bindings.process-in-0.consumer.concurrency 時,繫結器會將其轉換為 num.stream.threads。如果您有多個處理器,並且一個處理器定義了繫結層級並行性,但其他處理器沒有,則那些沒有繫結層級並行性的處理器將預設回通過 spring.cloud.stream.kafka.streams.binder.configuration.num.stream.threads 指定的繫結器範圍屬性。如果此繫結器組態不可用,則應用程式將使用 Kafka Streams 設定的預設值。
附錄
附錄 A:建置
A.1. 基本編譯和測試
要建置原始碼,您將需要安裝 JDK 1.7。
建置使用 Maven Wrapper,因此您不必安裝特定版本的 Maven。要啟用測試,您應該在建置之前執行 Kafka 伺服器 0.9 或更高版本。請參閱下文以獲取有關執行伺服器的更多資訊。
主要的建置命令是
$ ./mvnw clean install
如果您願意,也可以新增 '-DskipTests' 以避免執行測試。
您也可以自行安裝 Maven (>=3.3.3) 並在下面的範例中使用 mvn 命令代替 ./mvnw。如果您這樣做,如果您的本機 Maven 設定不包含 Spring 預發行版本的成品儲存庫宣告,您可能還需要新增 -P spring。 |
請注意,您可能需要通過設定 MAVEN_OPTS 環境變數(值類似於 -Xmx512m -XX:MaxPermSize=128m)來增加 Maven 可用的記憶體量。我們嘗試在 .mvn 組態中涵蓋這一點,因此如果您發現您必須這樣做才能使建置成功,請提出工單以將設定新增到原始碼控制。 |
需要中介軟體的專案通常包含 docker-compose.yml,因此請考慮使用 Docker Compose 在 Docker 容器中執行中介軟體伺服器。
A.2. 文件
有一個“完整”設定檔將產生文件。
A.3. 使用程式碼
如果您沒有 IDE 偏好,我們建議您在使用程式碼時使用 Spring Tools Suite 或 Eclipse。我們使用 m2eclipe eclipse 外掛程式來獲得 Maven 支援。其他 IDE 和工具也應該可以正常運作。
A.3.1. 使用 m2eclipse 匯入到 eclipse
我們建議在使用 Eclipse 時使用 m2eclipe eclipse 外掛程式。如果您尚未安裝 m2eclipse,可以從“eclipse marketplace”取得。
遺憾的是,m2e 尚不支援 Maven 3.3,因此將專案匯入 Eclipse 後,您還需要告訴 m2eclipse 為專案使用 .settings.xml 檔案。如果您不這樣做,您可能會看到許多與專案中的 POM 相關的不同錯誤。開啟您的 Eclipse 偏好設定,展開 Maven 偏好設定,然後選取使用者設定。在使用者設定欄位中,按一下瀏覽並導航到您匯入的 Spring Cloud 專案,選取該專案中的 .settings.xml 檔案。按一下套用,然後按一下確定以儲存偏好設定變更。
或者,您可以將儲存庫設定從 .settings.xml 複製到您自己的 ~/.m2/settings.xml 中。 |
A.3.2. 不使用 m2eclipse 匯入到 eclipse
如果您不想使用 m2eclipse,可以使用以下命令產生 eclipse 專案元資料
$ ./mvnw eclipse:eclipse
可以通過從 file 選單中選取 import existing projects 來匯入產生的 eclipse 專案。
[[contributing] == 貢獻
Spring Cloud 在非限制性的 Apache 2.0 許可下發布,並遵循非常標準的 Github 開發流程,使用 Github 追蹤器來處理問題,並將提取請求合併到 master 中。如果您想貢獻即使是微不足道的事情,也請不要猶豫,但請遵循以下準則。
A.4. 簽署貢獻者許可協議
在我們接受重要的修補程式或提取請求之前,我們需要您簽署貢獻者協議。簽署貢獻者協議並不授予任何人對主要儲存庫的提交權限,但這確實意味著我們可以接受您的貢獻,並且如果我們這樣做,您將獲得作者署名。活躍的貢獻者可能會被邀請加入核心團隊,並被賦予合併提取請求的能力。
A.5. 程式碼慣例和整理
這些都不是提取請求的必要條件,但它們都會有所幫助。它們也可以在原始提取請求之後但在合併之前新增。
-
使用 Spring Framework 程式碼格式慣例。如果您使用 Eclipse,您可以使用 Spring Cloud Build 專案中的
eclipse-code-formatter.xml檔案匯入格式器設定。如果使用 IntelliJ,您可以使用 Eclipse Code Formatter Plugin 外掛程式來匯入同一個檔案。 -
確保所有新的
.java檔案都有一個簡單的 Javadoc 類別註解,其中至少包含一個識別您的@author標籤,並且最好至少有一個段落說明該類別的用途。 -
將 ASF 許可標頭註解新增到所有新的
.java檔案(從專案中的現有檔案複製) -
將您自己新增為您大幅修改的 .java 檔案(超過外觀變更)的
@author。 -
新增一些 Javadoc,如果您變更命名空間,則新增一些 XSD 文件元素。
-
一些單元測試也會有很大幫助——總得有人來做。
-
如果沒有其他人在使用您的分支,請將其基於當前 master(或主要專案中的其他目標分支)進行 rebase。
-
在編寫提交訊息時,請遵循 這些慣例,如果您要修復現有的問題,請在提交訊息的末尾新增
Fixes gh-XXXX(其中 XXXX 是問題編號)。